氛围编程工具对比评测:Base44、Replit、Bolt、Lovable谁最强?
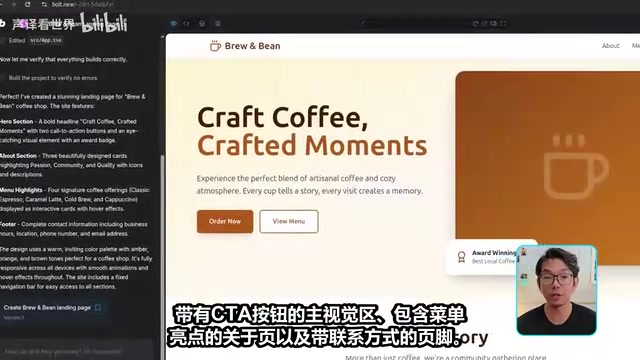
四款氛围编程工具72小时实测对比,仅一款能真正做到构建一切。
一位创作者用72小时对Base44、Replit、Bolt和Lovable四款氛围编程平台进行系统测试,采用一次性提示规则,从速度、错误管理、功能性和创造力四维度评分。结果显示:Lovable速度快但核心功能缺失(44分),Bolt稳定但设计平庸且易误解需求(53分),各平台因底层技术架构差异表现各异。
引言:氛围编程工具该怎么选?
氛围编程(Vibe Coding)正在成为2026年最热门的开发方式之一——通过自然语言提示,让AI自动生成完整的应用程序。这一概念最初由OpenAI联合创始人Andrej Karpathy于2025年初提出,指开发者通过自然语言描述意图,完全依赖大型语言模型(LLM)生成代码,而非手动编写。与传统的AI辅助编程(如GitHub Copilot的逐行补全)不同,氛围编程追求的是"零代码干预"的完整应用交付,本质上是将软件开发的认知负担从"如何实现"转移到"想要什么"。这一范式的兴起得益于GPT-4、Claude等模型在代码生成能力上的飞跃——这些模型在数十亿行开源代码上训练,能够理解从UI布局到后端逻辑的完整开发意图。
但面对市场上琳琅满目的工具,开发者该如何选择?
一位创作者花了72小时,对四款主流氛围编程平台——Base44、Replit、Bolt和Lovable——进行了系统性的正面对决测试。每个平台需要完成8个不同类别的构建任务(网站、游戏、Web应用、平台复刻),涵盖简单和复杂两个难度级别,并以速度、错误管理、功能性和创造力四个维度进行评分。
结果令人意外:只有一款工具能真正做到"构建一切"。
测试方法论:公平的一次性构建
为确保比较的公正性,测试采用了严格的"一次性提示"规则。"一次性提示"(Single-Shot Prompting)是评估LLM能力的经典方法论,源自学术界对模型零样本(Zero-Shot)推理能力的研究。在实际工程场景中,开发者通常会通过多轮对话(Multi-turn Conversation)迭代优化输出,这与测试方法存在差距。然而,一次性测试的价值在于揭示平台的"基础能力下限"——即在没有人工干预的情况下,工具能独立完成多少工作。这对于评估工具是否适合非技术用户(他们往往不具备通过追加提示修复错误的能力)尤为关键。
具体规则如下:
- 相同提示词:每个平台接收完全相同的构建请求
- 不进行人工修复:如果输出失败,不会通过额外提示进行补救
- 四维评分体系:速度(生成时间)、错误管理(自动检测与修复能力)、功能性(核心功能是否可用)、创造力(设计质量与视觉精致度)
这种方法论模拟了真实用户的使用场景——你给工具一个需求,看它第一次能交出什么样的成果。测试结果中Bolt"误解需求"的现象,在技术层面反映的是模型对提示词的语义歧义处理策略差异,而非单纯的能力不足,这也印证了一次性测试方法在揭示平台真实能力边界上的独特价值。
四款工具的技术架构背景
在深入各平台评测之前,有必要了解它们在底层技术栈上的显著差异,这直接影响了测试结果。Replit是最早的云端IDE之一,其AI功能(Replit Agent)构建在完整的Linux容器环境上,支持任意语言和框架,这解释了其功能强大但速度较慢的特点——完整的环境初始化和依赖安装本身就需要时间。Bolt基于StackBlitz的WebContainers技术,在浏览器内运行Node.js环境,实现了极快的启动速度但牺牲了部分系统级能力。Lovable专注于React/TypeScript的前端生成,与Supabase有深度集成但后端配置需要额外操作。这些架构选择背后是不同的产品定位:从"完整开发环境"到"快速原型工具"的光谱分布,决定了各平台在功能完整性与易用性之间的权衡取舍。
Lovable评测:速度快但功能缺失,总分44/100
生成速度表现不错
Lovable在速度方面表现不错,大多数构建在3-5分钟内完成。生成过程通常顺畅,很少报告错误。
致命弱点:核心功能无法运行
然而,Lovable的最大问题在于功能性。SEO分析器的核心功能完全无法运行,看板应用甚至无法完成生成。在游戏测试中,FPS游戏的子弹不显示、光线极暗。平台复刻虽然视觉上接近原版,但所有内容都是静态占位符,没有任何后端逻辑。
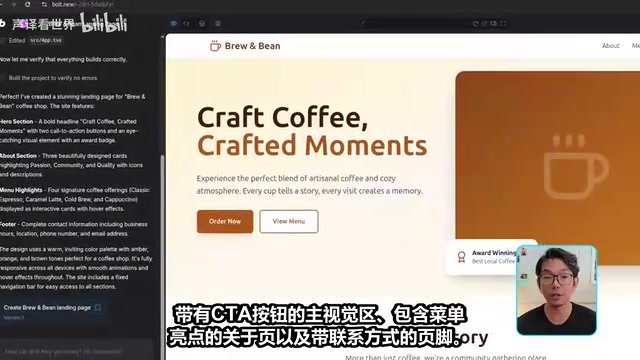
这一结果与Lovable的技术定位高度吻合——其核心优势在于React组件的快速渲染,而非全栈应用的完整交付。简而言之,Lovable适合快速制作前端原型或视觉模型,但在需要真实功能的场景下严重力不从心。
Bolt评测:稳定但设计平庸,总分53/100
零错误的构建稳定性
Bolt在全部8次构建中没有出现任何生成错误,是构建过程中最稳定的平台。看板应用和FPS游戏都能正常运行,证明它能处理结构化逻辑。这种稳定性得益于WebContainers技术的沙箱隔离特性,能够在浏览器环境中可靠地执行Node.js代码而不受外部环境干扰。
短板:视觉粗糙且容易误解需求
Bolt的创造力是所有平台中最弱的。输出缺少占位图片和视觉细节,落地页看起来更像线框图。更关键的是,在平台复刻测试中,Bolt"误解
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。