Agent Skills:文件夹即技能,让AI按模板精准输出

当你给大模型一个复杂任务,它总是花样百出地犯错——编造内容、遗漏细节、格式混乱。你花了大量时间和模型纠错,效率极低。Agent Skills 正是为解决这个痛点而生的技术方案:将AI的能力拆分成独立的技能文件夹,按需动态加载,让大模型按照你的模板直接生成最终成果。
传统Agent开发的三大困境
在传统的Agent开发模式中,开发者需要给AI提供海量的提示词来对齐需求。通常的做法是将整个企业的所有文档、规则和工具说明一股脑儿传给大模型,形成动辄数千行的超长上下文。这带来了三个严重问题:
成本爆炸:每次API调用都需要携带完整上下文,token费用指数级增长。一个原本几分钱的请求,因为携带了大量无关信息,成本可能翻几十倍。要理解这个问题的严重性,需要了解token的计费机制:Token是大语言模型处理文本的基本单位,中文大约每1-2个字对应一个token,英文则大约每4个字符对应一个token。当前主流模型如GPT-4o、Claude 3.5等虽然支持128K甚至更长的上下文窗口,但token消耗与API调用成本直接挂钩——以GPT-4o为例,输入token的价格约为每百万token 2.5美元,输出token约为10美元。更关键的是,研究表明模型在处理超长上下文时存在"Lost in the Middle"现象:位于上下文中间位置的信息更容易被忽略,这意味着塞入更多信息不仅增加成本,还可能降低输出质量。
幻觉加剧:信息过载严重分散了模型的注意力。当AI面对数千行文档时,它反而更容易编造内容,输出质量急剧下降。这不是模型能力不足,而是我们给它的负担太重了。从技术角度来看,大模型幻觉(Hallucination)是指模型生成看似合理但实际上不正确或无中生有的内容。其根本原因在于大语言模型的工作机制是基于概率的下一个token预测,而非真正的知识检索。当模型面对过多信息时,注意力机制(Attention Mechanism)需要在海量token之间分配权重,导致对关键信息的关注度被稀释。斯坦福大学2023年的研究表明,随着输入上下文长度增加,模型在事实性任务上的准确率呈现明显下降趋势。这也是为什么RAG(检索增强生成)和Agent Skills这类"精准投喂"策略比"全量灌入"策略更有效的底层原因。
维护噩梦:数千行的提示词难以管理,每次业务变更都要手动修改。多人协作时冲突频发,几乎不可能高效协同。

Agent Skills的核心设计:文件夹即技能
Agent Skills的核心思想非常优雅——把AI的能力拆分成独立的技能文件夹,按需动态加载。只有当AI需要某项技能时,才会加载对应的内容。
标准Skill文件夹结构
一个标准的Skill文件夹包含以下部分:
- skill.md(必须):用Markdown编写的技能说明书,包含元数据、使用场景和执行流程
- scripts/:存放Python代码或脚本,为大模型提供工具函数
- references/:存放详细文档和示例,供模型在需要时查阅
- assets/:静态资源文件夹,放置图片、配置文件等
以"点咖啡"技能为例:当大模型决定使用这个技能后,它会先阅读skill.md了解整体流程,当流程中提到"如需了解下单步骤,请查看references/order_coffee.md"时,模型才会去读取那份详细文档。这就是按需加载的精髓。
团队协作与版本管理
这种文件夹结构天然支持团队分工:开发者负责编写scripts中的工具函数和API封装;产品经理或业务专家负责编写skill.md和整理reference参考资料;AI模型负责阅读指令、调用工具、查阅资料并执行任务。更重要的是,整套技能可以通过Git进行版本管理,多人并行开发互不冲突。这种将AI能力"代码化"的做法,使得提示词工程第一次具备了软件工程的成熟度——可以进行代码审查(Code Review)、分支管理、回滚操作,甚至可以编写自动化测试来验证Skill的输出质量。
渐进式披露:token成本与输出质量的双重优化
有人可能会问:Skill本质不还是提示词吗?为什么它就不会造成上下文过载?答案在于「渐进式披露」机制。
渐进式披露(Progressive Disclosure)最初是人机交互领域的经典设计原则,由IBM研究员John M. Carroll在1980年代提出,核心理念是"只在用户需要时才展示信息"。这一原则在软件界面设计中被广泛应用——例如Photoshop的菜单层级、手机设置的分级展开等。Agent Skills将这一理念迁移到了AI提示词工程中:不是一次性把所有指令和参考资料塞给模型,而是建立一个分层索引结构,让模型根据任务需要逐步"展开"所需信息。这与计算机科学中的"懒加载"(Lazy Loading)策略异曲同工——只在真正需要时才分配资源。
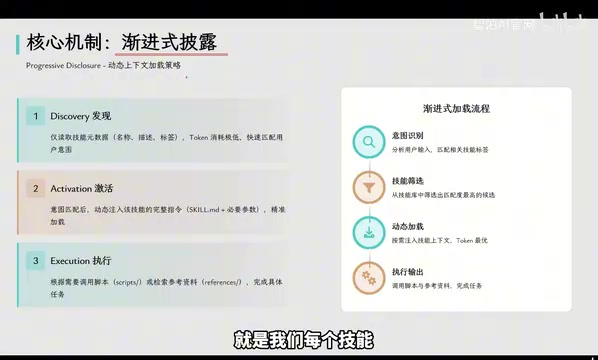
三阶段加载策略详解
第一阶段:元数据索引。每个Skill的skill.md第一行是元数据,只包含技能名称和触发条件(如"当用户需要下咖啡订单时")。系统启动时,大模型只读取所有Skill的元数据,了解自己有哪些技能可用。元数据极其简短,token消耗极低。
第二阶段:意图匹配激活。当用户说"帮我下一杯美式咖啡",大模型识别到意图匹配"下咖啡订单"这个技能,此时才完整加载该Skill的skill.md说明书和必要参数。这个阶段的意图匹配本质上类似于搜索引擎的查询-文档匹配过程,模型通过语义理解将用户输入与技能元数据中的触发条件进行比对,选择最相关的技能进行激活。
第三阶段:脚本执行。当任务需要执行代码时(比如调用下单API),大模型只需表达"我要执行这个脚本"的意图。系统在独立的虚拟环境中运行代码,将结果返回给模型。整个过程中,大模型完全看不到代码内容,不占用任何token。这种设计巧妙地将"决策"与"执行"分离——模型负责理解需求和编排流程(它擅长的部分),而具体的代码执行交给确定性的运行时环境(避免模型在代码生成中出错)。
这套机制带来的效果是:token占用降低80%,大模型幻觉大幅减少,输出质量显著提升。
实战演示:从零构建一个芯片测评Skill

用Kimi快速生成Skill文件
你不需要从零手写所有文件。以下是一个快速构建Skill的实操流程:
- 打开agentskills.io网站,进入Specification页面,点击"Copy Page"复制完整的Skill开发规范
- 打开Kimi(使用K2.5 Agent功能),告诉它你的需求:"帮我编写一个Agent Skill,用于生成专业的科技产品芯片测评文档"
- 将规范文档粘贴给Kimi,让它按照标准格式生成完整的Skill文件
Kimi是月之暗面(Moonshot AI)推出的大语言模型产品,其K2.5版本具备Agent模式,能够自主进行网页搜索、信息整合和多步骤任务执行。在这个实战案例中,Kimi的Agent能力体现在两个层面:一是它能够理解Agent Skills的规范文档并按照标准格式生成结构化输出;二是它会主动搜索互联网上的芯片测评文章,学习真实的测评方法论和写作范式,从而生成更专业、更贴近实际的Skill模板。这种"先学习再生成"的工作模式,本身就是Agent能力的典型应用。
Kimi会自动搜索相关网页,了解真实的芯片测评是怎么做的,然后为你生成完整的Skill文件夹结构:skill.md主技能文档、CPU详细文档、GPU详细文档、架构分析文档、功耗散热分析文档等。
在Dify工作流中部署与测试
生成的Skill文件下载后,直接上传到Dify工作流平台即可完成"技能安装"。Dify是一个开源的大语言模型应用开发平台,提供了可视化的工作流编排界面,允许开发者通过拖拽节点的方式构建复杂的AI应用流程。它支持接入OpenAI、Anthropic、本地部署模型等多种LLM后端,并内置了知识库管理、工具调用、变量传递等功能。在Agent Skills的使用场景中,Dify充当了"技能运行时"的角色——开发者将Skill文件上传为知识库文档,通过工作流节点实现意图识别、技能匹配和结果生成的自动化流程。相比纯代码开发,Dify大幅降低了AI应用的部署门槛。
测试时输入"请帮我编写一个RTX 3060的芯片测评文档",AI会自动匹配技能、阅读references中的引导材料,生成标准化的测评报告——包含芯片规格、架构分析、技术亮点、性能基准测试、游戏测试数据、功耗散热等完整章节。
关键在于:这个Skill完全固定了AI的工作方式,让它始终生成规范的结果,从根源上避免了内容编造和格式混乱。
总结:结构化提示词工程的最佳实践
Agent Skills的价值可以用一句话概括:以极低的token成本,换取极高的任务准确度。它不是一个全新的技术范式,而是对提示词工程的结构化升级——通过文件夹组织、渐进式披露和按需加载,把"一坨巨大的Prompt"变成了可管理、可协作、可复用的技能模块。
从更宏观的视角来看,Agent Skills代表了AI应用开发从"手工作坊"走向"工业化生产"的重要一步。正如软件工程从早期的意大利面条式代码演进到模块化、面向对象的架构,提示词工程也正在经历类似的范式转变。Agent Skills通过引入清晰的文件结构、职责分离和版本管理,让AI能力的开发和维护第一次具备了工程化的可能性。
当前,Agent Skills已经可以在Cloud Code、VS Code插件、Cursor IDE、Dify工作流、LangChain框架等多种平台中使用。对于需要频繁与AI协作的团队来说,这项技术值得尽早引入到日常工作流中。
相关推荐
AI大模型学习路线拆解:三阶段从应用开发到模型微调
深度拆解一条热门AI大模型学习路线,涵盖LangChain应用开发、RAG检索增强生成、Agent智能体、LoRA模型微调等核心技术栈,分析三阶段规划的合理性与局限性,为转型者提供理性参考。

AI Agent智能体开发:六周系统学习路线全解析
从零开始学AI Agent智能体开发,六周系统学习路线涵盖核心架构、ReAct原理、多智能体协作、RAG融合到实战部署,帮你建立完整知识体系,避开常见学习误区。
前端开发者转型AI Agent开发的四大核心优势
前端开发者转型AI Agent开发具备TypeScript生态适配、全栈衔接低门槛、状态管理同构性等核心优势。本文详解前端转AI Agent的可行路径与推荐学习路线。