Agentic RAG实战:原理剖析与LangChain代码实现
Agentic RAG将传统RAG从固定检索流程升级为具备自主决策和多步迭代能力的智能体系统。
传统RAG采用"检索一次、生成一次"的线性流程,面对检索失败或信息不完整时无法自我修正。Agentic RAG将检索、文件读取等环节封装为可调用工具,基于ReAct范式赋予大模型"思考→行动→观察→再思考"的闭环决策能力,通过多步迭代提升回答质量。文章以ChatPDF Boss项目为例,展示了四个核心工具的设计,并通过LangChain+LangGraph给出了完整代码实现。
传统RAG系统的局限性正在被越来越多的开发者所认识:检索一次、生成一次、流程结束,面对检索失败或信息不完整的情况束手无策。Agentic RAG的出现,将RAG从"一条直线走到底"的固定流程,升级为具备规划、调用、反思和迭代能力的智能体闭环系统。
本文将从传统RAG的基本原理出发,深入剖析Agentic RAG的核心机制,并通过LangChain + LangGraph代码演示其完整实现。
传统RAG的实现与局限
离线流程:文档切片到向量存储
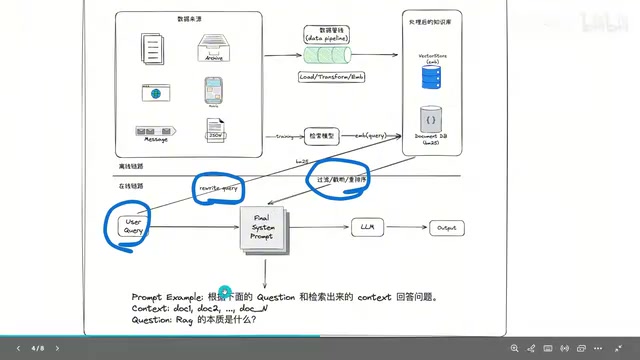
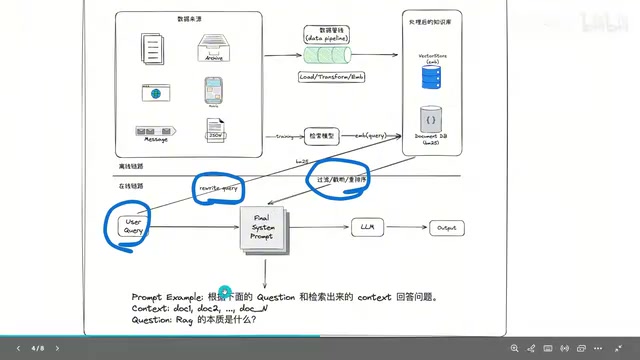
传统RAG的实现可以清晰地分为两个流程:离线流程和在线流程。
离线流程的核心任务是将原始文档转化为可检索的向量数据。具体步骤如下:首先加载文档(PDF、Word、TXT等),然后对文档进行切片——因为完整文档可能包含上万字,无法一次性输入大模型。切片后得到固定长度(如256个字符)的段落,段落之间通常会有一定的重叠以保证上下文连贯性。
值得注意的是,文本切片(Chunking)看似简单,实际上是RAG系统中影响最终效果的关键环节之一。除了固定长度切片外,业界还发展出了多种高级策略:语义切片(Semantic Chunking)根据文本语义边界进行分割,确保每个片段在语义上是完整的;递归切片(Recursive Chunking)按照段落、句子、字符的层级逐步细分;还有基于文档结构的切片,利用标题、章节等结构信息进行智能分割。chunk_size的选择需要在检索精度和上下文完整性之间权衡——过小的片段可能丢失关键上下文,过大的片段则会引入噪声并消耗更多Token。overlap(重叠区域)的设置则是为了缓解切片边界处信息断裂的问题,通常设置为chunk_size的10%-20%。
接着,使用Embedding模型将每个段落转化为固定维度的向量,最后将这些向量存储到向量数据库中。Embedding模型(如OpenAI的text-embedding-ada-002、开源的BGE系列等)的核心原理是将文本映射到高维向量空间中,使得语义相近的文本在向量空间中距离更近。这一过程基于Transformer架构的预训练语言模型,通过对比学习(Contrastive Learning)等训练范式,让模型学会捕捉文本的深层语义特征。向量维度通常在768到1536之间,维度越高理论上表达能力越强,但计算成本也相应增加。向量数据库(如ChromaDB、Milvus、Pinecone等)则专门针对高维向量的近似最近邻搜索(ANN)进行了优化,采用HNSW、IVF等索引算法,能够在百万甚至亿级向量中实现毫秒级检索。
在线流程:检索、拼接与生成
在线流程是用户实际交互的过程。当用户提出问题后,系统首先对问题进行改写(因为用户的原始表述不一定适合直接检索),然后通过两种方式进行检索:一是BM25关键词检索,二是将问题向量化后进行语义相似度匹配。
BM25(Best Matching 25)是信息检索领域的经典算法,基于词频(TF)和逆文档频率(IDF)进行关键词匹配,属于稀疏检索方法。它的优势在于对精确关键词匹配非常敏感,比如专有名词、型号编码等。而语义检索(Dense Retrieval)则擅长理解同义词、近义表达和上下文语义。两者结合的混合检索(Hybrid Search)策略已成为工业级RAG系统的标配。
两轮检索的结果合并后进行重排序(Reranking),Reranking阶段通常使用交叉编码器(Cross-Encoder),它将查询和文档拼接后联合编码,相比双塔模型能更精确地判断相关性,但计算成本更高,因此只用于对初筛结果的精排。最终将Top-K的文档片段注入到Prompt模板中,交给大模型生成答案。
这个流程简单直接,但存在根本性的缺陷:整个过程是单向、固定、一次性的。如果第一轮检索没有命中相关内容,系统不会尝试换一种方式重新检索;如果上下文信息不完整,模型也无法主动去补充。当你问"知识库里有哪些文档"时,传统RAG直接"当机"——因为它只会检索片段,不会思考。
Agentic RAG的核心理念
从固定流程到智能决策闭环
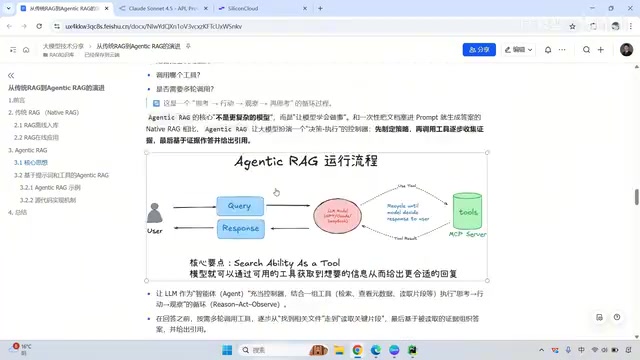
Agentic RAG是对传统RAG的根本性升级。它的核心思想是:将RAG中的各个环节(Query改写、向量检索、关键词搜索、文件读取等)全部封装为可调用的工具(Tool),并赋予大模型自主决策的能力。
模型不再被动地执行固定流程,而是进入一个"思考→行动→观察→再思考"的循环。这一循环源自2022年Google Research和Princeton University联合提出的ReAct(Reasoning + Acting)范式。ReAct的核心洞察是:单纯的链式推理(Chain-of-Thought)容易产生幻觉和错误累积,而单纯的行动执行又缺乏推理指导。ReAct将两者交织在一起——模型先用自然语言进行推理(Thought),然后基于推理结果执行具体动作(Action),再观察动作的返回结果(Observation),形成一个闭环。这种范式让大模型能够像人类一样,在解决复杂问题时不断调整策略,而不是一条路走到黑。
具体来说:用户提出问题后,问题直接交给大模型,由模型判断是否需要调用工具、调用哪个工具。工具返回结果后,模型观察结果质量,决定是继续调用其他工具补充信息,还是基于已有结果生成最终答案。
Agentic RAG的三大核心能力
Agentic RAG的实现依赖模型具备三类核心能力:
- 规划能力(Planning):体现在Chain-of-Thought推理过程中,模型能够规划解决问题的步骤
- 工具调用能力(Tool Calling):模型能够识别并调用合适的工具,甚至进行多Agent协作
- 多步迭代能力:模型可以在生成最终答案之前进行多轮工具调用,逐步完善信息
ChatPDF Boss的Agentic RAG实现解析
架构设计:用时间换智能
以开源项目ChatPDF Boss为例,其Agentic RAG的实现逻辑非常值得借鉴。系统首先判断模型是否支持Function Calling:
不支持Function Calling的情况:通过Prompt判断用户问题是否需要检索。如果不需要检索,直接回复;如果需要,则进行语义搜索后生成答案。这种"先判断再检索"的方式,比在Prompt中让模型忽略无关Context的效果更好。
支持Function Calling的情况:将所有工具注册到模型中,让模型自主决策调用哪些工具。这才是真正的Agentic RAG——从用户输入问题的那一刻起,大模型就开始参与决策,而不是仅在最后的生成阶段才介入。
Function Calling(函数调用)是OpenAI在2023年6月率先引入的能力,随后被各大模型厂商广泛跟进。其技术本质是在模型的训练数据中加入了大量的函数定义和调用示例,使模型学会在适当的时机输出结构化的JSON格式函数调用请求,而非自然语言文本。模型并不真正执行函数,而是生成包含函数名和参数的结构化输出,由外部系统负责实际执行并将结果返回给模型。这一机制是Agentic系统的基石——没有可靠的Function Calling能力,模型就无法准确地与外部工具交互。目前支持Function Calling的模型包括GPT-4系列、Claude 3系列、Qwen系列、GLM-4等,但各模型在调用准确率和复杂参数处理上仍存在显著差异。
四个核心工具设计
ChatPDF Boss设计了四个核心工具,每个都解决了传统RAG的一个痛点:
- Search Query(基础检索):最基本的语义检索工具,对应传统RAG的检索功能
- List Files(文件列表):列出知识库中的所有文件清单。传统RAG无法回答"知识库里有哪些文档"这类问题,因为它只能检索片段而非全局信息。有了这个工具,模型可以获取文件数量、名称等元信息
- Read File(精确读取):根据文档ID精确读取特定片段。当模型发现信息不完整时,可以主动读取前后片段补充上下文,不再依赖语义相似度检索
- Gather File Meta(元数据读取):获取文件的元数据信息,提供更丰富的上下文
传统RAG vs Agentic RAG的实际效果对比
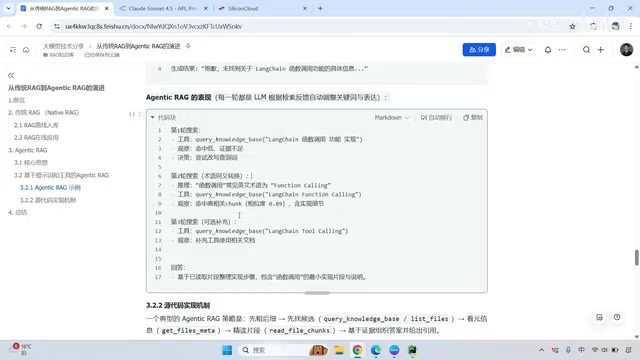
以一个具体案例来说明两者的差异:
传统RAG:用户查询→向量检索→检索结果→生成答案。如果第一次检索命中率低,就只能基于低质量的上下文勉强回答。
Agentic RAG:第一轮搜索后观察到命中率很低→改写查询词→第二轮搜索命中相关结果→第三轮搜索获取补充文档→基于整合后的完整信息生成高质量答案。整个过程是多步迭代的,每一步都有"观察-思考-行动"的决策。
Agentic RAG代码实现详解
传统RAG的LangChain代码实现
基于LangChain框架,传统RAG的实现分为两部分:
离线部分:加载文档→文本切分(设置chunk_size和overlap)→使用Embedding模型向量化→存储到ChromaDB向量数据库。代码核心就是调用LangChain的文本分割器和ChromaDB的存储接口。
在线部分:加载向量数据库→接收用户Query→调用similarity_search检索Top-K片段→拼接到Prompt模板→大模型生成答案。实际运行中,如果检索到的片段与问题不够相关,模型只能回答"不知道"。
基于LangGraph的Agentic RAG代码实现
核心实现使用了LangGraph中的create_react_agent,这是一个内置了"观察与思考"模式的Agent框架。
LangGraph是LangChain团队于2024年推出的Agent编排框架,其核心设计哲学是将Agent的执行流程建模为有向图(Directed Graph)。与LangChain早期的链式调用(Chain)不同,LangGraph支持循环、条件分支和状态持久化,这使得构建具有复杂决策逻辑的Agent成为可能。在LangGraph中,每个节点(Node)代表一个处理步骤(如调用LLM、执行工具),边(Edge)定义了节点之间的转换条件。create_react_agent是LangGraph提供的高级封装,它内部实现了一个标准的ReAct循环图:LLM节点决定是否调用工具,如果调用则转入工具执行节点,工具结果返回后再回到LLM节点进行下一轮判断,直到LLM决定直接输出最终答案。这种图结构的优势在于可观测性强、易于调试,且支持断点恢复和人机协作(Human-in-the-Loop)。
实现步骤:
- 定义工具集:将Search Query、List Files、Read File、Gather File Meta四个功能封装为Tool
- 编写System Prompt:引导模型如何使用这些工具,注意要限制回复格式以避免工具调用失败
- 创建React Agent:传入大模型实例、工具列表和系统提示词
- 运行Agent:调用
invoke方法传入用户问题,Agent会自动进入思考-行动-观察的循环
# 核心代码结构(简化版)
agent = create_react_agent(
llm=model, # 大模型实例
tools=tool_list, # 工具列表
system_prompt=prompt # 系统提示词
)
result = agent.invoke({\"input\": user_query})
代码看似简单,但它赋予了模型自主决策、动态调整的能力。这也是为什么很多国内的"套壳"应用本质上都是基于类似的核心逻辑实现的。
总结与思考
传统RAG是"检索即回答"的线性流程,简单直接但缺乏灵活性;Agentic RAG则是"工具赋予能力,智能在于选择"的闭环系统。其核心价值在于:
- 将检索能力工具化:不再是固定的检索流程,而是模型可以按需调用的能力
- 赋予模型决策权:模型可以规划、调用、观察、迭代,直到获得足够信息
- 用时间换质量:通过多轮交互提升回答的准确性和完整性
真正的Agentic RAG,始于检索,成于决策。对于大模型工程师而言,理解并掌握这一范式,已经成为2025年的必备技能。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。