7个AI修同一个Bug实测:GLM 5.1反超Claude Sonnet详细对比

7个AI模型修复AI写的真实Bug,GLM 5.1凭测试覆盖夺冠
测试者从35万Star的AI原生开源项目OpenClaw中选取三个真实PR,让7个AI模型独立修复Bug。结果显示:简单题全员方案趋同,差距在测试覆盖;普通题全员正确但GLM测试量碾压;困难题千问翻车出局,Sonnet单题最高。最终GLM 5.1以89.3分夺冠,Sonnet 4.6第二,千问末位淘汰。
测试背景:OpenClaw 35万Star项目的真实PR复现
这是一场别开生面的AI编程能力对决。测试者从OpenClaw(一个35万Star的开源项目)中选取了三个刚合并的真实PR,让7个AI模型在不知道答案的情况下独立修复Bug,答案藏在已合并的分支中,用来做最终评判。
值得一提的是,OpenClaw本身就是作者Peter全程用AI webcoding写出来的项目——PR是AI提的,review是AI做的,合并到main也是AI决定的。所以这期测试的本质是:7个AI修AI写出来的Bug,人类全程只做一件事——花钱买coding plan。
OpenClaw代表了「AI原生开发」(AI-Native Development)的新范式。在这种模式下,AI不仅是辅助工具,而是承担了从代码生成、PR提交、Code Review到分支合并的完整开发闭环。这与传统的「AI辅助编程」(如GitHub Copilot的代码补全)有本质区别——后者仍以人类为决策核心,而AI原生开发中人类退化为「资源提供者」角色。这种模式的可行性依赖于大模型在代码理解、上下文推理和工程判断上的综合能力,也使得「AI修AI写的Bug」成为一种具有自我指涉意味的能力测试。本次测试同时采用了「真实PR复现」方法,相比传统的编程竞赛题(如LeetCode)或合成Benchmark(如HumanEval、SWE-bench),具有更高的生态效度(Ecological Validity)——使用「刚合并的PR」作为测试集,可以有效规避训练数据污染风险,更接近真实工程场景的质量标准。
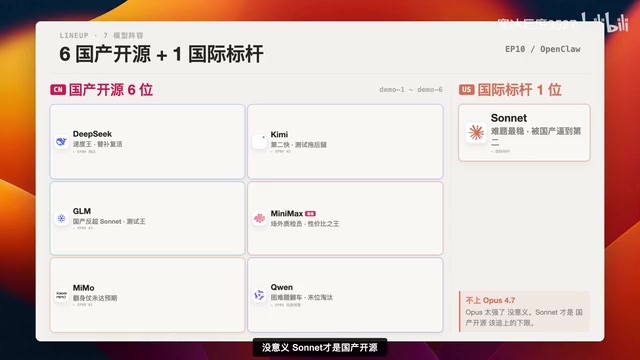
参赛选手与评分规则
海外选手特意选择了Claude Sonnet 4.6而非Opus 4.7,理由是Opus太强没有对比意义,Sonnet才是国产开源应该追上的基准线。
国产开源6位选手:
- DeepSeek V4 Flash:上期Pro被淘汰,Flash替补出战
- Kimi K2.6:从第一期开始的元老选手
- GLM 5.1:此前稳定亚军,这期能否更进一步
- MiniMax M2.7:质检员角色,稳定参赛
- Mimo V2.5 Pro:稳定耐黑,寻求翻身
- 千问 3.6 Plus:连续危险预警,运气能否延续
评分维度包含五个方面:能跑过测试、修对、改干净、补测试,最终加权综合评分。
简单题:Crown Twist Lack通知失败
题目分析
这道题Issue几乎给了答案,考验的是谁能精准做到最小改动。官方做法是把AllowBootstrap当参数透传,只在Crown路径设置处理。
结果:全员撞车
7个模型不约而同使用了同一种简化方案——直接在源头硬编码。功能等价但更激进,影响所有调用方。这种「偷懒」做法虽然能解决问题,但不如官方方案优雅。
差异体现在测试覆盖上,而测试覆盖率本身是衡量代码质量的核心工程指标。大模型在生成测试代码时,实际上需要对被测代码进行逆向推理,枚举边界条件和异常路径。Google的工程实践表明,修复生产Bug的成本是开发阶段的6-10倍,而充分的单元测试可以将回归率降低40%以上。本题中:
- GLM 5.1补了19行测试
- Kimi K2.6补了12行
- 其他五个(包括Sonnet 4.6)一行测试都没写
本题得分:GLM 5.1(85分)> Kimi K2.6(80分)> 其他全员(75分)
普通题:MCP协议客户端Signal转发
题目分析
需要在两层之间转发一个Signal,属于MCP协议客户端的About后插件拖不停问题。
MCP(Model Context Protocol)是Anthropic于2024年底提出的开放标准协议,旨在解决AI模型与外部工具、数据源之间的集成碎片化问题。在MCP架构中,存在Host(宿主应用)、Client(客户端)和Server(工具服务端)三层结构。Signal转发问题属于典型的异步事件传播场景——当用户发起取消请求时,该信号需要从顶层Host穿透Client层,最终传递到正在执行的Server端工具调用中。若Signal在中间层丢失,会导致长时间运行的工具无法响应取消指令,造成资源泄漏和用户体验问题。这道题考验的正是模型对分层协议架构中事件传播机制的理解深度。
结果:全员正确,差距在测试覆盖
7个模型都按照官方一模一样的pattern修复:
- call to加signal参数
- toexecute把signal透传下去
- set request的handler从extra里拿signal
三步一个字不差。这大概率说明原始PR本身也是AI提交并经AI审核后合并的。
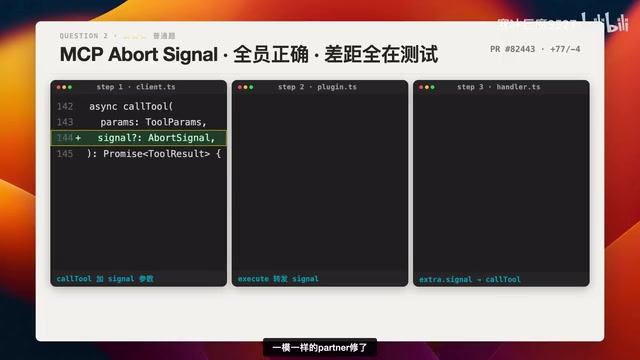
测试覆盖的差距才是真正的分水岭:
- GLM 5.1:108行测试,是Sonnet的1.3倍,Kimi的2倍
- MiniMax:87行,比Sonnet还多
- Kimi:仅55行,元老选手偷懒了
本题得分:GLM 5.1(92分,满分级)> MiniMax/Sonnet(90分)> 千问(87分)> Kimi(84分)
困难题:Gateway启动验证过严
题目分析
插件还没加载就爆Fatal错误,需要区分「插件没装」和「装了还没启动」两种情况,分别处理。Issue给了三个方案,核心是区分stale evidence和missing plugin。
这道题涉及一种重要的防御性编程模式:基于证据的状态区分(Evidence-Based State Discrimination)。在插件系统设计中,「插件未安装」和「插件已安装但未启动」是两种截然不同的系统状态,对应不同的错误处理策略。前者属于配置缺失,应以Fatal级别阻断启动流程;后者属于时序问题,可以降级为Warning并等待插件就绪。这体现了「最小权限原则」的错误处理变体——错误的严重程度应与其实际影响范围精确匹配,过度宽松的错误处理会掩盖真实的系统故障,增加排查难度。
结果:6对1错
6个模型用了门控函数hadStalePluginEvidence,只有真正存在插件证据时才降级severity,与官方方案一致。
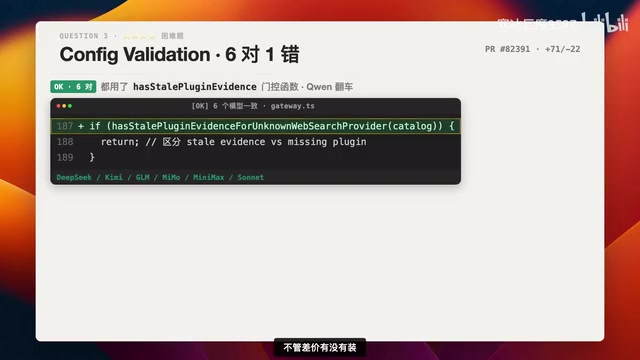
千问3.6 Plus唯一翻车:直接把error push改成warning push,不管插件有没有装全部降级,违反了Issue的明确要求,仅得50分。这正是忽视「基于证据的状态区分」原则的典型错误——用一刀切的宽松处理掩盖了真实的配置缺失场景。
Sonnet 4.6拿下全场最高93分:注释最完整,测试最严谨,门控加早返回的实现最为优雅。国产开源三个90分围攻(DeepSeek、GLM、MiniMax),差距仅3分但差距确实存在。
综合排名与深度分析
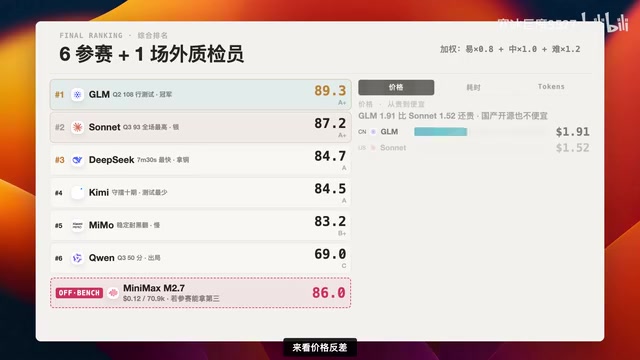
最终排名
| 排名 | 模型 | 综合分 | 亮点 |
|---|---|---|---|
| 1 | GLM 5.1 | 89.3 | 测试覆盖碾压全场 |
| 2 | Sonnet 4.6 | 87.2 | 困难题最高93分 |
| 3 | DeepSeek V4 Flash | 84.7 | 最快7分30秒 |
| 场外 | MiniMax M2.7 | 86.0 | 性价比之王 |
| 末位 | 千问 3.6 Plus | 69.0 | 困难题翻车出局 |
关键发现
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。