AI Agent工程化落地:四大难题与12周实战路线图

AI Agent从Demo到生产的工程化方法论
约九成AI Agent项目止步于Demo阶段,根本原因在于性能不稳定、成本不可预测、质量难闭环三大工程化短板。本文提出四层架构(感知、推理、行动、记忆)、三种运行模式选型(Workflow、Agent、Multi-Agent)、工具编排验证机制和上下文工程六要素,系统性地解决Agent从原型到生产的落地难题。
大约九成的AI Agent项目最终停留在Demo阶段——不是模型不够强,也不是创意不够好,而是工程化能力跟不上。本文基于一线团队的实战经验,系统梳理AI Agent从原型到生产环境的完整方法论,覆盖架构设计、上下文工程、评估体系和可观测性四大核心维度。
九成AI Agent项目死在Demo阶段,问题到底出在哪
在与大量团队的交流中,一个扎心的事实反复浮现:绝大多数Agent项目走不出实验室。根本原因指向三道工程化门槛:
性能不稳定:多步推理叠加后,每一步5%~10%的抖动会逐级放大,整体成功率断崖式下滑,P95延迟动辄翻5到10倍。
成本不可预测:同一个任务在不同上下文长度下,单次Token消耗能飘移5到50倍,长尾任务尤其容易吞掉预算。
质量难闭环:失败原因到底是模型问题、提示词问题还是数据问题,往往说不清楚。没有回归测试,每次改Prompt都提心吊胆。
这三道门槛有一个共性:靠"换一个更强的模型"解决不了,必须依赖系统性的工程化手段。
AI Agent标准架构:四层模型拆解
Agent系统可以拆分为四个清晰的层次,每一层都有独立的工程化挑战,也都能独立打磨和替换:
- 感知层:负责输入解析、多模态融合、上下文窗口管理
- 推理层:承担Plan、ReAct、Tree of Thought、Reflection等决策范式
- 行动层:将模型决策落地到工具调用、函数执行、API编排
- 记忆层:包括短期上下文、长期向量库和任务级缓存
推理范式背景:推理层中的几种范式各有侧重。ReAct(Reasoning + Acting)由谷歌研究团队于2022年提出,将思维链推理与外部工具调用交织在一起,让模型在每一步既能"想"也能"做",是目前最主流的单步决策范式。Tree of Thought(ToT)则允许模型同时探索多条推理路径,类似人类在复杂决策时的发散思维,适合需要全局搜索的场景。Reflection机制让Agent在行动后对结果进行自我评估,形成"行动→反思→修正"的闭环,能有效减少单次决策失误的累积影响。这些范式并非互斥,生产中往往根据任务复杂度混合使用。
四层架构的核心价值在于关注点分离——当某一层出问题时,可以精准定位并独立优化,而不必牵一发动全身。理解架构之后,下一步是选择合适的运行模式。
三种Agent模式选型:Workflow、Agent与Multi-Agent

实际生产中,Agent的运行模式大致分为三种,适用场景各不相同:
Workflow(工作流模式):路径固定,LLM只负责"填空"。可预测、好调试,适合确定性任务,比如固定流程的文档生成、表单处理。
Agent(智能体模式):路径动态,运行时让模型自己决定下一步。这是大部分项目真正在做的模式,适合半结构化的探索类任务。
Multi-Agent(多智能体模式):将Planner、Critic、Worker拆开并发协作,灵活性最高但复杂度也最高,只在真正需要长程任务分解的场景下使用。
一条务实的建议:绝大多数生产场景,从Agent模式起步就够了。不要过早引入Multi-Agent的复杂度,等单Agent的能力边界被充分验证后再考虑拆分。
工具编排:最容易翻车的环节在第四步
一个稳定的工具调用链路大致分为六步:解析任务→选择工具→调用执行→验证返回→重试/回退→结果汇总。
这里有一个关键洞察:最常见的翻车点不在第一步,而在第四步——验证返回。很多团队拿到工具返回就直接喂给模型,跳过了Schema验证和业务规则校验。幻觉就是从这里漏进来的——模型可能编造工具、编造结果,甚至假装调用成功。
幻觉与Grounding背景:幻觉(Hallucination)是大语言模型最棘手的固有缺陷之一:模型会以高置信度生成听起来合理但实际上错误或虚构的内容,包括编造不存在的工具名称、伪造API返回结果,甚至声称已成功执行从未发生的操作。Grounding(接地)是对抗幻觉的核心工程手段,其本质是为模型的每一个关键输出绑定可验证的真实数据源——例如强制要求工具调用结果必须通过Schema校验才能进入下一步推理,或在生成答案时要求模型引用具体的检索片段。Grounding不能消除幻觉,但能将其影响限制在可检测、可拦截的范围内。
具体来说,验证返回至少要做三件事:
- Schema校验:返回字段类型、必填项是否完整
- 业务规则校验:返回值是否在合理范围内
- 一致性校验:返回结果与请求参数是否逻辑自洽
每一步都要可观测,每一步都要有兜底,这是工具编排的铁律。
上下文工程:决定AI Agent生死的核心能力
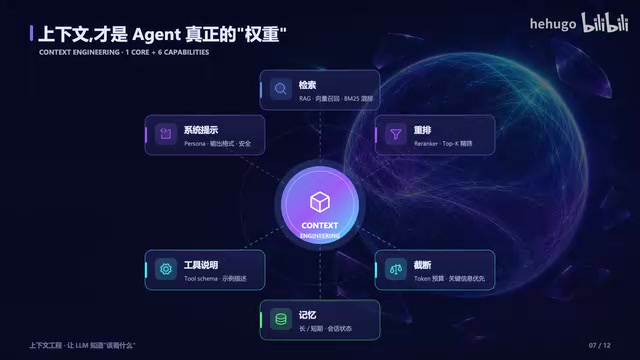
模型每天都在迭代,提示词也每天都在调整,但真正决定一个Agent好不好用的,是它每一步看到了什么——也就是上下文工程。
围绕这个核心,至少要做好六件事:
- 检索要稳:RAG的召回质量直接决定Agent的决策质量,检索失败意味着后续所有推理都建立在错误基础上
- 重排要准:检索结果的排序直接影响模型的注意力分配,好的Reranker能让准确率跳升一个台阶
- 截断要会取舍:上下文窗口有限,必须学会丢弃低价值信息,保留对当前决策最关键的内容
- 记忆要分长短期:短期对话记忆和长期知识库分开管理,避免信息混杂导致决策偏移
- 工具说明要够具体:模糊的工具描述会导致选错工具,每个工具的输入输出、适用场景都要写清楚
- 系统提示要完整:人设、输出格式、安全规则、边界条件都要在系统提示中讲清楚
RAG与Reranker技术背景:RAG(Retrieval-Augmented Generation,检索增强生成)是当前主流的外部知识注入方案:先将知识库文档切片并编码为向量,存入向量数据库;查询时通过语义相似度检索Top-K个相关片段,拼入上下文供模型生成答案。然而向量检索本质上是近似匹配,召回结果的排列顺序并不总是按"对模型最有用
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。