Agentic RAG实战指南:从传统RAG到智能体检索的完整进化
Agentic RAG通过工具化和智能体决策升级传统RAG,实现多轮迭代的智能检索生成。
传统RAG是固定的单向流水线,检索失败时无法自我调整。Agentic RAG将检索、文件读取等能力封装为工具,赋予大模型自主决策和多轮迭代能力,形成"思考→调用工具→观察→再行动"的智能闭环。文章通过ChatPDF案例和LangGraph代码实战,展示了Agentic RAG如何解决传统RAG检索不到就放弃的核心痛点。
传统RAG为什么不够用
你是否遇到过这样的情况:花了大量时间搭建的RAG系统,模型的回答却答非所问?检索到一堆看似相关却毫无用处的内容?当用户问"你有哪些文档"时,系统直接宕机——因为它只会查,不会想?检索不到答案时就开始"摆烂",而不是尝试换一种问法?
这些问题的根源在于:传统RAG是一条固定的流水线,缺乏灵活性和自主决策能力。 2025年被称为Agent元年,Agentic RAG正在成为大模型工程师的必备技能。本文将从传统RAG出发,逐步揭秘它如何进化为Agentic RAG,并通过代码实战带你掌握其核心实现。
传统RAG的实现原理
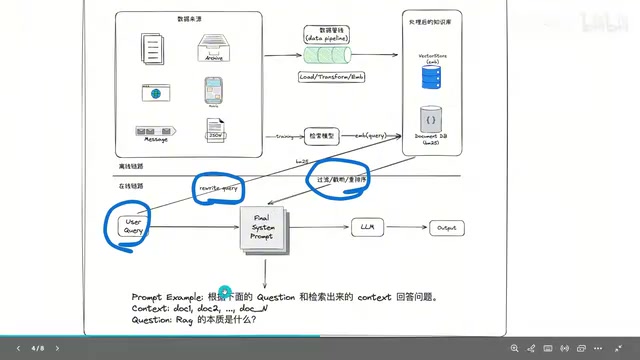
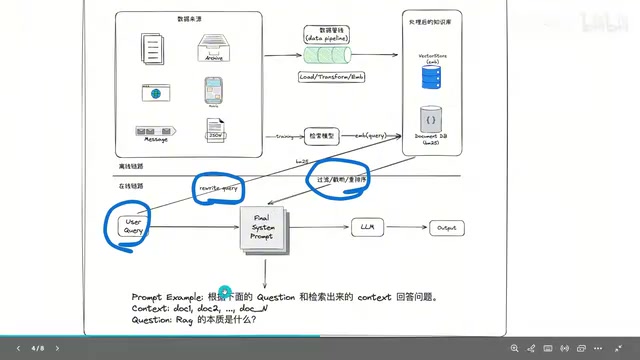
传统RAG(检索增强生成)可以分为两条流水线:离线链路和在线链路。理解这两条链路,是掌握Agentic RAG升级逻辑的前提。
RAG(Retrieval-Augmented Generation)最早由Meta AI在2020年提出,其核心动机是解决大语言模型的知识截止问题和幻觉问题。大模型的参数化知识是静态的,训练完成后无法自动更新,而RAG通过在推理时动态检索外部知识库,将最新、最相关的信息注入生成过程,从而让模型的回答更加准确和可靠。这一范式迅速成为企业级AI应用的标配架构,几乎所有需要基于私有数据回答问题的场景都会用到RAG。
离线链路:文档切片→向量化→存储
离线链路与用户无关,属于数据预处理阶段。具体流程如下:
- 文档加载:将PDF、Word、TXT等文档加载到内存中
- 文本切片:由于文档内容可能有上万字,无法一次性全部交给大模型,因此需要将文档切分成固定长度的段落(如256个字符),段落之间可以设置一定的重叠区域
- 向量化:使用Embedding模型将每个段落转换为固定维度的向量表示
- 存储:将向量存入向量数据库(如Chroma、Milvus等)
其中,Embedding模型(如OpenAI的text-embedding-ada-002、BGE系列、千问Embedding等)的作用是将文本映射到高维向量空间中,使得语义相近的文本在向量空间中距离更近。向量检索通常使用余弦相似度或内积作为度量标准,通过ANN(近似最近邻)算法实现毫秒级检索。在向量数据库的选择上,Chroma适合轻量级原型开发和本地实验,Milvus和Pinecone则面向生产级大规模场景,支持分布式部署和亿级向量的高效检索。
在线链路:检索→拼接Prompt→生成
当用户提出问题后,在线链路开始工作:
- Query改写:用户的原始问题可能不适合直接检索,需要进行改写以提升检索召回率
- 双路检索:先用BM25进行关键词检索,再用Embedding模型进行语义向量检索
- 合并与重排序:将两路检索结果合并后进行重排序(Rerank),选出最相关的片段
- Prompt拼接:将检索到的文档片段注入Prompt模板的Context部分
- 大模型生成:模型根据Prompt生成最终答案
关于双路检索的设计逻辑:BM25是一种基于词频-逆文档频率(TF-IDF)改进的经典信息检索算法,擅长精确匹配关键词和专有名词。而语义向量检索擅长理解同义词和语义关联。两者结合的混合检索(Hybrid Search)能显著提升召回率——例如用户搜索"心脏病"时,BM25能精确匹配该词,而语义检索还能召回包含"冠心病""心肌梗塞"等相关内容的片段。Rerank模型(如Cohere Reranker、BGE-Reranker)则在合并结果后进行精排,确保最终返回的片段与用户问题高度相关。
传统RAG的Prompt模板非常简单,核心就是:"你是一个专业助手,请根据以下问题和检索回来的文档进行回答。" 加上Context(检索到的Top-K文档片段)和用户问题。
传统RAG的核心问题在于:整个过程是单向、固定、一次性的。 第一轮检索如果没有找到想要的内容,模型无法重新检索或换一种方式提问,更无法调用其他工具获取补充信息。
Agentic RAG:从流水线到智能体的根本性升级
Agentic RAG的核心思想
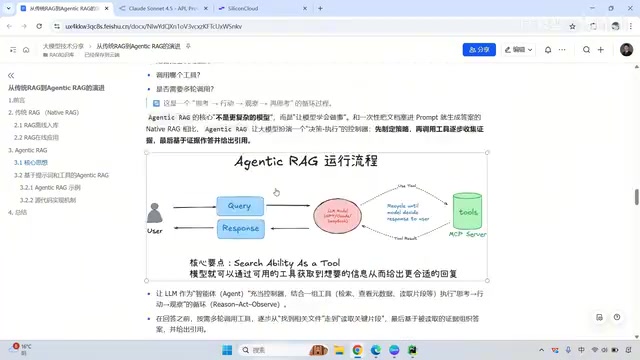
Agentic RAG是对传统RAG流程的根本性升级。它的核心思想是:将RAG中的各个环节(Query改写、向量检索、关键词搜索等)全部封装成可调用的工具(Tool),并赋予大模型自主决策、多轮调用和动态调整的能力。
这里的"工具调用"能力(Tool Calling/Function Calling)是OpenAI在2023年引入的关键技术突破,随后被各大模型厂商跟进。其原理是在模型推理时,除了生成自然语言文本外,还能输出结构化的函数调用指令(包含函数名和参数的JSON)。模型通过专门的训练学会了何时应该调用工具、调用哪个工具以及如何构造参数。这一能力是Agentic RAG能够实现自主决策的技术基础——没有Function Calling,模型就无法与外部系统进行结构化交互。
换句话说,Agentic RAG不再是一条直线走到底,而是一个可以循环的智能体行为闭环:思考→调用工具→观察结果→再思考→再行动,直到生成满意的最终答案。
这一行为模式本质上是ReAct(Reasoning + Acting)框架的实现。ReAct由Yao等人在2022年提出,它将Chain-of-Thought推理与外部工具交互交替进行,让模型在每一步都能基于观察到的真实反馈调整策略。相比纯推理(容易产生幻觉)或纯行动(缺乏规划),ReAct在复杂任务上表现更稳定,因为每次工具调用的结果都为下一步推理提供了真实的"锚点",有效减少了错误累积。
传统RAG vs Agentic RAG运行流程
传统RAG的流程:用户提问 → 检索 → 拼接Prompt → 生成答案(一次性完成,无法回头)
Agentic RAG的流程:
- 用户提出问题
- 将问题直接交给大模型(GPT、Claude、DeepSeek等)
- 模型自主判断是否需要调用工具
- 调用工具后获取结果,模型根据结果决定下一步——继续调用工具还是直接回答
- 循环迭代,直到信息充分后生成最终答案
Agentic RAG的三大核心能力
Agentic RAG的实现依赖模型具备以下三类核心能力:
- 规划能力(Planning):体现在Chain-of-Thought推理过程中,模型能够规划执行步骤、评估中间结果的质量
- 工具调用能力(Tool Calling):模型能够调用各种外部工具,也可以与多个Agent协作完成复杂任务
- 多步迭代能力:模型可以在生成最终答案之前进行多步工具调用,逐步完善信息拼图
ChatPDF的Agentic RAG实现解析
整体架构设计
开源项目ChatPDF(ChatBoss)的实现方式非常值得参考。它的核心设计理念是:用时间换取模型的智能。
当用户问题发过来后,系统首先判断模型是否支持工具调用:
不支持工具调用的情况: 通过Prompt判断问题是否需要检索。如果不需要检索,直接回复;如果需要,则进行语义搜索后注入Context再生成答案。这种方式比在Prompt中让模型忽略无关Context更优,因为使用了两个独立的模型做决策。
支持工具调用的情况: 将所有工具集合注册到模型中,让模型自主决策调用哪些工具——语义检索工具、文件列表工具、文件读取工具等。所有决策权交给模型,而非固定流程。
四个核心工具详解
ChatBoss设计了四个核心工具,每个工具解决传统RAG的一个痛点:
- Search Query(语义检索工具):最基本的语义检索功能,根据用户Query在向量数据库中搜索相关片段
- List Files(文件列表工具):列出知识库中的文件清单。传统RAG无法回答"知识库里有哪些文档"这类问题,因为它只能检索片段内容。有了这个工具,模型可以获取文件数量和完整列表
- Read File(精确读取工具):根据文档ID精确读取特定片段。当发现信息不完整时,模型可以主动读取前后片段补充上下文,不依赖语义相似度
- Gather File Meta(元数据读取工具):获取文件的元数据信息,如文件名、创建时间、大小等
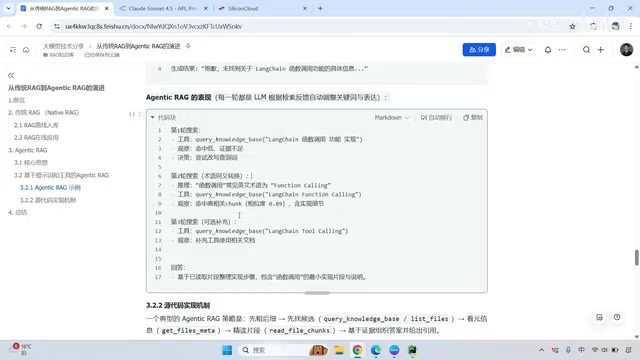
实际效果对比:同一问题的不同表现
以一个具体案例说明传统RAG和Agentic RAG的差异:
传统RAG的处理方式:用户查询 → 向量检索 → 检索结果 → 生成答案。如果第一次检索命中率低,就直接返回"未找到相关信息",用户体验很差。
Agentic RAG的处理方式:
- 第一轮搜索:使用原始Query进行检索,发现命中率很低
- 观察与改写:模型观察到结果不理想,主动改写查询关键词
- 第二轮搜索:使用改写后的Query重新检索,成功命中相关片段
- 第三轮补充:进一步调用Read File工具获取相关文档的上下文
- 最终生成:基于整合好的完整信息,生成高质量答案
这就是Agentic RAG的核心优势——遇到问题不放弃,而是像人一样思考、调整、重试。
代码实战:用LangChain构建传统RAG与Agentic RAG
传统RAG的代码实现
整个实现基于LangChain框架,核心步骤如下:
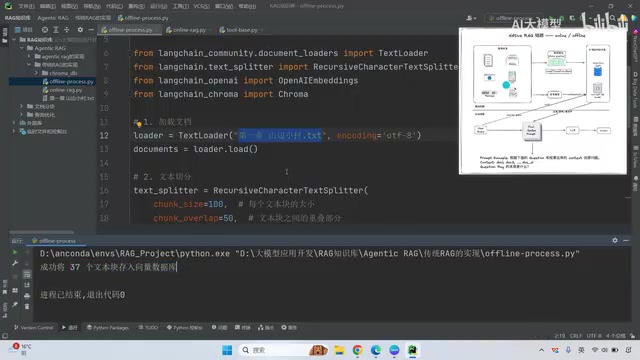
离线部分:使用TextLoader加载文档,通过RecursiveCharacterTextSplitter进行文本切分(设置chunk_size和chunk_overlap),使用Embedding模型(如千问Embedding 0.6B)进行向量化,最后存入Chroma向量数据库。实测中,一个TXT文件被切分成37个文本块并全部存入数据库。
在线部分:加载Embedding模型和Chroma数据库,构造用户Query,调用similarity_search方法检索最相关的K个片段,将片段的page_content拼接到Prompt模板中,交给大模型生成答案。
实际运行中,当问到小说中某个角色的信息时,由于检索到的三条片段都不包含相关内容,模型只能回答"不知道"。这恰恰说明了传统RAG的核心瓶颈在于Context的质量——检索不到有用信息,模型再强也无能为力。
Agentic RAG的代码实现
核心实现使用LangGraph中的create_react_agent,只需三个关键参数:
- 大模型实例:初始化后的LLM(如GPT-4、DeepSeek等)
- 工具列表:注册四个核心工具(Search Query、List Files、Read File、Reason File)
- System Prompt:引导模型如何使用工具的系统提示词
LangGraph是LangChain团队推出的Agent编排框架,基于有向图(Directed Graph)的概念构建Agent工作流。与传统的链式调用(Chain)不同,LangGraph支持循环、条件分支和持久化状态管理,非常适合实现多轮迭代的Agentic RAG。create_react_agent是LangGraph提供的高级API,内部实现了完整的ReAct循环状态机——包括"调用模型"节点、"执行工具"节点以及连接两者的条件边。开发者只需定义工具和提示词,框架会自动处理消息传递、工具执行和循环终止判断。
agent = create_react_agent(
llm,
tools=[search_query, list_files, read_file, reason_file],
system_prompt=system_prompt
)
result = agent.invoke({"messages": [user_query]})
代码看上去非常简洁,但它赋予了模型自主决策、动态调整的能力。有一个实践中的关键细节:System Prompt中必须对模型的回复格式进行严格限制,否则模型可能会去掉引号或括号,导致工具调用参数解析失败。
总结:工具赋予能力,智能在于选择
传统RAG是两个固定流程的组合——文档切片→向量化→存储,以及向量检索→拼接Prompt→生成答案。简单直接,但缺乏灵活性,无法应对检索失败或信息不完整的情况。
Agentic RAG的三大核心升级:
- 工具化:将检索、文件读取等能力封装为可调用的工具
- 决策权下放:赋予大模型自主决策的权利,由模型判断何时调用什么工具
- 迭代循环:模型可以根据任务需求动态规划、调用工具、观察结果并进行多轮迭代
工具赋予能力,而智能在于选择。真正的Agentic RAG,始于检索,成于决策。 国内很多所谓的"套壳应用",其核心逻辑其实就是这么简单——把核心部分抽取出来,借助LangChain和LangGraph等框架,就能实现一套具备智能体行为的RAG系统。
如果你正在构建大模型应用,不妨从传统RAG开始,逐步引入工具调用和Agent机制,让你的系统从"只会查"进化为"会思考"。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。