Agent平台基石:Session Event的抽象、传输与存储实战

生产级Agent平台中Session Event的抽象、传输与存储设计实践
本文基于实战经验,系统梳理了构建生产级Agent平台时Session Event面临的三大工程挑战:一是面对OpenAI、Anthropic等不同LLM API和Agent运行时的事件格式碎片化,需要建立Universal Event统一抽象层实现运行时无缝切换;二是从本地一段式SSE到Client-Control Plane-Agent三方架构的流式传输设计,需解决多链路容错、断点续传和多对多关系下的数据一致性问题;三是存储方案从PostgreSQL一行一条Message的初始设计出发,因JSONB频繁增量更新导致写放大等性能瓶颈而需要持续演进。
构建生产级Agent平台时,每一次与LLM API对话产生的事件数据,看似简单,实则暗藏大量工程挑战。本文基于实际踩坑经验,系统梳理Session Event在抽象、传输和存储三个维度的设计思路与技术细节,帮助开发者少走弯路。
为什么需要统一的事件抽象
业界API的碎片化现状
LLM API在逐步趋于统一,但目前主流的API规范仍然存在明显分化。OpenAI有新旧两套API——传统的Chat Completions和新推出的Responses API,而由于Claude Code的广泛使用,Anthropic的API也成为了另一个主流选择。
进入Agent领域后,数据格式的差异被进一步放大。以Claude SDK为例,它提供的是message级别的事件粒度,基本与LLM API的消息结构一致:user message、assistant message、tool call和tool result。而Codex则采用了更细粒度的event设计,对工具调用和文本输出都有delta级别的增量事件。
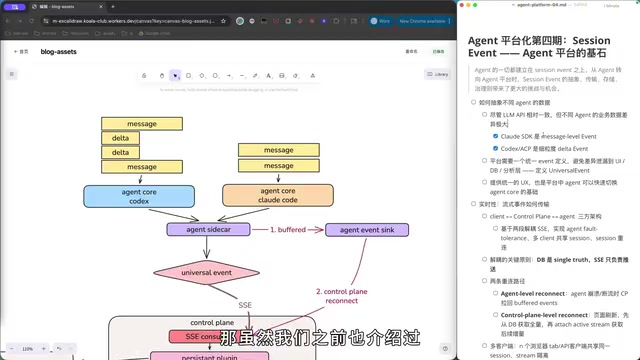
如果未来还要兼容OpenAI使用的Python运行时、Goose等其他Agent运行时,甚至自研运行时,这种差异只会越来越大。虽然有ACP(Agent Communication Protocol)这样由代码编辑器牵头制定的标准,但并非每家都默认支持。
背景:ACP与Agent互操作协议生态 Agent Communication Protocol(ACP)是由代码编辑器生态(以Cursor、VS Code等为代表)推动的Agent互操作性标准,旨在定义Agent之间、Agent与宿主环境之间的标准化通信接口。与此类似的还有Anthropic主导的MCP(Model Context Protocol),专注于模型与工具/数据源之间的标准化连接。这些协议的出现反映了Agent生态从"各自为战"走向互操作的趋势,但由于商业利益分歧和技术路线差异,目前尚未形成真正统一的行业标准。对于平台开发者而言,在协议标准尚未收敛之前,在平台层维护自己的Universal Event抽象是更务实的工程选择。
Universal Event:平台级的统一抽象
为了解决多运行时的兼容问题,平台层面需要做一层叫做Universal Event的抽象。核心目标是:让不同Agent之间的事件差异不会泄露到下游系统——无论是渲染UI、持久化到数据库,还是进行数据分析的引擎,面对的都是统一的事件格式。
这层抽象带来的直接好处是运行时的无缝切换。在本地使用Agent时,从Claude Code切换到Codex,如果没有平台抽象,迁移成本会随着使用深度的增加而急剧上升——MCP配置、Skills配置、thinking level设置、sub-agent定义等都需要重新适配。而通过Universal Event抽象,切换运行时后,历史Session数据可以完整保留。
流式事件的传输架构设计
从一段式到三方架构的转变
LLM推理过程耗时较长,因此从ChatGPT开始,流式API(通常基于SSE,即Server-Sent Events)就成为了标配。
背景:SSE协议与LLM流式输出 Server-Sent Events(SSE)是基于HTTP的单向实时通信协议,由W3C标准化。与WebSocket的双向通信不同,SSE专为服务器向客户端推送数据而设计,天然支持断线重连和事件ID续传。在LLM场景中,SSE的优势在于它基于普通HTTP,可穿透大多数代理和防火墙,且浏览器原生支持EventSource API。OpenAI在2020年将其引入ChatGPT后,SSE几乎成为LLM流式输出的行业标准。其text/event-stream格式简单,每条消息包含data字段,以双换行符分隔,非常适合token级别的增量输出场景。
在本地Agent场景下,架构很简单:Client直连Agent,一段式SSE即可。但在Agent平台中,架构变成了Client → Control Plane → Agent的三方结构。这带来了一个核心设计问题:流式事件应该采用一段式SSE(由Control Plane代理转发),还是采用解耦的方式?
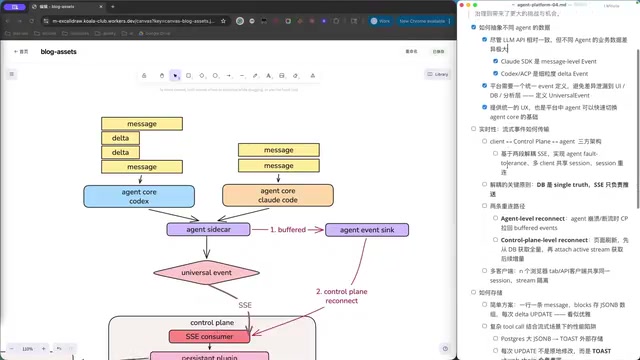
三方架构下的容错机制
一段式架构中,Client与Agent失联时,只需让双方具备失败容忍能力,Client重连后重新attach到Agent即可。但三方架构下,任何一段链路都可能中断,每一段都需要独立处理异常。
关键设计原则是:当三方出现不一致时,以谁为准?这需要明确的优先级策略:
- Agent作为事件的生产者,通常是事实的来源
- Control Plane作为中间层,负责事件的持久化和分发
- Client作为消费者,需要具备断点续传的能力
多对多关系的复杂性
本地Agent是简单的一对一关系,但平台化后变成了复杂的多对多:
- 多个Client → 一个Control Plane:浏览器多个Tab、API Client可能同时访问同一个Session
- 一个Control Plane → 多个Agent:平台管理多个Agent实例
同一个Session可能被多个Client同时访问,这在本地Agent中几乎不存在。平台需要重新设计事件的隔离与共享策略,确保多客户端协同时的数据一致性。
存储方案的演进与踩坑经验
初始方案:PostgreSQL一行一条Message
最直觉的存储方案是在PostgreSQL中每行对应一条message,工具调用的详情以JSONB格式存储,通过增量更新来维护状态。
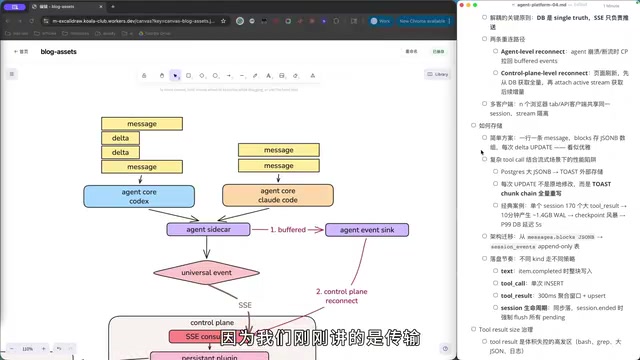
这个方案看起来优雅,但在实际运行中遇到了严重的性能瓶颈。原因在于:Agent的工具调用结果大小极不可预估。一个Agent通过命令行工具匹配大型目录时,返回结果可能达到几十KB甚至超过整个Context的大小。对JSONB字段的频繁增量更新,在高并发场景下会导致锁竞争和写放大问题。
背景:PostgreSQL MVCC与JSONB写放大 PostgreSQL的JSONB类型以二进制格式存储JSON数据,支持GIN索引和高效的键值查询,是存储半结构化数据的常见选择。然而,PostgreSQL采用MVCC(多版本并发控制)机制,每次UPDATE操作实际上是写入一条新的行版本,旧版本由VACUUM进程异步清理。当对包含大JSONB字段的行进行频繁增量更新时,每次更新都会复制整行数据,即使只修改了其中一个小字段。这种"写放大
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。