AI Agent行研实测:ChatGPT、Kimi、Manus谁更懂投资分析

Kimi蜂群智能体凭借多智能体协同架构,在投资分析任务中击败ChatGPT和Manus。
B站UP主用同一提示词让ChatGPT、Manus和Kimi分析美国七大科技巨头并交付投资报告。Kimi蜂群智能体交出76页报告,最接近专业卖方分析师水准,能抓住AI资本支出与变现效率的核心矛盾;Manus速度快但分析浅且过于乐观;ChatGPT框架稳健但深度不足。核心差距在于多智能体协同架构带来的并行分工、交叉验证和容错恢复能力,这才是AI Agent走向实用化的关键。
文章正文
当AI Agent开始挑战专业金融分析师的工作,谁能交出一份真正有深度的投资研究报告?B站UP主拉斐用同一个提示词,花费近60美金,分别让ChatGPT、Manus和Kimi完成了一项高难度任务——深度分析美国七大科技巨头并交付完整的投资分析文档。结果差异之大,令人深思。
任务设定:同一提示词,三家AI同台竞技
测试任务要求非常明确:对美国七大科技巨头进行深度投资分析,并交付Word研究报告、Excel数据表和PPT演示文稿三类文档。
这是一个典型的卖方分析师(Sell-side Analyst)工作场景。卖方分析师是投资银行、券商研究部门的核心岗位,专门为机构投资者提供上市公司研究报告。其工作流程通常包括:财务数据建模(DCF、相对估值等)、行业调研、管理层访谈、风险情景分析,最终输出包含明确买卖评级和目标价的研究报告。一份完整的卖方报告往往需要分析师团队数天乃至数周的协作,涵盖数据收集、财务建模、逻辑推导和文档撰写多个环节。这也是为何此次测试选择"同时交付Word、Excel、PPT三类文档"作为评判标准——这正是真实卖方研究的标准交付物组合,不仅考验AI的信息搜集能力,更考验其分析框架、逻辑推导和专业判断力。
三个参赛选手分别是:ChatGPT的深度研究功能、Manus以及Kimi的蜂群智能体。其中Manus和Kimi都交付了完整的多文件作品,而ChatGPT受限于模型能力,仅交付了Word文档。
横向对比:三份报告质量差距明显
Manus:速度最快,但深度最差
Manus虽然用时最短,但报告质量在三者中垫底。最大的问题在于它漏掉了最核心的深度分析报告,在被提醒后也只补充了一份观点罗列式的文档。
更关键的是,Manus的分析视角存在明显偏差——它默认"AI投资支出大则未来业务增速快",整体观点过于乐观。但即便从常识来看,我们都知道不能只看谁花钱多,更要看这些钱能否转化为收入、利润和自由现金流。而这些观点缺乏数据支撑,仅列出了各公司未来5年收入增速预测,分析深度远远不够。
Kimi蜂群智能体:最像卖方分析师的作品
Kimi的蜂群智能体交出了一份76页的完整报告,整体最接近专业卖方分析师的水准。它真正在做分析,而不是简单罗列信息。
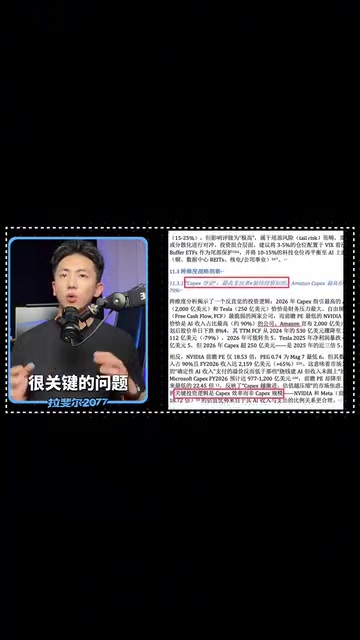
Kimi抓住了一个非常关键的问题:AI资本性支出增加不等于业务收入必然上涨,真正重要的是这些投入最终能否带来变现效率的提升以及自由现金流的回收。
理解这一判断需要一些财务背景:**资本性支出(CapEx,Capital Expenditure)**是指企业用于购置或升级固定资产的支出,在科技行业主要体现为数据中心建设、GPU采购和网络基础设施投入。近年来,微软、谷歌、亚马逊、Meta等科技巨头的AI相关CapEx呈爆发式增长,2024年合计超过2000亿美元。然而,CapEx增加并不直接等同于收入增长,关键在于"投资回报周期"和"变现路径"——CapEx转化为收入的时间差有多长、自由现金流(FCF)被压缩到什么程度、以及ROI(投资回报率)的可见性如何。Kimi能识别出这一核心矛盾,说明其分析框架已接近专业水准。
此外,Kimi还将AI变现路径进行了拆解——不是所有公司都在直接卖AI产品,有些公司是将AI嵌入原有的广告、电商和云服务体系,让既有业务变得更赚钱。这比单纯说"谁有AI谁更牛"要深入得多。
在风险意识方面,Kimi提出了一个值得关注的观点:2026年AI投资可能从"信仰驱动"进入"证据驱动"阶段。这一判断有其宏观背景:2023-2024年,AI投资浪潮主要由"叙事驱动"(Narrative-driven)支撑——市场愿意为AI的未来潜力给予高溢价,即便短期内商业化路径尚不清晰。然而,随着各大科技公司AI CapEx持续攀升但变现进展参差不齐,机构投资者开始要求更明确的ROI证据。摩根士丹利、高盛等机构的研究报告均指出,2025-2026年将是AI投资"兑现期"的关键窗口。Kimi的这一判断与主流卖方机构的观点高度吻合,体现了其对宏观投资周期的准确把握——市场不会再只为故事买单,而是要看真实回报。
不过Kimi也有明显短板:整体耗时超过一个小时;短期、中期、长期的投资逻辑没有拆清楚;仓位建议缺少敏感性分析,直接给出了结论。
ChatGPT:框架稳健但深度不足
ChatGPT花了20分钟输出了一份相对精简的报告。优点是框架稳定、结论克制,不会像Manus那样一上来就过度乐观。
但这次ChatGPT没有达到深度研究功能应有的水准。当真正需要对七家公司进行分类和单独分析时,数据支撑不足、分析不够深入。整体更像是将公开信息做了一轮整理,适合作为投资备忘录的初稿,离真正的深度分析报告还有相当距离。
核心差距:多智能体协同 vs 单智能体作战
横向对比之后,最大的差距来自多智能体与单智能体在并行能力上的根本区别。
**多智能体系统(Multi-Agent System,MAS)**是人工智能领域的重要研究方向,指由多个自主智能体协同完成复杂任务的计算框架。与单一大模型的线性推理不同,MAS的核心优势在于:任务并行分解(将复杂任务拆分为可并行执行的子任务)、角色专业化(不同Agent承担不同职能,如数据收集、分析、写作)、以及交叉验证(多个Agent对同一结论进行互相校验,降低幻觉风险)。OpenAI、Anthropic、Google等头部机构均在积极探索Multi-Agent架构。
Kimi蜂群智能体的工作方式正是这一架构的工程实现——它不是简单地拉几个分身平行搜索网页,而是一个有着清晰汇报线、能交叉验证、有分工有组织的多智能体系统。具体来看,它的工作流程分为几个关键阶段:
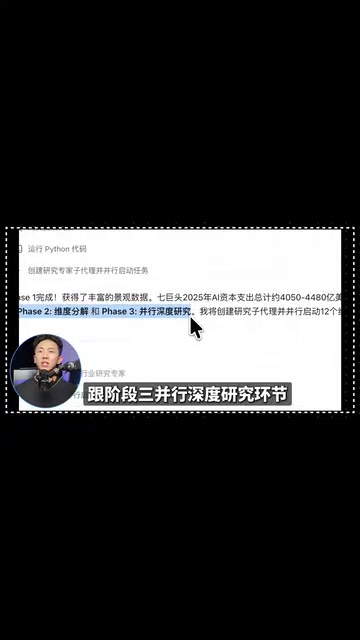
阶段一:数据收集。 蜂群智能体先去Yahoo Finance等数据源收集所需的财务数据。
阶段二:维度拆解与并行研究。 根据任务需要创建了三类Agent——个股分析师、估值分析师和AI生态分析师。当它发现个股研究可以并行时,立刻分裂出7个个股分析师并行研究七大巨头,同时分裂出2个估值分析师和2个AI生态分析师接力工作。
阶段三:协同写作与交付。 行业研究专家和个股深度分析师接力工作,将广度搜索与深度研究环环相扣,最后交给8个文章写手并行完成76页报告的写作。
这就像一个小型研究团队在协同工作——先分工、再并行、再汇总,而不是一个人从头写到尾。
容错能力:真正实用的Agent必须能自我修复
测试中还出现了一个有趣的细节:在生成Excel文件时,蜂群智能体遇到了报错。但它没有像很多传统Agent那样一报错就卡住,或者在同一个问题上无限循环。

**容错能力(Fault Tolerance)**是衡量AI Agent工程成熟度的核心指标之一。在实际工作流中,Agent执行长链任务时不可避免地会遭遇API调用失败、代码报错、数据缺失等异常情况。低成熟度的Agent通常会在报错点卡死或进入无限重试循环,导致整个任务失败。而高可靠性的Agent系统需要具备:错误检测与隔离(识别失败的子任务而不影响整体流程)、并行恢复(在修复失败任务的同时继续推进其他任务)、以及优雅降级(在无法完全修复时提供部分可用结果)。这与分布式系统工程中的"弹性设计"原则一脉相承。
Kimi蜂群智能体的处理方式正体现了这种工程级容错能力:Excel这边继续修复,另一边先并行生成Word文档和PPT报告,最终三个文件同时交付。这种容错和并行恢复能力,是Agent走向实用化的关键特征。
更有意思的是,测试者将三份报告丢给ChatGPT进行第三方评价,连ChatGPT都认为Kimi的作品整体最像卖方分析师的报告,而且"真的有在做分析"。
现阶段AI Agent的能力边界
尽管Kimi蜂群智能体表现最佳,但距离真正专业的投资报告标准仍有差距。在敏感性分析、情景假设和估值推导等细节上还不够扎实,一个多小时的运行时间也有优化空间。
但这次测评揭示了一个重要趋势:AI Agent的价值不在于单次对话有多聪明,而在于能否长时间工作、自主拆解任务、自主分工、自主纠错,最终交付一份可以直接接入工作流的成果。
这才是企业真正想要的智能体形态——不是一个更聪明的聊天机器人,而是一个能协同工作的AI团队。Kimi在Agent这条路上的方向是对的:不只是让模型变得更聪明,而是让AI变成一个真正能协同工作的组织。
核心要点
- Kimi蜂群智能体在投资分析任务中表现最佳,76页报告最接近专业卖方分析师水准,能抓住AI资本支出与变现效率的核心问题
- Manus速度最快但分析最浅,观点过于乐观且缺乏数据支撑;ChatGPT框架稳健但深度不足,更像信息整理而非深度分析
- 多智能体协同架构(Multi-Agent System)是关键差异——蜂群智能体能自主拆解任务、并行分工、交叉验证,远超单智能体的线性工作模式
- 容错能力(Fault Tolerance)是Agent实用化的重要标志,蜂群智能体在遇到报错时能并行修复而非卡死
- AI Agent的核心价值在于长时间自主工作并交付可直接使用的成果,而非单次对话的智能程度
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。