Agent Middleware机制:为模型调用加装拦截器
在构建 AI Agent 时,我们经常需要在模型调用的前后插入自定义逻辑——比如记录日志、做安全检查、甚至直接拦截危险请求。这时候,Middleware(中间件) 机制就派上了用场。它就像一个拦截器,能在 Agent 模型调用的生命周期中灵活地插入你想要的任何逻辑。
本文将通过两个实战案例——日志记录中间件和安全检查中间件,带你彻底搞懂 Middleware 的工作原理和使用方式。
什么是 Agent Middleware?
Middleware 本质上是一种**面向切面编程(AOP)**的思想在 Agent 框架中的应用。它允许你在模型调用之前(Before Model)和模型调用之后(After Model)两个关键节点插入自定义逻辑,而不需要修改 Agent 本身的核心代码。
面向切面编程(Aspect-Oriented Programming, AOP)最早由 Xerox PARC 的 Gregor Kiczales 团队在1997年提出,其核心思想是将横切关注点(Cross-Cutting Concerns)从主业务逻辑中分离出来。在传统软件开发中,日志、事务管理、安全验证等功能往往散布在各个模块中,导致代码重复和耦合度升高。AOP 通过定义切点(Pointcut)和通知(Advice),让这些横切逻辑可以集中管理、统一织入。在 AI Agent 框架中,模型调用就是天然的切点——每次 LLM 推理都是一个明确的执行边界,非常适合在其前后插入额外逻辑。这与 Java Spring 框架中的拦截器、Python Django 中的中间件、以及 Node.js Express 中的 middleware 链式调用本质上是同一种设计哲学的不同实现。
这种设计的好处显而易见:
- 解耦:日志、安全检查等横切关注点与业务逻辑分离
- 可组合:多个 Middleware 可以叠加使用,互不干扰
- 灵活控制:既可以只做"旁观者"(记录日志),也可以做"守门人"(拦截请求)
实战一:日志记录中间件
第一个 Middleware 的目标很简单——记录模型调用前后的关键信息,方便调试和追踪对话进度。
Before Model:调用前记录
定义一个类继承 AgentMiddleware,实现 before_model 方法。在模型调用之前,打印当前消息列表的长度,这样就能清楚地知道对话进行到了第几轮。
这里的 AgentMiddleware 基类采用了模板方法模式(Template Method Pattern),这是 GoF 设计模式中的经典行为型模式。基类定义了 before_model 和 after_model 两个钩子方法的签名和默认行为,子类通过覆写这些方法来注入具体逻辑。这种设计在 Python 中尤为自然,因为 Python 支持鸭子类型和抽象基类(ABC),开发者可以选择只覆写需要的钩子而忽略其他。生命周期钩子的概念在前端框架(如 React 的 useEffect、Vue 的 onMounted)和后端框架中都有广泛应用,其本质是控制反转(IoC)——框架决定何时调用你的代码,而不是你主动调用框架。
这里有一个关键细节:返回类型是 None。因为日志中间件只是一个"旁观者",它不需要干预任何流程。返回 None 就是在告诉框架:"我只是看看,你继续往下走。"
值得注意的是,这里打印的"消息列表长度"涉及 LLM 对话的核心数据结构。在 OpenAI 等主流 API 中,每次调用都需要传入完整的消息历史(messages),包括 system、user、assistant 等角色的消息。消息列表的长度直接影响 Token 消耗和上下文窗口的利用率。随着对话轮次增加,消息列表会不断膨胀,可能触及模型的上下文长度限制(如 GPT-4o 的 128K tokens)。因此,监控消息列表长度不仅是调试手段,也是上下文管理策略的重要依据——当列表过长时,可能需要触发消息压缩或滑动窗口截断。
After Model:调用后记录
after_model 方法在模型响应之后执行。我们可以取最后一条消息,截取前 50 个字符打印出来,快速预览模型的回复内容。
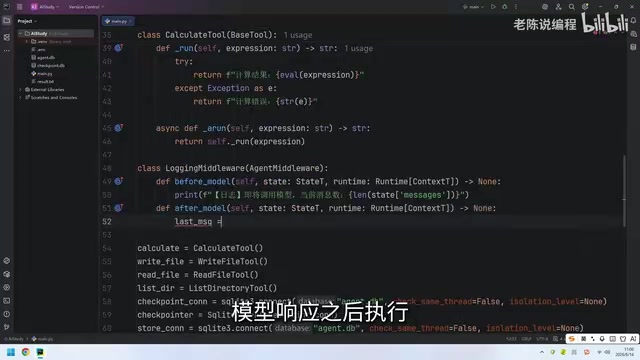
这种做法在调试阶段非常实用,能让你在不打开完整日志的情况下快速了解模型的行为。
实战二:安全检查中间件
第二个 Middleware 就不只是"看看"了——它是一个真正的守门人,负责拦截危险操作。
关键区别:返回类型的变化
同样继承 AgentMiddleware,但重点在 before_model 方法的实现上。与日志中间件最大的不同在于:返回类型是 Dict | None,而不是单纯的 None。
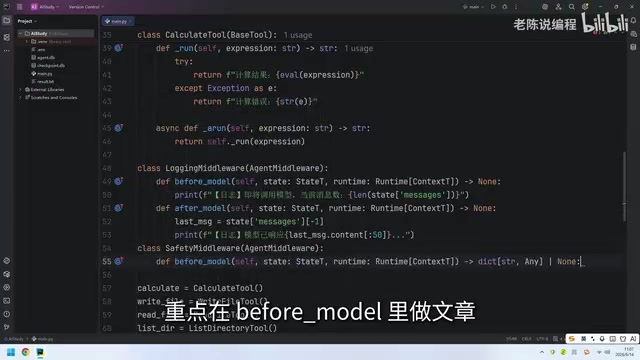
为什么要这样设计?因为安全检查中间件有可能需要主动干预流程。当它发现问题时,需要通过返回一个字典来告诉框架该怎么做。这种设计模式在计算机科学中被称为"短路求值"(Short-Circuit Evaluation)或"提前返回"(Early Return)。在 Agent 框架的上下文中,这意味着中间件可以完全绕过 LLM 推理过程,直接注入预设响应。这种能力在生产环境中极为重要:一方面可以避免将敏感内容发送给外部 API(减少数据泄露风险),另一方面可以节省不必要的 API 调用成本(每次 LLM 调用都有 Token 费用)。从架构角度看,这类似于 HTTP 中间件返回 403 Forbidden 直接拒绝请求,而不是让请求继续到达后端服务。
拦截逻辑的具体实现
具体的检查逻辑如下:
- 获取最后一条用户消息的内容
- 检查其中是否包含"删除"或"危险"等敏感关键词
- 如果命中,返回一个包含控制指令的字典
需要指出的是,这里使用的关键词匹配是最基础的内容过滤方案,在生产环境中通常不够健壮。用户可以通过同义词替换、拼音输入、Unicode 混淆、Prompt 注入等方式轻松绕过简单的字符串匹配。更成熟的方案包括:基于正则表达式的模式匹配、使用 TF-IDF 或 BERT 等模型进行语义级别的意图识别、调用专门的内容安全 API(如 OpenAI 的 Moderation API、Azure Content Safety)、以及构建多层级的安全防护体系(输入过滤 + 输出审核 + 行为监控)。在 AI Agent 场景中,还需要特别关注工具调用(Tool Use)层面的安全——即使用户消息本身无害,Agent 自主决策调用的工具操作也可能带来风险。
返回的字典中包含两个关键字段:
jump_to: "end":告诉框架跳过模型调用,直接结束当前流程- 一条 AI Message:塞入一条预设的回复消息,告知用户操作已被终止
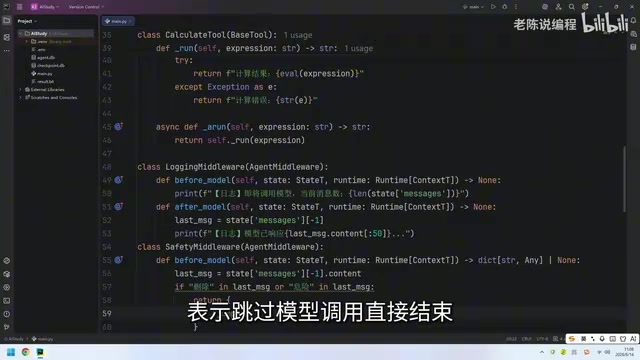
这个返回值的含义非常明确:别调用模型了,直接结束,并且把这条安全提示消息加到对话中。 如果检查通过没有问题,则返回 None,表示"我没意见,流程正常继续"。
组合使用:让 Agent 同时具备多种能力
最后一步是将两个 Middleware 组合起来,一起传给 create_agent:
agent = create_agent(
model=model,
middleware=[LoggingMiddleware(), SecurityMiddleware()]
)
这样,Agent 就同时具备了日志记录和安全拦截两种能力。每次模型调用时,请求会依次经过所有 Middleware 的 before_model,响应则会依次经过所有 Middleware 的 after_model。
当多个 Middleware 被组合使用时,它们的执行遵循类似洋葱模型(Onion Model)的顺序。请求阶段(before_model)按照注册顺序依次执行,响应阶段(after_model)则按照相反顺序执行,形成一个对称的调用栈。这种模式在 Web 框架中非常常见,例如 Koa.js 的中间件机制。具体到上面的例子,before_model 的执行顺序是 Logging → Security,而 after_model 的执行顺序是 Security → Logging。这意味着安全检查中间件如果在 before_model 阶段拦截了请求,后续的模型调用和所有 after_model 逻辑都不会执行。理解这个执行顺序对于正确设计中间件的注册顺序至关重要。
Middleware 的两种角色:旁观者与守门人
通过这两个案例,我们可以总结出 Middleware 的两种典型角色:
| 角色 | 返回值 | 典型场景 |
|---|---|---|
| 旁观者(Observer) | 始终返回 None | 日志记录、性能监控、数据统计 |
| 守门人(Guardian) | 条件返回 Dict | 安全检查、权限验证、内容过滤 |
这种设计模式的精妙之处在于:通过返回值类型的不同来区分中间件的职责。返回 None 意味着放行,返回 Dict 意味着接管控制权。这让框架能够用统一的接口支持截然不同的使用场景。
在实际项目中,你还可以扩展出更多类型的 Middleware,比如:
- Token 计数中间件:统计每次调用消耗的 Token 数
- 缓存中间件:对相同问题直接返回缓存结果
- 限流中间件:控制模型调用频率
- 内容审核中间件:对模型输出进行合规性检查
其中,缓存中间件的实现尤其值得深入探讨。其核心挑战在于如何定义"相同问题"——LLM 的输入是自然语言,语义相同但表述不同的问题(如"今天天气怎样"和"今天天气如何")应该命中同一缓存。常见的实现策略包括:精确匹配(对输入做哈希)、语义匹配(使用 Embedding 模型计算相似度并设定阈值)、以及基于 LLM 自身的语义缓存(如 GPTCache)。缓存还需要考虑失效策略(TTL、LRU)和一致性问题——当 Agent 的系统提示词或工具集发生变化时,旧缓存可能不再适用。OpenAI 在 2024 年推出的 Prompt Caching 功能从 API 层面部分解决了这个问题,对相同前缀的 Prompt 自动提供 50% 的价格折扣。
在生产环境中部署这些中间件时,还需要考虑几个关键的工程问题。首先是性能开销:每个中间件都会增加调用延迟,特别是涉及 I/O 操作(如写入日志数据库、调用外部审核 API)的中间件应该采用异步执行。其次是错误处理:中间件本身的异常不应该导致整个 Agent 崩溃,需要有完善的 try-catch 机制和降级策略。第三是可观测性:中间件的执行状态本身也需要被监控,形成元监控(Meta-Monitoring)。
此外,当系统从单 Agent 扩展到多 Agent 协作架构时,中间件的设计复杂度会显著提升。在 LangGraph、CrewAI、AutoGen 等多 Agent 框架中,Agent 之间存在消息传递、任务委托、结果汇总等交互模式。中间件不仅需要拦截单个 Agent 的 LLM 调用,还可能需要监控 Agent 间的通信、追踪跨 Agent 的调用链路(类似微服务中的分布式追踪)、以及在 Agent 编排层面实施全局策略(如总 Token 预算控制、全局超时管理)。OpenTelemetry 等可观测性标准正在被引入 AI Agent 领域,用于实现端到端的调用链追踪和性能分析。目前主流的 Agent 框架如 LangChain 的 Callbacks、OpenAI Agents SDK 的 Hooks 机制,本质上都是中间件思想的不同实现形式。
Middleware 机制让 Agent 的能力扩展变得模块化、可插拔,是构建生产级 AI Agent 不可或缺的基础设施。
核心要点
- Middleware 是 AOP 思想在 Agent 框架中的实现,通过 before_model 和 after_model 两个钩子在模型调用前后插入自定义逻辑
- 旁观者模式(返回 None)适用于日志、监控等不干预流程的场景
- 守门人模式(返回 Dict)适用于安全检查、权限验证等需要拦截流程的场景
- 多个中间件按洋葱模型顺序执行,注册顺序决定了执行优先级
- 生产环境中需要关注中间件的性能开销、错误隔离和可观测性
- 基础的关键词匹配在安全场景中不够健壮,生产环境应采用语义级别的内容安全方案
- 缓存中间件需要解决语义相似度匹配和缓存失效等核心挑战
- 多 Agent 协作场景下,中间件需要扩展到 Agent 间通信和全局策略管理层面
相关推荐

美国国会候选人回应删除3500条推文争议:修辞与价值观的反思
美国国会候选人Chevalier回应删除3500条推文争议,澄清并非因竞选删帖,坦承对过往措辞感到遗憾,强调统一、可及、善意的政治语言理念,折射社交媒体时代政治人物面临的数字足迹困境。
Claude Code Workflow实战:上百个Agent自动迁移PHP到Golang
深度解析Claude Code Workflow多Agent自动编排功能,实战演示PHP项目迁移Golang全过程。连续运行14小时调用上百个Agent,从规划到执行全自动化,详解适用场景与Token成本分析。
Fable 5:首个拥有"魔法气质"的AI模型意味着什么
Fable 5被用户称为首个拥有"magic model smell"的AI模型,本文解析这种魔法气质背后的含义,探讨AI模型评估从性能指标走向体验质量的行业新趋势。