5大模型Coding实战横评:Claude、GPT、DeepSeek、M3谁是工程利器
引言:跑分之外,实战见真章
随着MiniMax M3的发布,又一个号称「Coding SOTA」的国产模型进入了大家的视野。官方宣传的MSA架构、Agent工程场景优化听起来很诱人,但现实是——大家对Benchmark的信任度已经越来越低了。今天榜单第一,明天换一个,真正到了工作中,模型能不能帮你把事情做完,和跑分往往不是一回事。
B站UP主「不正经的前端」设计了四个由浅入深的Coding场景,对Claude Opus 4.8、GPT 5.5、MiniMax M3、Mimo 2.5 Pro和DeepSeek V4 Pro进行了一次硬核横向测评。测试统一在Claude Code环境下完成,评分只看最终完成度,价格、速度和Token消耗仅供参考。
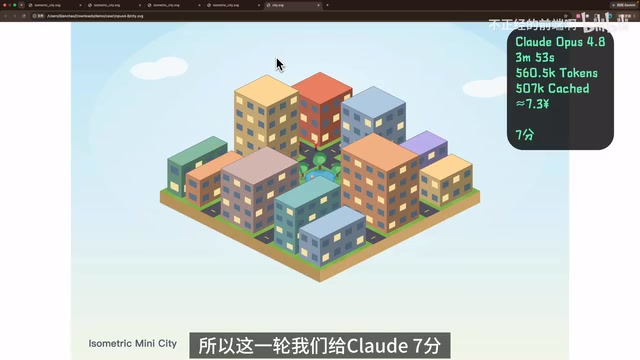
Case 1:纯SVG绘制等距视角微型城市
第一个任务要求模型使用纯SVG代码绘制一个等距视角的微型城市,包含道路、建筑、公园、树木、车辆和行人,不能使用任何HTML、CSS或JavaScript。这个任务看似是绘图,实际考验的是空间理解、结构组织和长代码输出能力。
等距视角(Isometric Projection)是一种不存在透视缩放的轴测投影方式,三个坐标轴之间的夹角均为120度。这种投影在经典游戏(如《模拟城市》《纪念碑谷》)中被广泛使用,因为它能在二维平面上清晰表达三维空间关系,同时避免了真实透视带来的远近变形。用纯SVG实现等距视角意味着模型必须在没有3D引擎辅助的情况下,手动计算每个元素的坐标偏移和层叠顺序(z-index),这对空间推理能力是极大的考验。
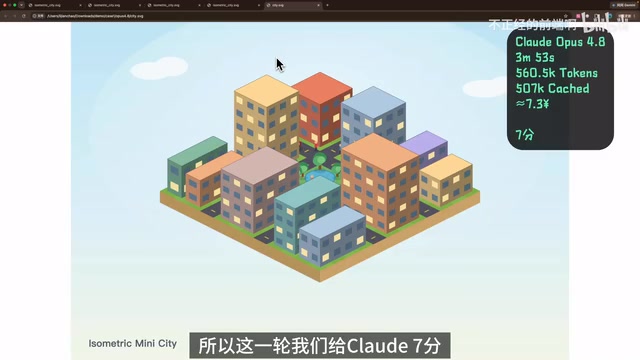
各模型表现差异明显:
- DeepSeek V4 Pro(4分):核心元素齐全,能看出城市结构,但存在穿模、比例失衡和空间关系混乱的问题,属于基本完成任务。
- Mimo 2.5 Pro(2分):透视关系混乱,阴影处理缺失,配色尚可但缺乏统一感,看起来不像一个完整的城市。
- MiniMax M3(6分):细节最丰富,主动搭建了天空、光晕等氛围场景,但穿模和布局混乱问题也很突出——典型的「高上限、高风险」选手。
- GPT 5.5(5分):元素不少但建筑布局随缘,阴影颜色不协调,远看还行近看问题多。
- Claude Opus 4.8(7分):整体设计能力最强,道路、建筑和绿化之间的关系自然,层次清晰,几乎没有结构性错误。虽然细节不如M3丰富,但更像经过规划的成品。
本轮结论:M3是创意型选手,Claude是工程型选手。在代码生成任务中,错误率比创造力更重要,Claude胜出。
Case 2:完整3D跑酷游戏生成
第二个任务直接让模型生成一个完整的3D跑酷游戏,涉及场景搭建、循环渲染、物理逻辑、碰撞检测和对象生命周期管理——这些堪称大模型的「翻车重灾区」。
3D跑酷游戏的实现涉及多个相互耦合的技术模块:场景循环(Infinite Scrolling)需要在玩家前进时动态生成和回收地形块以营造无限跑道的错觉;碰撞检测(Collision Detection)通常采用AABB包围盒或射线检测来判断角色与障碍物的交互;对象生命周期管理则要求及时销毁离开视野的对象以防止内存泄漏。循环渲染依赖requestAnimationFrame实现每帧更新,物理逻辑则需要模拟重力、跳跃抛物线和落地判定。这些模块中任何一个出错都会导致游戏无法正常运行,因此被称为大模型代码生成的「翻车重灾区」。
- DeepSeek V4 Pro(7分):表现超出预期,场景循环、碰撞检测、角色控制都没问题,还加了镜头跟随和音效,游戏感很强。
- Mimo 2.5 Pro(4分):碰撞检测正常,但左右控制反了,最严重的是没有跑酷主体对象,体验大打折扣。
- MiniMax M3(7分):细节依然丰富,额外加了跑步动画、金币粒子特效,甚至设计了下蹲通过的特殊关卡。但缺少视角跟随,在对比中显得尴尬。
- GPT 5.5(0分):直接翻车,两次生成都是空屏,原因不明。
- Claude Opus 4.8(6分):整体框架成立,但左右控制方向反了,空格键跳跃会刷新游戏(上键跳跃正常),这个bug影响体验。
本轮结论:DeepSeek和M3并列领先,前者靠音效和视角跟随加分,后者靠细节和创意取胜。GPT 5.5意外交了白卷。
Case 3:电梯调度模拟器
第三个任务要求生成一个包含三台独立电梯的调度模拟器,支持动态生成乘客和实时调度。核心考验状态管理和调度算法——电梯在哪层、要不要停、谁去接新乘客、要不要顺路带人,这些逻辑极易出bug。
电梯调度是经典的操作系统和分布式系统教学案例。常见的调度策略包括FCFS(先来先服务)、SCAN(扫描/电梯算法,类似磁盘寻道,电梯沿一个方向运行到底再折返)和LOOK(改进型扫描,到最远请求楼层即折返而非一定到顶/底层)。多电梯场景下还需要解决「资源竞争」问题——即多台电梯同时响应同一请求导致的资源浪费。这本质上是分布式系统中的一致性问题,需要通过锁机制、状态同步协议或集中式调度器来协调多台电梯的行为,确保每个乘客请求只被一台电梯响应。
- DeepSeek V4 Pro(7分):调度逻辑基本无误,乘客排队、接人、送达全流程跑通,UI虽不惊艳但核心逻辑成立。
- Mimo 2.5 Pro(2分):调度算法不对,UI交互也有问题,逻辑和展示都没做好。
- MiniMax M3(6分):调度算法基本正常,但存在资源竞争问题——某楼层只剩一个乘客,两台电梯同时响应,一台接走后另一台仍然赶过去扑空。这是典型的竞态条件(Race Condition),说明调度状态同步没处理干净,缺少对共享状态的互斥访问控制。
- GPT 5.5(约5-6分):调度逻辑没问题,但乘客进电梯时会从页面左上角飞过来,按钮区域还遮挡了电梯通道。
- Claude Opus 4.8(7分):调度逻辑和UI都没有明显槽点,依然非常稳定。
本轮结论:DeepSeek和Claude完成度最高,M3和GPT紧随其后但各有瑕疵,Mimo再次拉胯。
Case 4:真实工程项目Bug修复(长程任务)
前三个Case本质上都是边界明确、代码规模有限的Demo。最后一个Case直接上了真实项目——一个基于NewAPI二次开发的大模型网关,其中的auto分组(智能熔断)功能存在线上bug:有时后面还有可用分组,系统就直接返回错误;有时找不到应该切换的目标分组。
这里提到的「智能熔断」是API网关中的关键容错机制。熔断器模式(Circuit Breaker Pattern)借鉴自电气工程中的断路器概念:当某个下游服务的错误率超过阈值时,熔断器「跳闸」,后续请求不再发往该服务而是快速失败或切换到备用通道。在大模型网关场景中,这意味着当某个模型供应商的API出现故障(如超时、限流、服务不可用)时,系统应自动将请求路由到其他可用供应商。这个机制的难点在于状态判断的时效性——熔断器通常有三种状态:关闭(正常放行)、打开(全部拦截)和半开(试探性放行少量请求以检测恢复),这些状态之间的转换需要精确的超时控制和健康检查,而历史遗留代码中的耦合逻辑往往让状态转换变得不可预测。
这个任务涉及配置读取、路由选择、熔断逻辑、错误处理、模型调度和缓存状态,各种逻辑耦合在一起,还混着历史遗留设计。模型需要不断读取文件、分析调用关系、追踪逻辑链路,上下文长度会快速膨胀——这恰恰是MiniMax宣传MSA架构优势的核心场景。
由于任务耗时极长,UP主只选择了三个模型进行对比:
Mimo 2.5 Pro(4分)
- 用时约1.5小时,消耗6.8M Token(6.3M缓存命中),成本约10元
- 找到了部分问题,代码修改本身没有明显错误,但修复方案不完整,遗漏了关键路径
- 更像是在已有逻辑上做局部修改,没有触及根本原因
MiniMax M3(6分)
- 用时56分钟,消耗16.6M Token(16.1M缓存命中),成本约7元
- 明确指出这是架构层面的设计问题(与UP主判断一致),但选择了保守方案——通过补偿逻辑和兜底逻辑降低异常概率
- 给出的理由是系统已在线运行,直接改架构风险太高。思路合理但问题未被彻底解决
MiniMax M3所采用的MSA(Multi-head Shared Attention,多头共享注意力)架构是对标准Transformer注意力机制的改进方案。传统多头注意力(MHA)中,每个注意力头独立维护Query、Key、Value矩阵,内存开销随上下文长度二次增长,这在处理超长上下文时会成为严重的性能瓶颈。MSA通过在多个注意力头之间共享部分KV缓存(类似于GQA/MQA的思路但有所不同),在保持模型表达能力的同时显著降低了长序列推理时的内存占用和计算成本。这解释了为什么M3在短任务中速度并不突出,但在Case 4这种上下文快速膨胀到数百万Token的长程任务中反而展现出效率优势——架构红利在长尾场景下才真正兑现。
Claude Opus 4.8(8分)
- 用时20分钟,消耗13.9M Token(13.7M缓存命中),成本约45元
- 同样判断为架构问题,但没有替用户做选择,而是给出多个改造方案并分析收益和风险
- UP主选择了推荐的重构方案,从代码review角度看是目前最完整的解决方案
长程任务的关键发现
一个值得关注的细节是:在前三个简单Case中,M3的速度比Mimo稍慢;但在这个复杂的长程任务中,M3反而比Mimo快了很多(56分钟 vs 90分钟),最终效果也更好。这是否是MSA架构在长上下文场景下的优势体现?虽然无法严格验证,但至少从实际体验来看,M3在长上下文多轮分析场景下确实展现出了明显的优势。
另一个值得关注的维度是Token消耗与成本的关系。Case 4中各模型的数据揭示了一个重要的成本结构:M3消耗了16.6M Token,其中16.1M为缓存命中(命中率97%),最终成本仅7元;而Claude消耗13.9M Token,缓存命中13.7M(命中率98.6%),成本却高达45元。这种差异主要来自两方面:一是各厂商的定价策略不同,Claude的单价显著高于国产模型;二是缓存命中的Token通常按远低于首次计算的价格计费(通常为原价的1/10到1/4),因此高缓存命中率对控制长程任务的成本至关重要。这也是为什么Prompt缓存(Prompt Caching)技术——即将重复出现的上下文前缀缓存起来避免重复计算——已成为当前大模型API服务的核心竞争力之一。
综合评价与行业观察
| 模型 | Case1 SVG | Case2 3D游戏 | Case3 电梯调度 | Case4 工程修复 |
|---|---|---|---|---|
| Claude Opus 4.8 | 7 | 6 | 7 | 8 |
| DeepSeek V4 Pro | 4 | 7 | 7 | - |
| MiniMax M3 | 6 | 7 | 6 | 6 |
| GPT 5.5 | 5 | 0 | ~5 | - |
| Mimo 2.5 Pro | 2 | 4 | 2 | 4 |
Claude Opus 4.8依然是当前最强的工程型模型,稳定性和完成度全面领先,尤其在真实工程任务中优势明显,但价格也最贵。
MiniMax M3是本次测评中最有特点的国产模型——创意丰富、细节到位,在长程任务中展现出了超越同级国产模型的表现。MSA架构在长上下文场景下的效率优势值得持续关注。
DeepSeek V4 Pro在Demo级任务中表现稳健,性价比突出,但遗憾未参与最后的工程级测试。
正如UP主所感慨的:两年前大家讨论国产模型时,问的是「能不能写代码」「是不是只能聊天」;而今天的讨论已经变成了「谁更稳定」「谁更适合Agent」「谁在长上下文里表现更好」。当讨论从「能不能用」变成「谁更好用」,说明整个行业已经进入了新的阶段。国产模型距离Claude仍有差距,但它们已经真正开始进入开发者的工作流——这件事本身,可能比某个Benchmark的第一名更值得关注。
相关推荐
Claude Code是什么?与普通AI对话的五大核心区别
深入解析Claude Code与ChatGPT、DeepSeek等普通AI对话工具的五大核心区别,从交互方式、上下文理解、执行力、记忆能力到工具调用,全面了解这款AI编程助手的真正实力。
Claude Code vs Codex深度对比:技术趋同下谁更值得选
深度对比Claude Code与OpenAI Codex在先发优势、技术架构、市场份额和工程稳定性方面的差异。从18:4的创新领先到功能像素级对齐,解析AI编程工具趋同时代的终极选择标准。
Claude Code每天必用的5个技巧:让AI反过来盘问你
分享Claude Code高效编程的5个实用技巧:Grill Me逼问需求、Brainstorming方案选型、Writing Plan执行计划、TDD测试驱动、Debugging精准修复,串成完整AI编程工作流,告别模糊需求和来回返工。