AI Agent学习路线:三个月从小白到企业级开发

三个月四阶段学习AI Agent开发的完整路线拆解
文章系统拆解了一条从零学习AI Agent开发的三个月路线,分为四个阶段:大模型基础(Transformer原理与Prompt Engineering)、Agent核心范式(ReAct思考-行动-观察循环及LangChain等框架)、记忆机制与工具调用(向量数据库实现长期记忆)、多智能体协作(AutoGen/CrewAI等框架)。文章强调项目驱动学习的重要性,并提醒需具备Python编程基础。
AI Agent开发为何值得学
AI Agent(智能体)已经从概念走向落地,成为企业数字化转型中最炙手可热的技术方向。无论是智能客服、自动化办公还是多智能体协作系统,市场对AI Agent开发人才的需求正在急剧增长。
对于想要入行或转型的开发者来说,一个核心问题是:从零开始学AI Agent,到底需要多久? 一份来自B站的实战课程给出了一个相对务实的答案——三个月,分四个阶段,循序渐进地掌握从大模型基础到多智能体协作的完整技能栈。
下面我们来拆解这条AI Agent学习路线,分析每个阶段的核心知识点和学习策略。
第一阶段:夯实大模型基础
任何Agent开发都离不开对大语言模型(LLM)底层逻辑的理解。这个阶段的目标是搞清楚两件事:
- 大模型的工作原理:理解Transformer架构、Token化、上下文窗口、温度参数等核心概念。你不需要从头训练模型,但必须知道模型是如何"思考"的,这直接决定了你后续设计Agent时的决策质量。
Transformer架构背景:Transformer是现代大语言模型的基石,由Google在2017年的论文《Attention Is All You Need》中提出。其核心创新是"自注意力机制"(Self-Attention),允许模型在处理每个词时同时关注输入序列中的所有其他词,从而捕捉长距离依赖关系。相比之前的RNN/LSTM架构,Transformer可以高度并行化训练,这使得GPT、Claude、Gemini等千亿参数模型的训练成为可能。Token化(Tokenization)是模型处理文本的第一步——文本被切分为子词单元(subword),每个Token对应词表中的一个ID。上下文窗口(Context Window)决定了模型单次能"看到"多少Token,GPT-4的128K上下文窗口意味着它能同时处理约10万字的文本。温度参数(Temperature)则控制输出的随机性:接近0时输出更确定,接近2时输出更多样,这直接影响Agent在不同任务场景下的表现稳定性。
- 提示词工程与API调用:掌握Prompt Engineering的常用技巧(如Few-shot、Chain-of-Thought),并熟练调用OpenAI、Claude等主流大模型的API。这是Agent开发的"地基"——Agent本质上就是通过精心设计的提示词来驱动大模型完成复杂任务。
提示词工程核心技术:Few-shot Prompting是指在提示词中提供少量示例(通常3-5个),让模型通过类比学习理解任务格式,相比Zero-shot(无示例)能显著提升复杂任务的准确率。Chain-of-Thought(CoT,思维链)由Google在2022年提出,核心思想是在提示词中要求模型"一步步思考",将复杂推理过程显式化。研究表明,仅仅加入"Let's think step by step"这句话,就能让模型在数学推理任务上的准确率提升数倍。对于Agent开发者而言,Prompt Engineering不只是"写好问题",更是定义Agent的角色边界、行为约束和输出格式的核心手段——一个精心设计的System Prompt,本质上就是Agent的"操作系统"。

这个阶段建议花2-3周时间,重点是动手实践,写大量的Prompt并观察模型的输出差异。
第二阶段:掌握Agent核心范式
进入Agent开发的核心地带,这个阶段需要理解Agent到底是怎么运作的。
ReAct范式:思考-行动-观察循环
ReAct(Reasoning + Acting)是目前最主流的Agent设计范式,来源于2022年普林斯顿大学和Google联合发表的论文《ReAct: Synergizing Reasoning and Acting in Language Models》。论文的核心发现是:单纯的推理(如CoT)缺乏与外部环境的交互,而单纯的行动缺乏语言推理能力,将两者结合才能让LLM在复杂任务中表现出色。
其核心思想是让大模型在执行任务时遵循一个循环:
- Thought(思考):分析当前状况,决定下一步该做什么
- Action(行动):调用工具或执行操作
- Observation(观察):获取行动结果,作为下一轮思考的输入
在工程实现层面,ReAct范式通过特定的Prompt模板来实现:模型被要求以"Thought: / Action: / Observation:"的格式输出,其中Action部分会触发实际的工具调用(如搜索引擎、代码执行器),Observation则是工具返回的真实结果被注入回上下文。这个循环不断迭代,直到模型输出"Final Answer"或达到最大迭代次数。理解ReAct范式,你就理解了AI Agent的"灵魂"——当Agent陷入循环或做出错误决策时,往往可以通过审查Thought链来定位问题根源。

主流框架实战:LangChain与LangGraph
在理解范式的基础上,需要熟练掌握至少一个主流Agent开发框架,比如LangChain或LangGraph。LangChain提供了丰富的工具链和抽象层,能让你快速搭建Agent原型;LangGraph则更适合构建复杂的有状态工作流。
这个阶段建议花3-4周,重点是跟着框架文档做项目,而不是只看理论。
第三阶段:记忆机制与工具调用
一个没有记忆的Agent就像一条金鱼——每次对话都从零开始。这个阶段要解决的核心问题是:如何让Agent变得"聪明"且"有记性"?
记忆系统设计
- 短期记忆(Short-term Memory):通常基于对话上下文窗口实现,让Agent在单次会话中保持连贯性
- 长期记忆(Long-term Memory):通过向量数据库(如Chroma、Pinecone)存储历史交互信息,让Agent能够跨会话记住用户偏好和历史信息
向量数据库与长期记忆原理:向量数据库是实现Agent长期记忆的关键基础设施,其工作原理是将文本通过嵌入模型(Embedding Model,如OpenAI的text-embedding-ada-002)转换为高维向量,然后存储这些向量并支持高效的相似度检索。当Agent需要回忆历史信息时,它将当前查询也转换为向量,通过余弦相似度或欧氏距离找到最相关的历史记录——这个过程称为向量检索(Vector Search)或语义搜索(Semantic Search)。Chroma是一个轻量级的开源向量数据库,适合本地开发和原型验证;Pinecone则是云原生的托管服务,适合生产环境的大规模部署。在Agent记忆架构设计中,还需要考虑记忆的"遗忘机制"——通过时间衰减、重要性评分等策略进行记忆筛选,能有效控制存储成本并提升检索质量。这套技术体系也是RAG(检索增强生成)的核心组件,是当前企业级AI应用中使用最广泛的架构模式之一。

工具使用能力
真正有价值的Agent必须能与真实世界交互——搜索网页、查询数据库、调用第三方API、读写文件等。学习如何为Agent定义和注册工具(Tools),是这个阶段的另一个重点。
实战项目建议:搭建一个带记忆的智能客服系统。这个项目能同时锻炼记忆管理、工具调用和对话流程设计的能力,也是企业中最常见的Agent应用场景之一。
这个阶段建议花3-4周。
第四阶段:多智能体协作
单个Agent能力有限,真正的企业级应用往往需要多个Agent协同工作。这是目前AI Agent领域最前沿、也最具挑战性的方向。
三种经典协作模式
多智能体系统中有几种经典的协作模式:
- 管理者-执行者模式:一个"管理者"Agent负责任务分解和分配,多个"执行者"Agent各司其职
- 辩论模式:多个Agent从不同角度分析同一问题,通过"辩论"达成更优解
- 流水线模式:Agent按顺序处理任务,前一个Agent的输出是后一个的输入
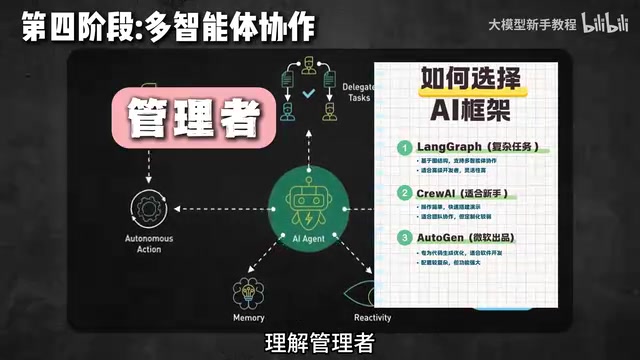
多智能体框架选择
目前主流的多智能体框架包括:
-
AutoGen(微软出品):由微软研究院于2023年开源,其设计哲学是将多Agent协作抽象为"可对话的Agent"(Conversable Agent)模型。每个Agent既可以发送消息,也可以接收并响应消息,人类用户也可以作为一种特殊Agent参与协作。AutoGen的核心优势在于灵活性——它支持LLM Agent、工具执行Agent和人类代理的混合编排,适合需要人机协同的复杂场景。
-
CrewAI:以"角色扮演"为核心理念,用"角色"(Role)、"目标"(Goal)和"背景故事"(Backstory)来定义每个Agent的身份,用"任务"(Task)来描述工作内容,用"团队"(Crew)来组织协作关系。这种拟人化的抽象降低了非技术背景人员的理解门槛,定义Agent的角色、目标和工具,更直观易用。
值得关注的是,2024年兴起的Agent编排标准化趋势——包括Anthropic提出的MCP(Model Context Protocol)协议,正在尝试解决不同框架、不同模型之间的互操作性问题,这将是多智能体领域未来的重要发展方向。
这个阶段建议花3-4周,完成2-3个完整项目来巩固所学。
学习建议与现实思考
三个月够吗?
坦率地说,三个月的时间框架是有条件的:
- 你需要有一定的编程基础(至少熟悉Python)
- 每天能投入2-3小时以上的有效学习时间
- 以项目驱动学习,而不是被动看视频
如果你是纯零基础,可能需要额外1-2个月来补齐编程基础。
避免三个常见误区
- 不要只学框架不学原理:框架会迭代,但ReAct范式、记忆机制等核心概念是通用的
- 不要追求大而全:先精通一个框架(如LangChain),再横向扩展
- 重视工程能力:企业级Agent开发不只是调API,还涉及错误处理、日志监控、成本控制等工程化问题
就业前景
AI Agent开发目前确实是就业市场的热门方向,但"学完即就业"的说法需要理性看待。掌握这条学习路线的知识体系,能让你具备胜任相关岗位的技术基础,但实际就业还取决于项目经验、问题解决能力和对业务场景的理解深度。
最重要的一点:动手做项目,永远比看视频更有价值。
核心要点
- AI Agent学习可分为四个阶段:大模型基础、Agent核心范式、记忆与工具、多智能体协作
- ReAct(思考-行动-观察)是当前最主流的Agent设计范式,源自2022年学术论文,理解它是掌握Agent开发的关键
- 记忆机制(短期上下文窗口+长期向量数据库)和工具调用能力是让Agent从玩具变成生产力工具的核心
- 多智能体协作(AutoGen/CrewAI)代表了企业级Agent应用的前沿方向,MCP等标准化协议正在推动生态成熟
- 三个月学习路线需要编程基础和持续投入,项目驱动学习比被动看视频更有效
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。