Agent开发核心是上下文工程?深度拆解面试高频题

Agent开发核心是上下文工程,即动态管理信息流让无状态模型做最优决策。
本文通过拆解一道大模型面试题,阐述Agent开发的核心是上下文工程。大模型本质是无状态函数,Agent的智能表现源于动态组装上下文(系统指令、任务规划、记忆系统、工具空间、外部观察五大模块)。面对注意力迷失、噪声幻觉、工具超载、状态失步四大痛点,需采用摘要压缩、混合检索重排序、多智能体架构和确定性状态机四大方案解决。
引言:一道暗藏玄机的面试题
"有人说Agent开发的核心就是上下文工程,你认同吗?"
这道看似简单的面试题,实际上暗藏杀机。如果你只回答"认同"或"不认同",基本上就凉了一半。因为这个问题表面上在考你对提示词的理解,实际上是在考你对Agent架构设计的底层功力。
本文基于B站UP主彭宇的深度分享,系统拆解这道大模型高阶面试题的完整回答路径,帮你把Agent开发的底层逻辑讲透。
为什么高度认同:看透大模型的本质
大模型本质上是一个无状态的函数——它本身没有记忆,不会主动思考,更不会自己去调用工具。你看到的Agent表现出来的所有"聪明才智",比如会规划、会复盘、会查资料,本质上是因为我们在每一个时刻,把环境状态、历史记忆和任务目标精准地组装成了一个上下文喂给了它。
所以,Agent开发的核心就是要把"写提示词"这种小儿科,升级成动态状态管理工程。

上下文的五大核心模块
一个成熟的Agent上下文绝对不是一句话,它是由五大原材料动态拼装而成的:
系统指令:Agent的身份证
给Agent定义角色、性格和安全底线,决定了Agent的行为边界和基本人设。这是上下文中最稳定的部分,但也是最容易被忽视的架构基石。
任务规划:Agent的草稿纸
记录当前任务拆解到哪一步了,是Agent实现复杂推理和多步骤执行的关键支撑。没有清晰的任务规划,Agent在面对复杂问题时就会迷失方向。
记忆系统:短期记忆与长期记忆
分为短期的聊天记录和长期的历史信息。短期记忆维持对话连贯性,长期记忆则需要从向量数据库里动态提取。记忆管理的好坏,直接决定了Agent的"智商上限"。
工具空间:Agent的工具箱
告诉Agent现在手头有哪些"扳手和螺丝刀",也就是可用API的描述、参数和调用方式。工具描述的质量直接影响模型的调用准确率。
外部观察:与真实世界的反馈通道
比如刚搜到的新闻、API返回的结果或报错信息,这是Agent与真实世界交互的实时反馈。没有外部观察,Agent就是在"闭眼开车"。

这五块内容随时都在变化,如何高效地把它们塞进上下文窗口,就是上下文工程化的第一步。
四个要命的痛点:为什么不能全塞进去
有人可能会问:现在大模型窗口不是都几十万、上百万token了吗?全塞进去不就得了?
千万别这么想。这恰恰是面试时体现实战经验的地方。Agent开发中我们面临四个核心痛点:
痛点一:注意力迷失(Lost in the Middle)
东西塞多了,模型会对中间的信息"间歇性失忆"。研究表明,模型对上下文开头和结尾的信息关注度最高,中间部分容易被忽略。而且上下文越长,推理越慢、成本越高。
痛点二:噪声干扰导致幻觉
如果检索回来的文档里有错误信息或无关内容,模型会直接被带偏,开始"一本正经地胡说八道"。垃圾进,垃圾出——这在RAG场景中尤为致命。
痛点三:工具超载引发选择困难
如果你给Agent 100个工具描述,它就晕了,甚至会幻想出不存在的参数。工具越多,选择困难症越严重,调用准确率断崖式下降。
痛点四:状态失步造成死循环
Agent以为自己执行成功了,但外部环境其实报错了。上下文没有及时更新,Agent就在那里死循环,反复执行同一个失败操作。

动态装配引擎:四大高阶解决方案
这才是面试官最想听的干货——如何系统性地解决上述痛点。
方案一:上下文压缩——告别复读机
当对话太长时,让模型自己生成摘要,用精简后的信息替换全量历史记录。核心思路是保留语义,压缩token。实践中可以设定一个token阈值,超过后自动触发摘要压缩流程。
方案二:混合检索与重排序——三层过滤保纯净
不能只靠语义搜索(Embedding相似度),还得加一层重排序模型(Reranker),确保塞进上下文的信息是绝对纯净、绝对相关的。关键词检索 + 语义检索 + 重排序,三层过滤机制大幅降低噪声干扰。
方案三:动态工具召回与多智能体架构
面对上百个工具,先用一个轻量级模型选出最相关的5个,再把这5个放进主模型的上下文里。或者干脆把任务拆给不同的子Agent,实现工具级的**"物理隔离"**,每个子Agent只关注自己领域内的少量工具。
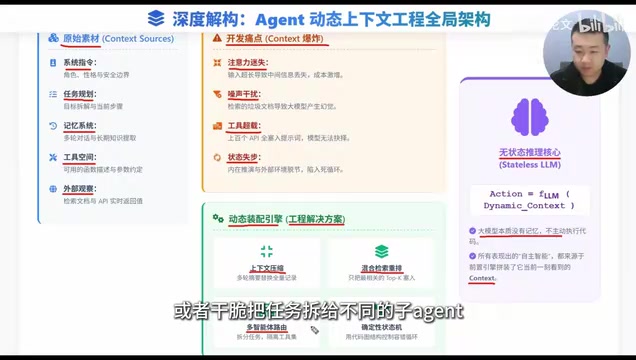
方案四:确定性状态机——代码管流程,模型管决策
别全指望模型在提示词里自我推演。用图结构框架(如LangGraph)把逻辑固化,用代码逻辑强制控制容错和循环。核心原则是:确定性的流程用代码管,不确定性的决策交给模型。
面试回答的完整路径
如果面试官问你这个问题,建议按照以下路径组织回答:
- 明确认同:把上下文比作Agent的"血液"和"短期大脑",阐明大模型无状态的本质
- 展示结构化思维:拆解上下文的五大模块——系统指令、任务规划、记忆系统、工具空间、外部观察
- 直击工程痛点:聊注意力迷失、噪声幻觉、工具超载和状态失步
- 抛出高阶方案:摘要压缩、混合检索重排、多智能体隔离、LangGraph状态机控制
这四步走下来,既展示了理论深度,又体现了实战经验,面试官想不给高分都难。
总结
Agent开发绝不是在玩文字游戏,而是在做一个复杂的信息流转系统。上下文工程的本质,是在有限的注意力窗口内,动态组装最优信息组合,让无状态的大模型在每一次调用中都能做出最佳决策。
理解了这一点,你就理解了为什么业界越来越多的人把"Prompt Engineering"升级为"Context Engineering"——因为真正的Agent开发,管理的不只是一句提示词,而是一整套动态变化的信息生态。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。