AI大模型全套学习路线解析:从入门到实战完整指南

大模型学习为何需要系统化?
随着大模型技术的快速发展,越来越多的人希望入门这一领域。然而,B站上虽然已有大量相关教程,从几十播放到百万播放不等,但普遍存在一个问题:不够系统、不够完整。许多教程要么只讲理论不讲实操,要么零散地覆盖某个知识点,缺乏从入门到精通的完整路径。

近期B站上出现了一套号称"全749集"的大模型系统教程,声称历时三个月制作,覆盖基础、进阶、实战三大阶段。抛开营销话术不谈,这套课程的知识体系架构确实值得我们拆解分析——即便你不打算跟着学,了解一套完整的大模型学习路线图本身就很有价值。
基础篇:从零建立大模型认知体系
根据课程介绍,基础阶段主要覆盖以下几个核心模块:
- 大模型基础认知:理解什么是大语言模型、它的能力边界和应用场景
- AI开发环境搭建:Python环境配置、相关库安装等基础准备工作
- Transformer核心架构:这是所有现代大模型的基石,理解注意力机制、编码器-解码器结构
- 提示词工程(Prompt Engineering):学会如何与大模型高效对话
- API调用:掌握OpenAI、国内各大模型的API接口使用

这个基础阶段的设计思路是合理的。对于零基础学习者来说,Transformer架构的理解是一个分水岭——很多人在这里就被劝退了。如果能用通俗易懂的方式讲清楚自注意力机制和位置编码等概念,确实能帮助初学者少走不少弯路。
Transformer架构由Google团队在2017年的里程碑论文《Attention Is All You Need》中首次提出,最初是为机器翻译任务设计的。它彻底摒弃了此前主流的循环神经网络(RNN)和长短期记忆网络(LSTM)的序列处理方式,转而完全依赖注意力机制来捕捉输入序列中任意两个位置之间的依赖关系。这种并行化的设计不仅大幅提升了训练效率,还使模型能够更好地处理长距离依赖问题。自注意力机制(Self-Attention)是其核心组件,它让序列中的每个元素都能"关注"到其他所有元素,并根据相关性动态分配权重。位置编码(Positional Encoding)则弥补了Transformer缺乏序列顺序感知的不足,通过正弦余弦函数或可学习的嵌入向量为每个位置赋予独特的标识。后来的GPT系列采用了仅解码器(Decoder-only)架构,BERT采用了仅编码器(Encoder-only)架构,而T5等模型则保留了完整的编码器-解码器结构——理解这些变体之间的区别,是深入学习大模型的重要基础。
提示词工程的重要性
值得一提的是,提示词工程被放在基础篇而非进阶篇,这个安排是正确的。在实际工作中,绝大多数人与大模型的交互都是通过提示词完成的。掌握好提示词工程,即便不写一行代码,也能极大提升工作效率。
提示词工程(Prompt Engineering)是一门研究如何设计和优化输入提示以引导大模型产生期望输出的系统性技术。它的核心理念是:大模型的输出质量在很大程度上取决于输入的质量和结构。常见的提示词技术包括:零样本提示(Zero-shot)直接描述任务让模型完成;少样本提示(Few-shot)通过提供若干示例来引导模型理解任务模式;思维链提示(Chain-of-Thought, CoT)要求模型逐步推理以提升复杂问题的准确率;以及更前沿的思维树(Tree-of-Thought)和自我一致性(Self-Consistency)等高级策略。OpenAI、Anthropic等公司都发布了官方的提示词最佳实践指南,涵盖角色设定、任务分解、输出格式约束等维度。在企业场景中,提示词工程师已经成为一个新兴岗位,负责为特定业务场景设计和迭代提示词模板,这也说明了为什么将其放在基础阶段学习是明智之举。
进阶篇:RAG、Agent与微调三大核心技术栈
进阶阶段聚焦于三个关键方向:RAG(检索增强生成)、Agent(智能体)和模型微调。
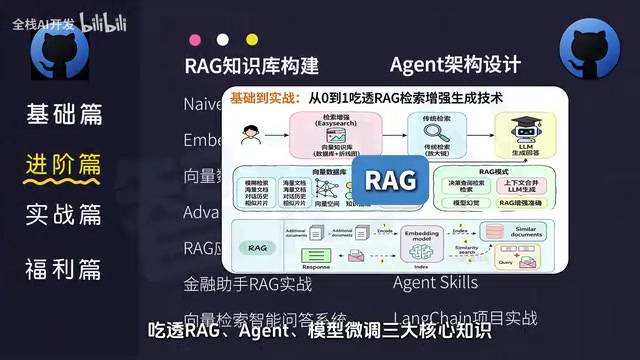
RAG:让大模型拥有专属知识库
RAG技术是当前企业落地大模型应用最主流的方案之一。它通过将外部知识库与大模型结合,解决了大模型"幻觉"和知识时效性的问题。学习RAG需要掌握向量数据库、文档切分、Embedding模型等一系列技术。
这里有必要解释一下大模型"幻觉"(Hallucination)这个概念——它是指模型生成看似合理但实际上不正确或完全虚构的内容。这是大语言模型的一个固有缺陷,根源在于模型的训练目标是预测下一个最可能的token,而非验证事实的准确性。幻觉问题在医疗、法律、金融等对准确性要求极高的领域尤为危险,这也正是RAG技术诞生的重要背景。
RAG(Retrieval-Augmented Generation)最早由Meta AI在2020年提出,其核心思想是在大模型生成回答之前,先从外部知识库中检索相关信息,然后将检索到的内容作为上下文注入提示词中,让模型基于这些真实信息生成回答。这一技术栈涉及多个关键组件:首先是文档处理与切分(Chunking),需要将长文档按语义或固定长度切分为适合检索的片段;其次是Embedding模型(如OpenAI的text-embedding-ada-002、开源的BGE系列等),将文本转换为高维向量表示;然后是向量数据库(如Milvus、Pinecone、Chroma、Weaviate等),用于高效存储和检索这些向量;最后还有重排序(Reranking)和上下文压缩等优化环节。RAG相比模型微调的优势在于:无需重新训练模型、知识可实时更新、可追溯信息来源、成本更低。当前业界还在探索GraphRAG(基于知识图谱的RAG)、Agentic RAG(结合Agent的自适应RAG)等进阶方案,这些都是值得持续关注的技术演进方向。
Agent:赋予大模型执行能力
Agent让大模型不再只是"聊天机器人",而是能够调用工具、执行任务、进行多步推理的智能体。这是当前最火热的技术方向之一,也是未来AI应用的核心形态。
AI Agent(智能体)的概念源自人工智能的经典理论,但在大模型时代被赋予了全新的含义。现代AI Agent以大语言模型作为"大脑",具备感知环境、自主决策、调用工具和执行行动的能力。其核心架构通常包含四个模块:规划(Planning)——将复杂任务分解为可执行的子步骤;记忆(Memory)——包括短期的对话上下文和长期的经验存储;工具使用(Tool Use)——调用搜索引擎、代码执行器、数据库查询等外部工具;行动(Action)——执行具体操作并观察结果。2023年以来,AutoGPT、BabyAGI等开源项目引爆了Agent热潮,而OpenAI的Function Calling、Anthropic的Tool Use等能力则为Agent开发提供了标准化接口。多Agent协作(Multi-Agent)是当前的前沿方向,多个具有不同角色和能力的Agent可以协同完成复杂任务,微软的AutoGen和CrewAI等框架正在推动这一范式的发展。
模型微调:打造垂直领域专属模型
当通用大模型无法满足特定场景需求时,微调就成了必要手段。课程中提到会涉及主流框架如LangChain和LangGraph的使用,这两个框架确实是当前大模型应用开发的事实标准。
模型微调(Fine-tuning)是指在预训练大模型的基础上,使用特定领域或任务的数据进行进一步训练,使模型在该领域表现更优。当前主流的微调方法已从全参数微调转向参数高效微调(PEFT),其中最具代表性的是LoRA(Low-Rank Adaptation),它通过在模型权重矩阵中注入低秩分解矩阵来实现高效微调,仅需训练原模型0.1%-1%的参数量,大幅降低了计算资源需求。QLoRA则进一步结合了4-bit量化技术,使得在消费级GPU上微调70亿甚至130亿参数的模型成为可能,这对个人开发者和中小企业来说意义重大。
关于开发框架,LangChain是当前最流行的大模型应用开发框架,它提供了链(Chain)、代理(Agent)、记忆(Memory)、检索(Retrieval)等模块化组件,极大简化了RAG和Agent应用的开发流程。LangGraph则是LangChain团队推出的进阶框架,基于有向图的理念来编排复杂的多步骤AI工作流,支持循环、条件分支和状态管理,特别适合构建复杂的Agent系统和多轮交互应用。掌握这两个框架,基本上就具备了开发主流大模型应用的技术能力。
实战篇:贴合企业需求的项目实操
实战阶段是检验学习成果的关键环节。课程列出了几个典型项目:
- 企业RAG知识库搭建:最常见的企业级应用场景
- AI智能客服:结合RAG和对话管理的综合项目
- AI医疗问答系统:垂直领域的专业应用
- Agent数字人:融合多模态技术的前沿项目

这些项目选择覆盖了当前市场上最主流的大模型应用方向。特别是企业RAG知识库和AI智能客服,几乎是每家接入大模型的企业都会优先考虑的场景,具有很强的实用价值和求职竞争力。据多家咨询机构的报告显示,RAG知识库和智能客服是目前企业大模型落地渗透率最高的两个场景,前者能够将企业内部海量的文档、手册、规章制度转化为可即时查询的智能知识系统,后者则能显著降低客服人力成本并提升响应速度和一致性。AI医疗问答系统则代表了垂直领域应用的典型挑战——需要处理专业术语、确保回答的准确性和安全性,并符合医疗行业的合规要求。Agent数字人项目则融合了大语言模型、语音合成(TTS)、语音识别(ASR)甚至数字人形象生成等多模态技术,是技术综合度最高的实战项目。
理性看待:学习建议与注意事项
虽然这套课程的知识体系看起来比较完整,但我们也需要保持理性:
第一,749集的体量需要大量时间投入。 学习者需要评估自己的时间和精力,制定合理的学习计划,而不是盲目收藏后吃灰。
第二,大模型技术迭代极快。 部分内容可能很快就会过时。学习时应注重理解底层原理,而非死记硬背特定工具的用法。以2024年为例,从GPT-4 Turbo到Claude 3.5再到开源的Llama 3.1和Qwen 2.5,模型能力的跃升速度远超预期,与之配套的工具链和最佳实践也在持续演变。因此,建立扎实的基础理论认知(如Transformer原理、注意力机制、训练范式等)比掌握某个特定版本的API更具长期价值。
第三,实践永远大于理论。 看完教程只是第一步,真正的能力提升来自于动手做项目、踩坑、解决问题的过程。建议每学完一个模块就立即动手实践。
第四,免费资源需辨别质量。 B站免费教程的优势是零成本,但也要注意甄别内容质量,必要时可以交叉参考多个来源的教程和官方文档。建议同时关注各大模型厂商的官方文档(如OpenAI Cookbook、LangChain官方文档)、arXiv上的最新论文、以及GitHub上的优质开源项目,形成多维度的学习资源矩阵。
总结
从知识架构来看,这套课程覆盖了大模型学习从入门到实战的完整路径,"基础→进阶→实战"的三段式结构也符合技术学习的一般规律。对于想要系统学习大模型的初学者来说,至少可以作为一份不错的学习路线参考。但最终能否学有所成,关键还是在于学习者自身的执行力和持续投入。
相关推荐

别再手写Prompt了:让AI代理自己提示自己
深度解析AI编程范式转变:从手动编写Prompt到构建代理自提示循环系统。了解如何通过代理自审代码、主动获取上下文等方法,实现规模化高质量AI编程,从Prompt工程师进阶为代理系统设计师。

SpaceX收购Cursor背后:马斯克600亿美元的真正野心
SpaceX以600亿美元全股票方式收购Cursor母公司Anysphere,马斯克看中的不只是代码编辑器,而是AI驱动的软件生产线入口和真实工作流数据。深度解析这笔交易的战略逻辑、潜在风险与AI编程赛道格局。
Cursor实战:15分钟开发图书馆管理系统全流程
详解使用Cursor AI编程工具15分钟开发FastAPI+Vue3图书馆借阅管理系统的完整流程,包括结构化提示词设计、Plan与Build分步策略、Bug修复技巧及实践经验总结。