阿里云百炼平台实战:API调用到多轮对话完整教程
阿里云百炼平台大模型API从入门到实战的完整开发指南
本文系统介绍了阿里云百炼平台的核心使用方法,包括API Key获取与环境配置、基础调用与深度思考模式、流式输出实现、多轮对话原理(本质是重复输入完整历史而非模型记忆)、以及提示词工程中system/developer/user/assistant四种角色的分工与安全护栏配置。平台兼容OpenAI标准接口,迁移成本低,适合开发者快速上手大模型应用开发。
前言
阿里云百炼平台是阿里云对外提供大模型服务的核心平台,集成了通义千问系列等多种模型。本文将通过实际代码演示,带你从零开始完成API Key获取、基础调用、流式输出、多轮对话以及提示词工程等核心操作,帮助开发者快速上手大模型应用开发。
阿里云百炼平台(Alibaba Cloud Bailian)是阿里云在2023年正式推出的一站式大模型服务平台,定位为企业和开发者接入大模型能力的统一入口。该平台不仅提供阿里自研的通义千问(Qwen)系列模型,还集成了第三方开源模型如DeepSeek、Llama等。百炼平台的核心价值在于将复杂的模型部署、推理加速、API管理等基础设施工作封装为标准化服务,开发者无需关心GPU资源调度和模型加载等底层细节,只需通过API调用即可获得大模型能力。
环境准备:获取API Key与基础配置
注册与获取API Key
使用阿里云百炼平台的第一步是获取API Key。进入阿里云官网后,点击"立即体验"进入百炼平台,在平台中找到"我的API Key"选项,如果没有则点击"创建"生成一个新的Key。
重要提醒: API Key是模型使用计费的唯一标识,切勿泄露给他人,否则你的余额可能被他人消耗。学习阶段建议充值10-20元即可满足日常实验需求,性价比非常高。
代码基础配置
百炼平台兼容OpenAI标准接口,配置非常简洁:
- 导入OpenAI标准接口库
- 填写API Key(可配置到系统环境变量中)
- 设置Base URL为阿里云的对外服务地址(所有用户统一)
OpenAI在2022-2023年间建立的Chat Completions API已成为大模型调用的事实标准。该接口定义了统一的请求格式(包含model、messages、temperature等参数)和响应格式(包含choices数组、usage统计等字段)。国内外众多大模型厂商(如阿里云、智谱AI、Moonshot等)都选择兼容这一标准,意味着开发者只需更换base_url和api_key,即可在不同模型间无缝切换,极大降低了技术迁移成本。这种兼容性也使得基于OpenAI SDK开发的应用可以直接对接国内模型服务。
基础调用:全量输出与深度思考模式
第一个API调用示例
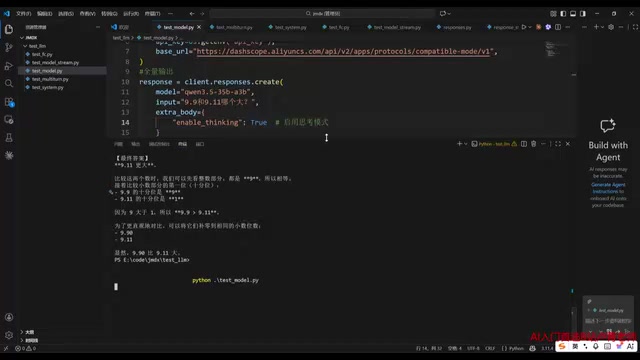
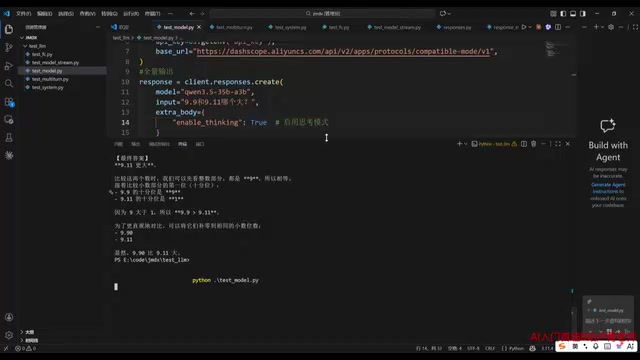
以千问3.5-32B模型为例,构建一个简单的问答请求。例如询问"9.9和9.11哪个大"这个经典的大模型测试问题。
在关闭深度思考模式时,模型会直接给出最终答案(虽然可能出错)。而开启深度思考模式后,模型会先进行推理过程,再返回最终答案,但响应时间会明显变长。
深度思考模式(也称为推理模式或Chain-of-Thought推理)源自OpenAI的o1模型所开创的范式。其核心思想是让模型在给出最终答案前,先进行显式的逐步推理过程。从技术实现上看,这类模型在训练阶段通过强化学习(如RLHF或GRPO)被训练为先输出思维链(thinking tokens),再输出最终答案。思维链中的token同样消耗算力和时间,因此深度思考模式的响应延迟和token消耗都会显著增加。千问QwQ和Qwen3系列模型支持这一能力,在数学推理、代码生成、逻辑分析等任务上表现明显优于直接回答模式。
实践建议: 任务简单时关闭思考模式以提升响应速度,只有在复杂推理任务时才开启深度思考。
模型选择指南
在百炼平台的"模型广场"中,可以浏览所有可用模型。需要注意的是,如果使用文字对话接口,不能选择图像类模型,否则会报错。选择模型时只需复制模型名称,替换代码中的model参数即可。
流式输出:提升用户体验的关键技术
全量输出与流式输出的区别
在百炼平台的在线体验中,你会发现文字是"一个字一个字蹦出来"的,这就是流式输出(Streaming)。而代码默认的全量输出则需要等待所有内容生成完毕后一次性返回。
流式输出的核心优势在于用户体验——用户无需长时间等待空白响应,可以实时看到生成过程。
流式输出的实现方式
实现流式输出只需将请求参数中的stream设置为true,数据就会像水流一样逐字返回。遍历响应时,分别处理推理内容和正常文本内容即可。
流式输出基于HTTP协议中的Server-Sent Events(SSE)技术实现。传统HTTP请求是请求-响应模式,服务端必须生成完整内容后才能返回。而SSE允许服务端在保持连接的情况下,持续向客户端推送数据片段。在大模型场景中,模型采用自回归(Autoregressive)生成方式,即逐token预测下一个token,每生成一个token就可以立即通过SSE推送给客户端。对于一个需要生成500个token的回答,全量输出可能需要等待10秒,而流式输出在第一个token生成后(通常几百毫秒)就开始返回,用户感知的首字延迟(Time to First Token, TTFT)大幅降低。
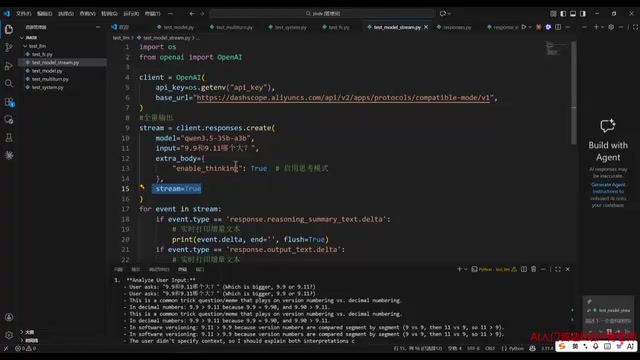
这些代码结构都是固定格式,开发者直接套用模板即可,无需深入理解底层协议细节。
多轮对话:让AI记住上下文的实现原理
多轮对话的实现机制
大模型本身并没有真正的"记忆"能力。多轮对话的实现方式其实是最"笨"的方法——每次请求时,将之前所有的对话历史全部重新输入给模型。
大模型基于Transformer架构,其推理过程是无状态的——每次请求都是独立的前向传播计算,模型本身不会在请求间保留任何信息。这与传统数据库或会话管理有本质区别。所谓的"多轮对话"完全依赖于将历史消息拼接后重新输入。这也引出了上下文窗口(Context Window)的概念:模型能处理的最大token数量是有限的(如Qwen系列支持8K到128K不等)。当对话历史超过上下文窗口限制时,需要进行截断或摘要压缩,否则会导致API报错或早期信息丢失。这也是为什么长对话场景下需要引入RAG(检索增强生成)或外部记忆机制的原因。
具体做法是维护一个messages数组:
- 首先放入system角色的人设设定
- 用户每次输入后,以user角色追加到数组
- 模型回复后,以assistant角色追加到数组
- 下一轮对话时,将完整数组作为输入
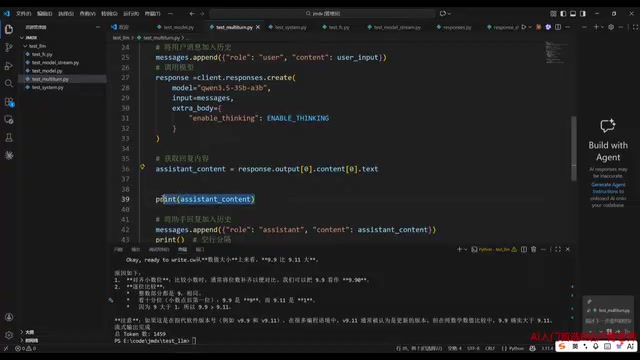
效果验证
例如先问"我是谁",模型自然不知道;然后告诉它"我是皮蛋爸爸";再次问"我是谁"时,模型就能正确回答。这是因为前面的对话历史已经包含在了本次请求中。
提示词工程:四种角色设定详解
百炼平台角色体系
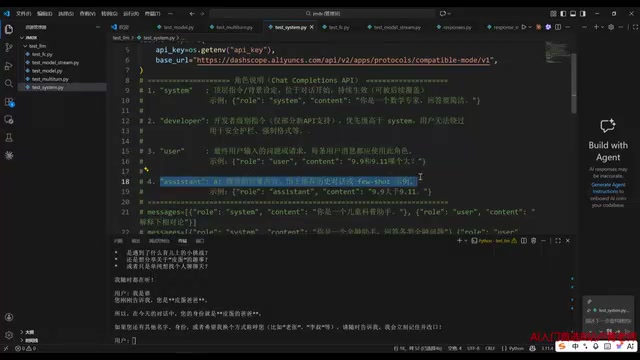
百炼平台支持四种角色设定,且只能使用这四种(使用其他名称会报错):
| 角色 | 用途 |
|---|---|
| system | 大模型的人格设定,定义"你是什么样的人" |
| developer | 安全设定,如安全护栏、强制格式等 |
| user | 用户输入的问题 |
| assistant | 模型的回答 |
百炼平台的四角色体系体现了大模型应用中的权限分层思想。system角色设定模型的基础人格和能力边界,通常由应用开发者在部署时固定;developer角色是阿里云在OpenAI标准基础上的扩展(对应OpenAI的system角色在新版API中的拆分),专门用于设置安全策略和输出约束,其优先级高于system;user角色代表终端用户的实时输入;assistant角色记录模型的历史回复。这种分层设计使得应用开发者可以在不修改用户交互逻辑的情况下,独立配置安全护栏,实现了关注点分离(Separation of Concerns)的工程原则。在实际生产环境中,developer角色常用于防止提示注入攻击(Prompt Injection)和内容合规控制。
实战案例:安全护栏配置
一个典型应用场景是金融助手。当设定system为"你是金融助手,回答各类金融问题"时,询问"如何转一万块钱到美国"会得到详细的跨境汇款指南。
但如果在developer角色中加入"拒绝回答跨境转账的问题"这一安全约束,同样的问题就会被直接拒绝。而"从支付宝转1万到银行卡"这类不涉及跨境的问题仍然会正常回答。
这体现了大模型对安全边界的精准把控——严格遵守,不枉不纵。
总结
通过本文的实战演示,我们掌握了阿里云百炼平台的核心使用方法:
- API Key获取与环境配置是基础门槛
- 流式输出是提升产品体验的必备技术
- 多轮对话依赖完整历史的重复输入
- 提示词工程中的角色分工实现了灵活的行为控制
对于开发者而言,百炼平台兼容OpenAI接口标准,迁移成本极低,加上极具竞争力的价格(学习阶段10-20元足够),是国内大模型应用开发的优质选择。
核心要点
- 阿里云百炼平台兼容OpenAI标准接口,配置简单,学习成本仅需10-20元
- 流式输出通过设置stream=true实现,显著提升用户体验
- 多轮对话的本质是将完整对话历史重复输入模型,而非模型具有真正记忆
- 提示词工程支持system、developer、user、assistant四种角色,developer角色可实现安全护栏功能
- 深度思考模式适用于复杂推理任务,简单任务建议关闭以提升响应速度
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。