Agent Memory:让AI编码代理拥有跨会话持久记忆
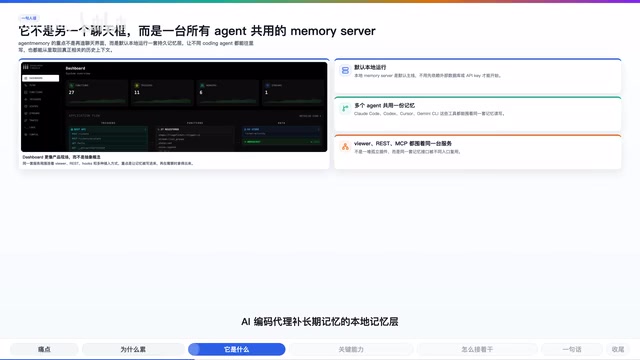
Agent Memory为AI编码代理提供跨工具共享的本地长期记忆层
Agent Memory是一个开源项目(GitHub 10.8k stars),旨在解决AI编码代理每次新会话都需重复解释项目背景的痛点。它在本地构建持久化记忆层,支持Claude Code、Codex、Cursor等多种工具通过MCP协议、插件或REST API共享同一套记忆,具备语义级智能检索能力,代表了AI编码工具从无状态对话向有状态持续协作的演进方向。
每次新会话都要重讲项目背景?这个痛点该解决了
如果你经常用 AI 写代码,一定对这种场景深有体会:明明还是同一个项目,只是换了一个新会话,结果你又得从头解释一遍目录结构、技术决策和历史 Bug。更麻烦的是,很多开发者现在已经不只用一个 Agent——昨天在 Claude Code 里做完鉴权,今天想在 Codex 或 Cursor 里继续推进,但会话一换,上下文就彻底断了。
这一痛点的技术根源在于:当前大语言模型(LLM)本质上是无状态的推理引擎——每次 API 调用都是独立的,模型本身不保存任何会话历史。开发者看到的「对话记忆」实际上是应用层将历史消息拼接进每次请求的 Prompt 中实现的,本质是用 Token 换记忆。这带来两个硬约束:一是上下文窗口有上限(即便 GPT-4 或 Claude 支持数十万 Token,超长上下文也会显著增加延迟和成本);二是跨工具时,各工具维护各自的会话历史,天然割裂。
复制历史上下文当然能凑合,但这样既费 Token,也很容易把无关内容一起塞进去。静态规则文件(如 .cursorrules)也有帮助,但它们更像项目说明书,不像真正会自己生长的记忆。
Agent Memory 就是为了解决这个问题而生的开源项目,目前已在 GitHub 上获得 10.8k stars。它的定位很明确:给 AI 编码代理补上长期记忆的本地记忆层。相当于在 LLM 之外构建了一个持久化的「外部记忆」,从架构上绕开了模型本身无状态的硬限制。
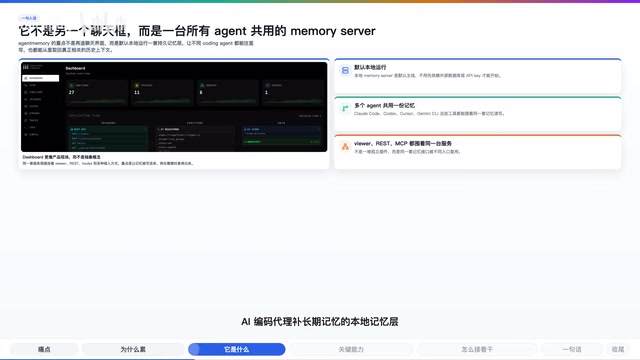
核心定位:不是聊天界面,而是共享记忆服务器
从项目的设计理念来看,Agent Memory 的重点不是再造一个聊天界面,而是做一台所有 Agent 共用的 Memory Server。Claude Code、Codex、Cursor、Gemini CLI 这类工具,都可以往同一套记忆里写入数据,也都可以从中取回真正相关的历史上下文。
换句话说,它不是让你保存一堆笔记,而是想让 Agent 在下一次需要的时候,少一点重新理解,多一点直接接着干活。这个思路的价值在于:记忆不再绑定在某个特定工具的会话里,而是成为项目级别的共享资产。
四大核心能力详解
Agent Memory 最值得关注的能力,主要分为四类:
1. 本地记忆存储服务
你可以把项目里的历史观察、技术偏好和架构决策持续存储下来。这些记忆驻留在本地,不依赖云端服务,既保证了数据隐私,也降低了使用门槛。对于有安全合规要求的团队来说,本地存储是一个关键优势。
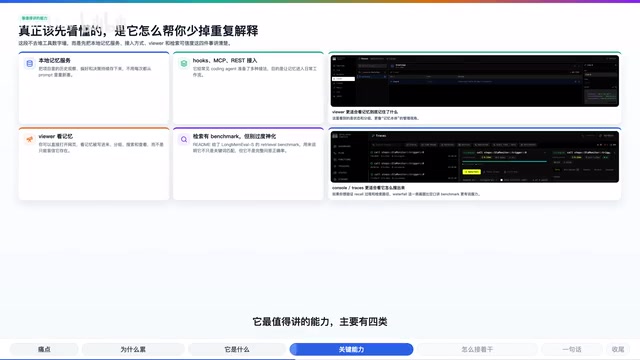
2. 自动接入多种 AI 编码工具
Agent Memory 为主流编码工具准备了多种接入方式,包括插件、Hooks、MCP 协议以及 REST API。
MCP(Model Context Protocol)是由 Anthropic 于2024年底提出并开源的标准化协议,旨在让 AI 模型与外部工具、数据源之间的交互有统一的接口规范。在此之前,每个 AI 编码工具都有自己的插件或扩展机制,彼此互不兼容。MCP 的出现类似于 AI 工具领域的「USB 标准」——只要支持 MCP,记忆服务、代码执行环境、数据库查询等能力就可以被任意兼容的 Agent 调用。目前 Claude Code、Cursor 等主流工具均已宣布或实现 MCP 支持,这为 Agent Memory 这类跨工具基础设施的普及提供了协议层保障。
这意味着无论你用的是 Claude Code、Codex、Cursor 还是其他 Agent,都能以最低成本接入同一套记忆系统,实现真正的跨工具记忆共享。
3. 实时 Viewer 可视化面板
项目自带一个网页端的实时 Viewer,你能直接打开浏览器,查看记忆是怎么被写入、搜索和回放的。这不仅方便调试,也让开发者对记忆系统的运作方式有直观的理解。
4. 语义级智能检索
Readme 中给出了 Long-term Memory Retrieval Benchmark 的数据,用来说明它不是只会做机械的关键词匹配,而是具备语义级别的检索能力。
语义级检索(Semantic Retrieval)与传统关键词匹配的核心区别在于:它通过向量嵌入(Vector Embedding)将文本转化为高维空间中的数值向量,使得语义相近的内容在向量空间中距离更近。这一技术依托于 RAG(Retrieval-Augmented Generation,检索增强生成)架构——先从记忆库中检索最相关的历史片段,再将其注入当前对话上下文,从而让 Agent 在不消耗大量 Token 的前提下获得精准的历史信息。这意味着,即使你描述问题的措辞与当初存储记忆时不同,系统仍能找到真正相关的历史决策,而不是只会匹配完全相同的关键词。
不过正如原作者所说,真正该先看懂的不是跑分数字,而是它帮你省掉了多少重复解释。
实际场景:连续两天推同一个后端项目
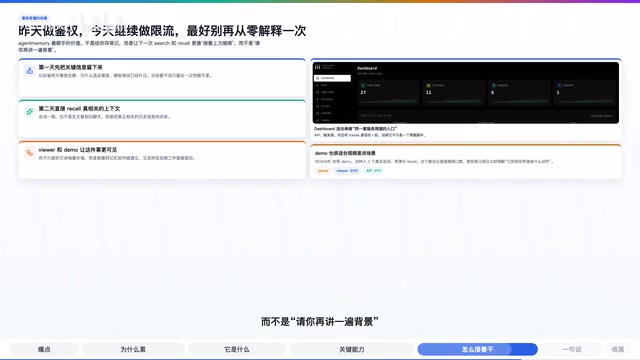
一个最容易理解的使用场景是这样的:你连续两天用 Agent 推进同一个后端项目。
- 第一天:让 Agent 接好 JWT 鉴权,完成核心认证逻辑,补上相关测试。
- 第二天:继续让 Agent 做限流或者性能优化。
正常情况下,新会话一开,Agent 又得重新理解认证方案放在哪、为什么选这套库、测试补到了哪里。而有了 Agent Memory,这些历史信息会留在本地记忆里,下一次的搜索和 Recall 更像是接着上次继续,而不是"请你再讲一遍背景"。
这个场景还可以进一步延伸:当团队中多人协作,不同成员使用不同的 AI 编码工具时,共享记忆层的价值会更加明显。一个人在 Claude Code 中做出的架构决策,另一个人在 Cursor 中可以直接获取到,避免了信息孤岛。
这个方向为什么值得关注
从更宏观的视角来看,Agent Memory 代表的是 AI 编码工具发展中一个重要的演进方向:从无状态的单次对话,走向有状态的持续协作。
当前主流的 AI 编码工具,本质上都是"无记忆"的——每次会话都是一张白纸。虽然部分工具开始支持项目级别的上下文文件,但这些静态配置远不能替代动态积累的项目记忆。Agent Memory 试图填补的,正是这个从"静态配置"到"动态记忆"之间的空白。
值得注意的几个趋势:
- 多 Agent 协作正在成为常态:越来越多的开发者同时使用多个 AI 工具,跨工具的记忆共享需求只会越来越强烈。
- MCP 协议的普及:标准化的接入协议让记忆层与不同 Agent 的集成变得更加顺畅。Anthropic 将 MCP 开源并推动行业采纳,正在形成类似 HTTP 之于 Web 的基础协议地位。
- 本地优先的隐私策略:将记忆存储在本地而非云端,既符合企业安全要求,也降低了数据泄露风险。
总结
一句话概括:Agent Memory 是一个给 AI 编码代理补上长期记忆的本地层。它想解决的核心问题,不是多加几个工具入口,而是别让你在同一个项目里一遍遍给 AI 重讲项目背景。
如果你已经开始同时使用多个 Coding Agent,或者经常因为会话中断而浪费时间重复解释上下文,这个项目非常值得尝试。10.8k 的 star 数也说明,这个痛点确实击中了大量开发者的真实需求。
核心要点
- Agent Memory 是一个本地记忆层,解决 AI 编码代理每次新会话都需要重新解释项目背景的痛点
- 支持 Claude Code、Codex、Cursor 等多种 Agent 共享同一套记忆,通过插件、MCP、REST API 等方式接入
- 四大核心能力:本地记忆存储、多 Agent 自动接入、实时 Viewer 可视化、语义级智能检索
- 代表了 AI 编码工具从无状态单次对话向有状态持续协作演进的重要方向
- 项目已获 GitHub 10.8k stars,本地优先的存储策略兼顾了隐私安全和使用便捷性
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。