Claude 4.6 vs GPT-5.1 vs DeepSeek-R1编程能力实测对比

三大编程AI模型巅峰横评
AI编程领域已形成三足鼎立的格局:Anthropic的Claude Sonnet 4.6、OpenAI的GPT-5.1 Codex以及国产推理之光DeepSeek-R1。这三款模型代表了当前AI辅助编程的最高水平,但它们各自的定位和优势截然不同。
本文将从API使用价格、规格参数以及真实软件工程基准测试SWE-Bench两个核心维度,对这三款模型进行全方位拆解分析。

规格与价格对比:成本差距有多大?
API定价差异悬殊
三款模型均支持超长上下文窗口,但在API定价策略上呈现出巨大差异。在理解这些价格之前,有必要了解Token这一核心计量单位——Token是大语言模型处理文本的基本单元,一个token大约对应英文中的3/4个单词,或中文中的1-2个汉字。在实际编程场景中,由于需要将大量代码上下文作为输入传递给模型,输入token的消耗量往往远超输出。例如,一个中等规模的代码仓库可能包含数十万行代码,仅一次完整的代码审查请求就可能消耗数万甚至数十万token,因此输入价格的差异在大规模工程应用中会被急剧放大。
- DeepSeek-R1:输入价格仅0.55美元/百万token
- GPT-5.1 Codex:输入价格1.25美元/百万token
- Claude Sonnet 4.6:输入价格3美元/百万token
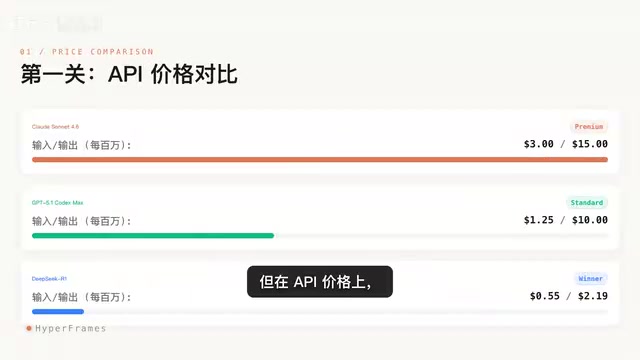
从价格维度来看,DeepSeek-R1相比Claude Sonnet 4.6节省超过80%的成本,相比GPT-5.1 Codex也便宜了56%以上。对于需要大规模调用API的企业级应用场景,这种价格差距意味着数量级的成本差异。
上下文窗口:决定模型"视野"的关键参数
上下文窗口(Context Window)是指模型在单次推理中能够处理的最大token数量。对于编程任务而言,上下文窗口的大小直接决定了模型能够"看到"多少代码。早期模型(如GPT-3.5)仅支持4K token的上下文,这意味着模型只能处理约200行代码,面对跨文件依赖关系时几乎无能为力。当前三款模型均支持超长上下文(通常在128K-200K token范围),这使得模型能够同时理解整个模块甚至小型项目的完整代码结构,从而在代码补全、bug定位和重构建议等任务中表现出质的飞跃。
性价比分析
对于初创团队和个人开发者而言,DeepSeek-R1的极致性价比无疑具有巨大吸引力。但价格并非唯一考量因素——真正决定生产力的是模型在实际编程任务中的表现。
在企业级部署场景中,AI编程助手的成本计算远不止API调用费用。还需要考虑:延迟与吞吐量——高并发场景下的响应速度直接影响开发者体验;数据隐私——部分企业要求代码不离开内网,这时DeepSeek-R1的开源特性允许私有化部署,而Claude和GPT则主要依赖云端API;模型一致性——频繁的模型更新可能导致输出行为变化,影响CI/CD流水线的稳定性。因此,"最佳选择"往往取决于企业的具体技术栈、安全合规要求和团队规模等综合因素。
SWE-Bench Verified实战能力测试
什么是SWE-Bench?
SWE-Bench Verified是目前业界公认的衡量AI模型解决真实GitHub软件工程问题能力的权威基准测试。它由普林斯顿大学研究团队于2023年推出,核心思路是从GitHub上12个主流Python开源项目(包括Django、Flask、scikit-learn、sympy等)中提取真实的Issue和对应的Pull Request。每个测试用例要求模型在给定问题描述的情况下,自主定位需要修改的文件和代码行,并生成能够通过项目原有测试套件的补丁。"Verified"版本是经过人工审核确认的高质量子集,排除了描述模糊或测试不充分的用例,共包含500个经过验证的任务实例。这种基于真实软件工程场景的评测方式,比传统的代码补全基准(如HumanEval仅测试独立函数的正确性)更能反映模型在实际开发中的可用性。
解决率排名
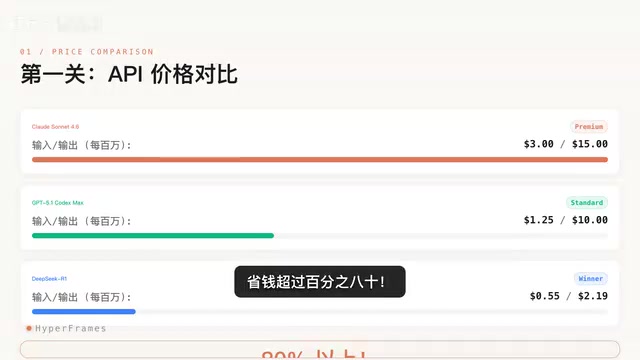
测试结果令人瞩目:
| 模型 | SWE-Bench Verified解决率 |
|---|---|
| Claude Sonnet 4.6 | 79.6% |
| GPT-5.1 Codex | 76.3% |
| DeepSeek-R1 | 49.2% |
Claude Sonnet 4.6以79.6%的解决率夺得榜首,展现了Anthropic在代码生成和工程理解方面的深厚积累。GPT-5.1 Codex以76.3%紧随其后,两者差距仅3.3个百分点,竞争异常激烈。
而DeepSeek-R1的49.2%虽然与前两者存在明显差距,但考虑到其不到前者五分之一的价格,这一表现仍然值得肯定。
差距背后的原因:推理模型与代码专项模型的本质区别
Claude Sonnet 4.6和GPT-5.1 Codex在工程能力上的领先,很可能源于它们在训练过程中对大规模代码仓库的深度优化,以及对软件工程工作流(如代码审查、测试驱动开发等)的专项强化。
DeepSeek-R1作为通用推理模型,其核心优势在于逻辑推理而非专项的代码工程能力。具体而言,DeepSeek-R1属于"推理增强型"模型,其核心设计理念是通过Chain-of-Thought(思维链)机制进行多步逻辑推理,在数学证明、逻辑分析等任务中表现卓越。这类模型在推理过程中会生成大量中间思考步骤,虽然提升了推理准确性,但也增加了token消耗。相比之下,Claude Sonnet 4.6和GPT-5.1 Codex更侧重于对软件工程范式的理解——包括设计模式识别、API调用约定、测试用例生成以及跨文件依赖分析等。这种架构层面的差异解释了为何DeepSeek-R1在需要精确代码工程能力的SWE-Bench上表现不及前两者,但在涉及算法设计和逻辑推导的编程任务中可能展现独特优势。
值得一提的是,测试驱动开发(TDD)的理念已被深度融入AI编程模型的训练和评估流程中。SWE-Bench的评判标准本质上就是TDD思想的体现——模型生成的代码补丁必须通过预设的测试套件才算成功。Claude和GPT系列模型在训练中大量接触了包含测试代码的仓库数据,使其能够理解"代码修改应满足什么约束"这一工程概念。这也是为什么在实际使用中,向这些模型提供测试用例作为上下文,往往能显著提升代码生成的准确性。
综合实力排行与选择建议

最终排名
- Claude Sonnet 4.6 — 最强工程开发能力,适合追求代码质量和复杂项目开发的专业团队
- GPT-5.1 Codex — 综合实力均衡,性能接近Claude但价格更优
- DeepSeek-R1 — 极致性价比加上强大推理能力,适合预算有限但需求量大的场景
不同场景如何选择?
- 预算充足、追求极致代码质量:选Claude Sonnet 4.6
- 平衡性能与成本:选GPT-5.1 Codex
- 成本敏感、大规模调用:选DeepSeek-R1
- 复杂逻辑推理+编程:DeepSeek-R1的推理链能力可能带来独特优势
- 数据隐私与私有化部署:DeepSeek-R1的开源特性使其成为唯一支持完全本地化部署的选项,对于金融、医疗等对数据合规要求严格的行业尤为重要
总结
AI编程赛道已经进入白热化竞争阶段。Claude Sonnet 4.6在纯工程能力上暂时领先,但GPT-5.1 Codex紧追不舍,而DeepSeek-R1则用不到五分之一的价格提供了可观的编程能力,为市场带来了差异化选择。对于开发者而言,没有绝对的"最强",只有最适合自身需求和预算的选择。
随着模型迭代速度的加快,这一格局随时可能被打破。建议开发者关注各厂商的更新动态,并在实际项目中进行小规模A/B测试,用真实的开发效率数据来指导最终的技术选型决策。
核心要点
相关推荐
OpenCode深度评测:免费开源AI编程助手实战体验
深度评测OpenCode开源AI编程助手,涵盖三层架构解析、安装配置、实战构建待办事项应用全过程,对比DeepSeek Flash等模型表现,帮助开发者了解这款支持75+LLM提供商的免费Cursor替代方案。

Wayfair如何用GPT模型处理4000万商品目录
深度解析Wayfair如何利用OpenAI GPT模型对4000万SKU进行目录enrichment,涵盖技术实现、非标品分类难题的AI解法,以及对电商行业商品数据管理的启示。
Codex编程智能体全解析:和ChatGPT到底有什么区别?
深入解析OpenAI Codex编程智能体的核心能力,对比Codex与ChatGPT在编程场景中的本质区别,帮助开发者理解AI编程智能体如何改变软件开发模式。