大模型三大岗位深度解析:门槛、技术栈与职业前景

大模型三大核心岗位的技术要求、门槛差异与职业前景全面解析
文章系统梳理了大模型领域三大核心岗位:应用工程师(门槛最低,专注智能体和RAG开发,窗口期1-2年)、研发工程师(需掌握微调和推理优化,强需求3-5年)、算法工程师(要求985硕士+论文,黄金期10-20年)。同时指出合格开发者需掌握六种模型类型,企业级部署需使用vLLM等分布式推理框架而非Ollama,并建议根据自身定位选择匹配方向。
引言
随着国内大模型岗位的全面爆发,越来越多的开发者开始关注这一领域的职业机会。然而,市面上关于大模型岗位的信息鱼龙混杂,很多人对岗位要求、技术门槛和发展前景缺乏清晰认知。本文基于一位资深从业者的实战分享,系统梳理大模型领域的三大核心岗位,帮助你做出更明智的职业规划。
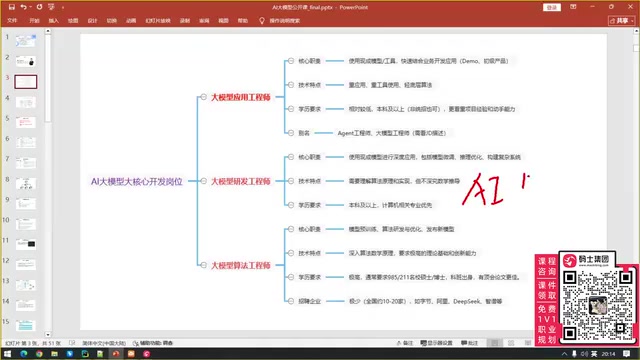
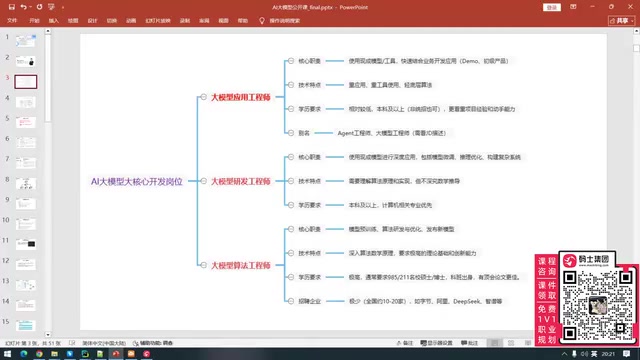
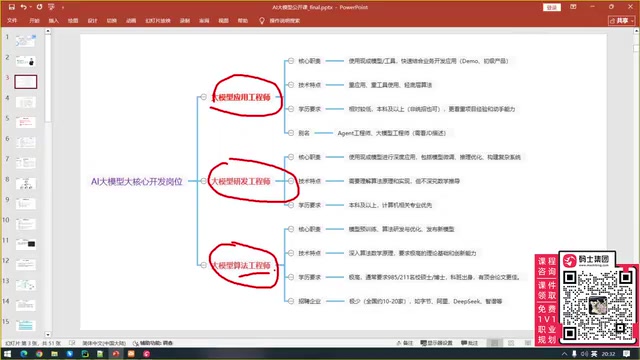
大模型三大核心岗位概览
经过对BOSS直聘、拉勾网等招聘平台的全面调研,当前与大模型相关的开发岗位可以归纳为三类:
- 大模型应用工程师:门槛最低,主要负责智能体开发、RAG构建、工作流搭建
- 大模型研发工程师:中等门槛,包含应用工程师的全部能力,额外需要模型微调和推理优化
- 大模型算法工程师:门槛最高,最低要求985硕士+顶级期刊论文
需要特别注意的是,招聘平台上的岗位名称并不规范。有些标注为"大模型工程师"的岗位实际是应用工程师,有些写着"大模型研发工程师"的实际是算法工程师。关键要看岗位职责描述和技术要求,而非岗位名称。
各岗位技术栈详解
大模型应用工程师
这是入门门槛最低的岗位,学历要求最低为本科。核心技术栈包括:
- 低代码平台工具:Dify、Coze、Cosor、RGFlow、N8N等
- 开发框架:LangGraph、Streamlit等
- 核心能力:不需要学习AI算法,重点是会使用各类大模型构建智能体和RAG系统
低代码平台在实际工作中的价值在于快速验证——当领导或甲方要求三天内看到智能体效果时,通过拖拽方式快速搭建原型是必备技能。但这类工具存在响应速度慢、并发能力不足、数据安全性差等问题,不适合生产环境。
RAG技术背景:RAG(Retrieval-Augmented Generation,检索增强生成)是一种将外部知识库与大语言模型结合的技术架构。其核心思路是:在模型生成回答之前,先从外部向量数据库中检索与问题相关的文档片段,再将这些片段作为上下文注入到提示词中,从而让模型基于最新、最准确的信息进行回答。RAG有效缓解了大模型"知识截止日期"和"幻觉"两大痛点,是当前企业落地AI应用最主流的技术路线之一。向量化后的数据通常存储在Milvus、Weaviate、Chroma等向量数据库中,支持高效的近似最近邻(ANN)检索,构成了智能体知识库的底层基础设施。
大模型研发工程师
这个岗位完全包含应用工程师的能力要求,同时还需要:
- 机器学习算法、深度学习算法(不需要极深,但必须掌握)
- PyTorch、TensorFlow等框架
- HuggingFace生态(各种模型库、推理框架)
- 模型微调技术(LoRA、QLoRA等微调算法)
- 强化学习、MOE预训练等进阶知识
- 将大模型与传统AI模型(如YOLO目标检测)对接的能力
LoRA与QLoRA微调技术背景:LoRA(Low-Rank Adaptation)是一种参数高效微调方法,由微软研究院于2021年提出。其核心思想是:冻结预训练模型的原始权重,仅在特定层注入低秩矩阵进行训练,大幅降低了微调所需的显存和计算资源。QLoRA则是在LoRA基础上引入4-bit量化技术,使得在单张消费级GPU(如RTX 3090)上微调70亿参数级别的模型成为可能。这两种技术的出现,极大降低了企业私有化部署和定制化模型的门槛,也是大模型研发工程师区别于应用工程师的核心竞争力所在。
MoE架构背景:MoE(Mixture of Experts,混合专家模型)是一种稀疏激活的神经网络架构。与传统密集模型每次推理都激活全部参数不同,MoE模型由多个"专家"子网络组成,每次推理仅由门控网络(Gating Network)动态选择少数几个专家参与计算。这使得模型可以在参数总量极大的同时,保持较低的单次推理计算量。DeepSeek-V3、Mixtral等顶级模型均采用MoE架构,实现了参数规模与推理效率的兼顾。理解MoE预训练原理是大模型研发工程师的进阶必备知识。
大模型算法工程师
要求最高、薪资也最高的岗位。必须深入掌握算法的数学推导过程,甚至需要了解底层数学原理和C++/CUDA级别的优化实现。目前全国大约有20家公司在高薪招聘或挖人,包括阿里、DeepSeek、月之暗面、智谱、华为、小红书等。
大模型开发者至少需要掌握六种模型
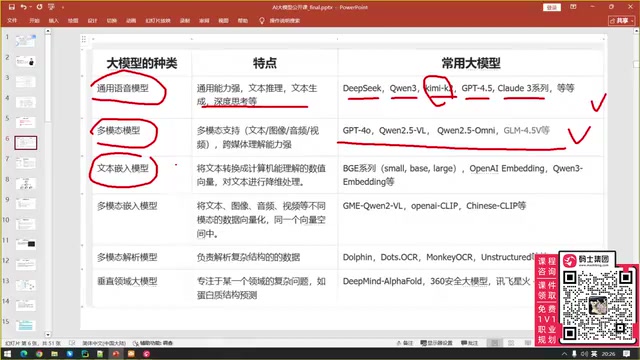
很多人以为"会用DeepSeek"就等于会大模型,这是严重的误解。作为大模型开发者,至少需要掌握以下六种模型类型:
- 通用语言模型:DeepSeek、Qwen、K2、GPT-4.5、Claude 3等,用于文本理解和逻辑推理
- 多模态模型:处理图像、音频、视频等多种数据类型
- 文本嵌入模型:BGE、OpenAI Embedding、Qwen Embedding等,对文本进行降维处理
- 多模态嵌入模型:对图像、音频、视频进行向量化处理(Qwen、OpenAI、智谱均有提供)
- 多模态解析模型:Docling、Dotter OCR(字节)、MinerU OCR(小红书)等,专门解析复杂非结构化数据
- 垂直领域大模型:针对特定行业的专用模型
文本嵌入模型与向量数据库背景:文本嵌入模型(Embedding Model)的作用是将自然语言文本转化为高维向量空间中的数值表示,使得语义相近的文本在向量空间中距离更近。这一过程本质上是一种"语义编码",是RAG系统、语义搜索、推荐系统的底层基础设施。BGE(BAAI General Embedding)是由北京智源人工智能研究院开源的中文嵌入模型,在中文语义理解任务上表现优异,被广泛应用于国内企业的知识库检索场景。值得注意的是,嵌入模型与生成模型是两个完全不同的技术方向,前者输出的是向量而非文本,初学者容易混淆。
所谓"会"一个模型,不仅是会调用API,更要知道如何做推理部署和微调训练。
企业级推理框架:为什么不能只用Ollama
很多人用过Ollama来本地运行模型,但Ollama不支持分布式部署,无法满足企业级并发需求。真正的企业级推理框架包括:
- vLLM
- SGLang
- HuggingFace Transformers系列库
- 以及其他支持分布式的推理引擎
Ollama的本质是一个包含推理框架的工具,它不仅做模型推理,还对外提供Web服务和API接口。但当公司300人同时使用时,不支持分布式的Ollama就完全不够用了。
vLLM与SGLang推理框架背景:vLLM是由UC Berkeley开发的高吞吐量大模型推理引擎,其核心创新是PagedAttention技术——借鉴操作系统虚拟内存的分页管理思想,对KV Cache(键值缓存)进行动态分配,显著提升了GPU显存利用率和并发吞吐量,相比原生HuggingFace推理可提升数倍至数十倍的服务吞吐性能。SGLang(Structured Generation Language)则由斯坦福团队开发,专注于结构化输出和复杂推理链的高效执行,在需要JSON格式输出或多轮对话的场景下表现尤为突出。两者均支持多GPU张量并行和多节点分布式部署,是当前企业级大模型推理服务的主流选择,也是大模型研发工程师必须熟练掌握的核心工具链。
岗位前景与生命周期预判
大模型算法工程师:10-20年黄金期
当前AI大模型几乎每三个月更新一个版本(Qwen 2.5→3、DeepSeek V3→V3.1、GPT 4→4.5→5.0、Claude 3→3.5→3.7),全球最顶尖的人才和资金都在涌入这个方向。这是人类社会发展的下一个确定性方向,无年龄限制。
大模型研发工程师:3-5年强需求
大模型的"幻觉"问题短期内不会彻底解决。要将模型正确率从70%-80%提升到95%以上,需要研发工程师持续做推理优化和微调。这个岗位在未来3-5年内都会保持强劲需求。
大模型幻觉问题背景:大模型"幻觉"(Hallucination)是指模型生成看似合理但实际上不准确、甚至完全捏造的内容。其根本原因在于语言模型的训练目标是预测下一个token的概率分布,而非保证事实准确性——模型本质上是在做"统计意义上的合理续写",而非"事实核查"。幻觉问题在医疗、法律、金融等高精度要求场景中尤为致命。当前缓解幻觉的主要技术路径包括:RAG(引入外部知识接地)、RLHF(基于人类反馈的强化学习)、思维链提示(Chain-of-Thought)、领域专项微调以及推理时的自我一致性校验(Self-Consistency)等。但业界普遍认为,在现有Transformer架构下,幻觉问题难以从根本上消除,这正是研发工程师岗位长期存在强劲需求的核心技术根源。
大模型应用工程师:1-2年窗口期
由于技术门槛相对较低,预计短期内不会内卷,但之后可能进入竞争激烈阶段,类似当年安卓/iOS开发的发展轨迹。
关于工作经验的建议
由于大模型岗位在国内真正爆发是从近期开始,简历上的大模型工作经验不要超过一年。写两三年经验反而会引起面试官怀疑——此前国内大模型推理成本极高,只有少数大公司在做,面试官一定会追问具体公司和项目细节。
总结
无论你是哪个技术方向的开发者,大模型已经成为不可回避的技术趋势。即便不转型做专职大模型工程师,掌握基本的大模型应用能力也已成为各岗位的加分项。关键是认清自己的定位,选择匹配的岗位方向,制定合理的学习路径,而不是被碎片化信息误导。
核心要点
- 大模型开发岗位分为应用工程师、研发工程师、算法工程师三类,门槛和薪资依次递增
- 合格的大模型开发者至少需要掌握六种模型类型,而非仅会调用API
- 企业级推理框架(vLLM、SGLang等)与个人工具(Ollama)有本质区别,分布式能力与PagedAttention等核心技术是关键
- 三大岗位的生命周期预判:算法工程师10-20年、研发工程师3-5年、应用工程师1-2年窗口期
- 大模型幻觉问题源于Transformer架构的统计预测本质,短期内无法彻底解决,这恰恰是研发工程师岗位持续需求的根本原因
相关推荐
 行业洞察
行业洞察AI产品开发实战:模型选择、护城河构建与商业化路径
分享AI产品开发的实战策略,包括为什么不应从头训练模型、如何选择API调用与微调时机、构建产品护城河的关键要素,以及从评测体系搭建到商业化落地的完整执行路径。
 行业洞察
行业洞察没有想要的产品?自己做才是独立开发者的最佳起点
市面上找不到满意的产品怎么办?从个人痛点出发,自己动手开发,正是独立开发者最好的切入方式。本文分析为什么小众需求反而是理想的创业起点,以及AI工具如何让一个人也能快速把想法变成产品。
 行业洞察
行业洞察OpenAI Codex教程遭批量搬运,AI内容农场现象引关注
B站上至少9个账号批量发布相同的OpenAI Codex教程视频,暴露AI工具教程领域的内容农场问题。本文分析批量搬运的典型特征,探讨平台治理挑战,并提供辨别原创内容的实用建议。