Agent Harness:从提示词工程到执行环境编排的AI代理新范式
从Prompt Engineering到Context Engineering,再到如今的Harness Engineering,AI代理的工程范式正在经历一场深刻的演进。这个被正式命名的概念,究竟意味着什么?它与我们熟知的提示词工程和上下文工程有何本质区别?
从4000 Token开始的进化之路
故事要从2022年ChatGPT发布说起。当时我们面对的是仅有4000 Token的上下文窗口——这个极其有限的"记忆空间"严重制约了AI代理的能力。
要理解这个限制的严苛程度,需要先了解Token的概念。Token是大语言模型处理文本的基本单位,一个英文单词通常被拆分为1-3个Token,而一个中文汉字通常对应1-2个Token。4096 Token的上下文窗口大约相当于3000个英文单词或2000个中文汉字——仅够容纳一篇中等长度的文章。上下文窗口本质上是模型在一次推理过程中能够"看到"和"记住"的全部信息量,包括系统提示、用户输入、历史对话和模型输出。到2025年,主流模型的上下文窗口已扩展到128K甚至百万级Token,但窗口的扩大并未线性地提升任务完成质量,因为模型在超长上下文中存在"迷失在中间"(Lost in the Middle)的注意力衰减问题。
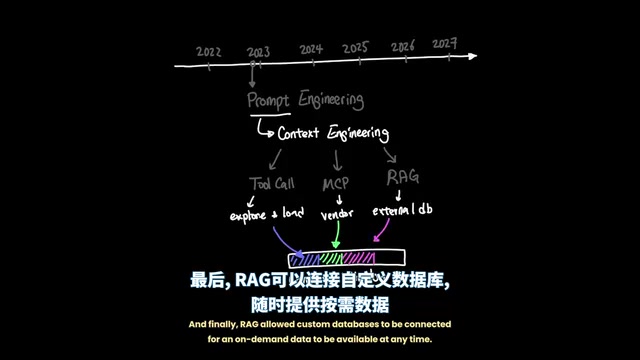
在这样的限制下,简单的提示词工程(Prompt Engineering)远远不够,于是一个核心问题浮出水面:如何用更少的资源做更多的事?
这催生了上下文工程(Context Engineering)的兴起。通过工具调用(Tool Calling)、MCP协议和RAG检索增强生成等技术,开发者们找到了更高效管理上下文窗口的方法:
- Tool Calling:让代理能够探索代码仓库,只读取与当前任务相关的特定文件,并在外部创建操作。Tool Calling的核心机制是让模型在推理过程中识别何时需要调用外部工具(如代码执行器、搜索引擎、数据库查询),并生成结构化的调用请求,由运行时环境执行后将结果返回模型,从而突破模型自身能力的边界。
- MCP:允许在模型之上添加供应商特定的功能。MCP(Model Context Protocol,模型上下文协议)是Anthropic于2024年底推出的开放标准,旨在为AI模型与外部数据源、工具之间建立统一的通信协议,类似于AI领域的USB-C接口,使得不同供应商的工具和服务能够以标准化方式接入任意兼容的AI模型。
- RAG:将自定义数据库连接到系统,实现按需数据随时可用。RAG(Retrieval-Augmented Generation,检索增强生成)由Meta在2020年提出,其核心思想是在模型生成回答前,先从外部知识库中检索相关文档片段,将其注入上下文作为参考依据,从而弥补模型训练数据的时效性和专业性不足。
Cursor、Windsurf、Kline、Roo和Aider等编程代理都是这一阶段的早期玩家,它们采用工具调用来实现上下文工程,确实能够完成不少工作。这些工具代表了当前AI编程代理赛道的不同路线:Cursor和Windsurf是基于VS Code的独立IDE分支,将AI能力深度集成到编辑器体验中;Kline(原Cline)和Roo是VS Code插件形态,以开源社区驱动的方式快速迭代;Aider则是命令行工具,面向偏好终端操作的开发者。
上下文工程为何遇到天花板
随着底层模型的进化,上下文窗口不断增大,编程代理开始能够处理更长时间的任务。人们开始要求这些代理完成越来越大范围的功能开发和Bug修复。然而,即便是上下文工程也有其明显的极限。
以"克隆一个完整网站"这样的大型任务为例:简单的提示词工程只能给出一个粗糙的一次性结果;而上下文工程虽然好一些,但结果依然不尽如人意——网站可能只完成了一半,某些按钮无法工作,功能也没有被充分测试。
问题的根源在于上下文摘要机制。 当一个任务需要12小时来完成时,随着上下文窗口逐渐填满,代理会通过摘要来压缩上下文以继续工作。这意味着代理的能力被其自身的摘要质量所束缚。
上下文摘要(Context Summarization)是当对话或任务执行过程中累积的Token数量接近上下文窗口上限时,系统自动将早期内容压缩为简短摘要的机制。这一过程通常由模型自身完成——系统会将已有的对话历史发送给模型,要求其生成一个保留关键信息的精简版本。然而,摘要本质上是一种有损压缩:每次压缩都不可避免地丢失细节。在多轮摘要叠加的场景下(即对摘要再次摘要),信息损失呈指数级增长。更关键的是,模型在生成摘要时缺乏对"哪些信息在未来步骤中至关重要"的预判能力,可能将尚未完成的子任务状态错误地标记为已完成,或遗漏关键的约束条件和依赖关系。
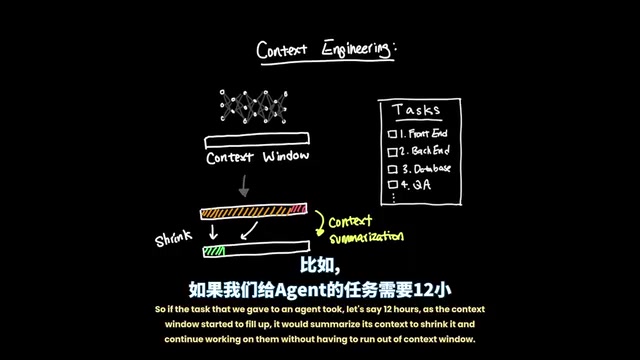
更糟糕的是,当上下文在任务执行中途被摘要压缩时,代理可能会错误地认为某些任务已经完成,或者过度简化任务假设某些功能已经验证通过。这就是为什么我们经常看到AI代理的任务只完成了一半,甚至某些部分根本没有被尝试。
这种弹性的自我管理上下文窗口的方式,虽然表面上赋予了代理处理长期任务的能力,但实际效果远不如预期。
Harness Engineering的核心理念:循环与隔离
在上下文工程遇到瓶颈的同时,开发者们已经在尝试各种解决方案——子代理的层级上下文管理、多代理集群(Swarms)等。
多代理集群(Swarms)的概念源自分布式系统和群体智能理论。在AI代理领域,Swarms指的是多个独立代理协同工作完成复杂任务的架构模式。早期的多代理框架如AutoGen(微软)、CrewAI和LangGraph等,探索了不同的协作范式:有的采用层级结构(一个主代理分配任务给子代理),有的采用对等协作(代理之间平等讨论达成共识),还有的采用流水线模式(任务在代理之间顺序传递)。这些探索揭示了一个核心挑战:代理之间的上下文共享与隔离如何平衡。共享过多会导致上下文污染和Token浪费,隔离过度则导致信息断层和重复劳动。
这些探索都在向同一个方向收敛:对底层代理进行更好的编排和管理。
Agent Harness这一概念的正式提出,标志着AI代理工程进入了新阶段。虽然有人认为这只是一个流行词,但它确实捕捉到了AI行业正在发生的变革本质。
Harness Engineering最关键的创新是**循环(Loops)**的引入。它在上下文工程之上增加了一个编排层,将代理置于一个循环环境中:
- 生成需求文档:首先创建一份详细的产品需求文档(PRD),将其结构化为JSON文件。PRD在传统软件工程中是产品经理用来定义产品功能、用户故事和验收标准的核心文档。在Harness Engineering中,PRD被赋予了新的角色——它不仅是人类可读的需求描述,更是机器可解析的任务图谱。将PRD结构化为JSON格式意味着每个功能点都被拆解为具有明确输入、输出、依赖关系和验收条件的原子任务。
- 任务分解与循环执行:从文档中每次只选取一个任务来完成。这种做法借鉴了软件工程中"分而治之"(Divide and Conquer)的经典策略,同时也与敏捷开发中将Epic拆分为User Story再拆分为Task的层级分解思想一脉相承。关键区别在于,这里的任务分解不是为人类开发者设计的,而是为AI代理的认知特性量身定制——每个任务的粒度恰好适合在一个干净的上下文窗口内完成。
- 全新上下文:每次迭代都给予代理全新的提示词和上下文
- 测试与记录:每个步骤都进行测试和文档记录
- 持续迭代:循环继续,直到所有任务完成
这种架构的精妙之处在于:代理不再需要在一个不断膨胀和压缩的上下文中挣扎,而是在每次迭代中都拥有一个干净、聚焦的工作环境,同时遵循严格的启动和完成规则。
实践案例:从Ralph到现代编程代理
Ralph是Harness Engineering最具代表性的实践案例之一,它在互联网上引起了广泛关注——不仅因为效果出色,更因为其底层架构极其简洁。它的工作流程完美体现了Harness的核心思想:先创建PRD,再循环实现一个又一个功能直到完成。
同样,Anthropic也提供了简洁的Harness示范——轻量级、简单的环境设计。当你查看这些项目的代码仓库时,会惊讶于如此强大的架构竟然建立在如此精简的代码之上。
需要特别强调的是,Harness Engineering并不废弃之前的工程范式。 如果你深入查看Kline等开源编程代理的底层,会发现它们的系统提示仍然由精心编写的提示词驱动。三者的关系是层层递进的:
- Prompt Engineering(最底层):定义代理的身份和角色
- Context Engineering(中间层):管理上下文和工具调用
- Harness Engineering(最上层):编排整个执行环境和循环流程
这种层级关系类似于计算机网络中的协议栈——每一层都依赖下层提供的能力,同时为上层提供更高级的抽象。Prompt Engineering相当于定义了通信的基本语法,Context Engineering管理了信息的路由和检索,而Harness Engineering则负责整个系统的会话管理和流程控制。
现代编程代理的Harness实践
以Cursor为例,我们可以看到Harness思想在现代工具中的具体应用。开发者可以在本地启动Cursor处理任务,同时并发地修复不同功能,每个代理拥有独立的上下文。
更进一步,通过云端代理(Cloud Agents),整个任务可以在云端运行,开发者关闭Cursor后任务依然继续,完成后自动创建Pull Request。结合Slack集成,开发者甚至可以通过消息发送功能需求,代理自动完成并通知。最终形态是完全自主运行——设置自动化规则,让代理每天检查新信息并自主更新。
2025年,这一赛道的竞争进一步白热化:GitHub Copilot推出了Agent模式,Google发布了Jules编程代理,Amazon的CodeWhisperer也在向代理化方向演进。竞争的焦点已从"谁的代码补全更准确"转向"谁的任务编排更智能"——这正是Harness Engineering成为行业热点的直接原因。
这正是Harness Engineering的终极愿景:不是让单个代理变得更聪明,而是通过更好的环境设计和流程编排,让代理系统整体变得更强大。
总结与展望
如今,许多编程代理公司已经在应用内直接集成了Harness层,尽管各家的实现方式不尽相同。这也解释了为什么近期如此多的公司在讨论Agent Harness——因为它确实带来了显著的效果提升。
Agent Harness代表的不仅是一个新术语,更是AI代理工程从"优化单次交互"到"设计执行环境"的范式转变。这种转变的深层逻辑在于:随着AI模型的基础能力趋于同质化,差异化竞争的战场正从模型层上移到工程层。正如云计算时代的竞争从硬件转向了编排(Kubernetes、Docker),AI代理时代的竞争也正在从模型能力转向代理编排。
对于开发者而言,理解并掌握这一范式,将是构建下一代AI应用的关键能力。
核心要点
相关推荐

DeepSeek研究员总结AI智能体使用十大法则
DeepSeek研究员基于AI研究和自主编程实战经验,总结AI智能体(AI Agent)使用的10条通用法则,涵盖角色转变、判断力瓶颈、记忆文件系统、人机协作边界等关键洞察,帮助你高效驾驭AI工具而非被工具掌控。
DeepSeek V4 Flash免费使用教程:Cherry Studio与CC Switch配置指南
DeepSeek V4 Flash限时免费,输入输出token零计费。本文详解OpenModel平台注册流程,以及在Cherry Studio和CC Switch中的完整配置方法,附模型映射与使用场景推荐。

1FlowBase实战:为DeepSeek V4挂载视觉工具实现多模态能力
详解如何通过1FlowBase编排平台,将视觉模型MIMO 2.5作为工具挂载到DeepSeek V4上,实现Fusion多模态入口。涵盖开始节点配置、LM节点设置、工具挂载与条件触发等完整搭建步骤。