MoS-TTS-Nano部署教程:0.1B超轻量TTS模型CPU即可运行
MoS-TTS-Nano是一个仅0.1B参数、纯CPU可运行的轻量级语音合成模型的完整部署教程。
本文介绍了MoS-TTS-Nano——一个仅有0.1B参数的极致轻量化TTS模型,无需GPU即可在普通四核CPU电脑上运行。文章详细记录了从环境搭建、Conda虚拟环境创建、pynini等关键依赖安装、模型下载到首次运行验证的完整部署流程,并逐一梳理了各环节常见报错及解决方案。实测表明该模型在语音克隆的音色还原和自然度方面表现超出预期。
为什么MoS-TTS-Nano值得关注
从 Spark TTS 到 Index TTS,语音生成领域近期涌现了大量优秀模型。但今天要介绍的 MoS-TTS-Nano,走了一条截然不同的路线——极致轻量化。
它的模型参数仅有 0.1B(1亿),硬件门槛低到令人意外:仅需一台四核 CPU 的普通电脑就能流畅运行,完全不需要 GPU。这背后依赖的是 ONNX(Open Neural Network Exchange) 格式——一种开放的神经网络交换标准,能让模型脱离 GPU 框架束缚,在 CPU 上高效推理。主流大模型如 VALL-E、SoundStorm 动辄数十亿参数,而 MoS-TTS-Nano 通过知识蒸馏和模型量化等技术,将能力压缩到极小规模,代表了 TTS 领域「效果与资源消耗」权衡的另一种解法。
对于手头没有高端显卡的开发者和语音技术爱好者来说,这是一个非常实用的选择。此外,MoS-TTS-Nano 还支持中文、英文等多语种语音生成,并内置了 Gradio WebUI 界面,上手门槛很低。
下面是一份经过实战验证的完整部署教程,把部署过程中踩过的坑和对应的解决方案都整理了出来。
环境准备:从零搭建MoS-TTS-Nano部署环境
克隆项目仓库
打开 VS Code(或你习惯的终端工具),执行以下命令将项目克隆到本地:
git clone <MoS-TTS-Nano项目地址>
克隆完成后,左侧文件资源管理器中就能看到完整的项目结构。
创建Conda虚拟环境
MoS-TTS-Nano 依赖 Conda 进行环境管理。Conda 与 pip 的核心区别在于,它不仅管理 Python 包,还能管理底层系统级依赖(如 C 库、CUDA 工具链等),能有效解决「依赖地狱」问题——即不同项目对同一库的不同版本产生冲突。先确认 Conda 是否已安装:
conda --version
确认后,创建一个独立的 Python 环境,指定 Python 3.12:
conda create -n mos-tts-nano python=3.12
创建完成后,通过 conda env list 查看所有环境,确认新环境已就绪。为每个项目创建独立环境是个好习惯,能有效避免不同项目之间的依赖冲突。
关键前置依赖:先装pynini
在激活环境之前,有一个容易踩坑的关键步骤——必须先安装 pynini:
conda install -c conda-forge pynini
为什么要单独提前装? pynini 是 Google 开发的有限状态转换器(FST)库,是 TTS 系统中文本规范化的核心工具——负责将「2024年」「¥100」「Dr.」等原始输入转换为可发音的形式,直接影响语音合成的准确性。由于 pynini 依赖底层 C++ 编译环境,用 pip 直接安装时在 Windows 或部分 Linux 系统上极易编译失败。conda-forge 是社区维护的第三方软件仓库,提供了预编译的二进制包,完全绕过编译环节,因此稳定性远高于 pip 安装方式。这是部署 MoS-TTS-Nano 过程中最常见的第一个坑。
装好 pynini 后,正式激活环境:
conda activate mos-tts-nano
终端提示符从 (base) 变为 (mos-tts-nano),说明环境切换成功。
依赖安装:常见报错与解决方案
常规安装与报错处理
进入项目目录(别忘了 cd mos-tts-nano),尝试常规安装依赖:
pip install -r requirements.txt
这一步大概率会报错,问题通常还是出在 pynini 相关的依赖链上。
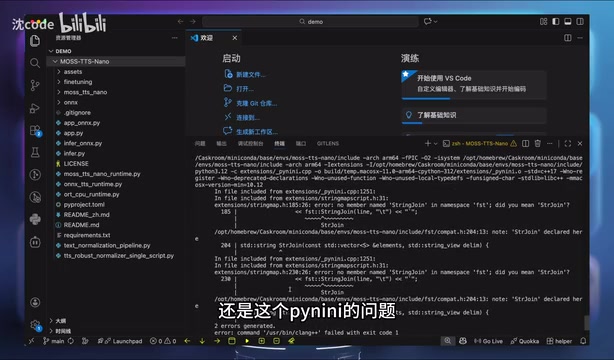
解决思路是:既然 pynini 已经通过 conda 装好了,就跳过它,单独安装剩余依赖和 vtext-processing:
# 使用排除pynini的方式安装依赖(具体命令参考项目文档)
pip install vtext-processing
最后,将当前项目以开发模式注册到环境中:
pip install -e .
⚠️ 注意:命令末尾有一个英文句点
.,代表当前目录,千万不要遗漏。-e参数表示「可编辑模式」安装,会将项目源码直接链接到 Python 环境中,方便后续修改代码时无需重新安装。
模型下载与首次运行验证
生成测试音频
环境搭建完成后,用 infer_onnx.py 脚本来验证 MoS-TTS-Nano 是否部署成功:
python infer_onnx.py --prompt_audio_path assets/audio/zh-1.wav --text "本地部署验证"
首次运行时,程序会自动从 Hugging Face 下载两个模型文件。 MoS-TTS-Nano 本身非常轻量,下载体积不大,但实际速度取决于你的网络环境。Hugging Face 是目前最主流的 AI 模型托管平台,国内访问有时不稳定,这也是下载卡住的主要原因。
如果下载过程中长时间卡住没有进度,可以按 Ctrl+C 中断,然后删除项目中的 models 文件夹,再重新执行命令:
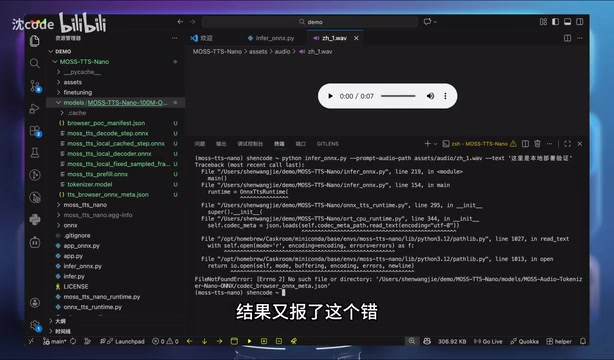
删除后重新运行,通常就能看到下载进度条正常推进了。
补充容易遗漏的依赖
模型下载完成后,可能还会碰到两个额外报错:
报错1:缺少 importlib-resources
pip install importlib-resources
报错2:缺少音频处理相关库
conda install -c conda-forge pysoundfile libsndfile
libsndfile 是底层 C 语言音频文件读写库,pysoundfile 是其 Python 封装,两者都需要通过 conda-forge 安装预编译版本才最为稳定。这两个依赖比较容易被忽略,建议提前装好以免反复折腾。
验证语音生成效果
所有依赖补齐后,再次执行生成命令,这次终于顺利跑通了。在项目的 generated_audio 文件夹中可以找到生成的音频文件。
实测效果:使用中文参考音频进行语音克隆,生成的音频在音色还原度和自然度方面表现都不错。语音克隆的核心原理是:说话人编码器从参考音频中提取声纹特征向量,合成网络将文本与声纹特征融合,最终由声码器(Vocoder)转换为可播放的音频波形。MoS-TTS-Nano 在 0.1B 参数规模下实现这一流程,可能采用了非自回归架构来平衡质量与推理速度。考虑到仅 0.1B 的参数量和纯 CPU 推理,这个效果确实超出预期。
Gradio WebUI可视化界面启动与使用
对于不习惯命令行的用户,MoS-TTS-Nano 内置了基于 Gradio 的 WebUI 界面。Gradio 是 Hugging Face 维护的开源 Python 库,专为机器学习模型快速构建交互式演示而设计——开发者只需几行代码即可将模型包装成 Web 应用,无需任何前端开发经验,已成为 AI 工具生态中事实上的演示标准。启
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。