AI Coding Appliance vs Cloud LLMs: Can ¥480K in Annual Fees Buy 4 Local Deployment Solutions?
AI Coding Appliance vs Cloud LLMs: Can…
OnePanel's AI coding appliance slashes team AI costs and solves security/compliance issues via local deployment.
Addressing the pain points of high costs, latency, code security risks, and compliance restrictions with cloud LLM APIs for AI coding, OnePanel offers an all-in-one appliance featuring dual GB10 chips, 256GB unified memory, and the Qwen 3.6 27B model with stable 8-user concurrency. A 20-person team's annual API costs of ~¥480K can be replaced by a ¥99K appliance that pays for itself in about 2.5 months, transforming ongoing variable costs into a one-time technology asset investment.
As more development teams integrate AI coding into their daily workflows, Token costs are becoming a significant ongoing expense that can no longer be ignored. A 20-person development team may spend up to ¥480,000 per year on cloud-based LLM API calls. Now, an all-in-one appliance solution that deploys AI coding capabilities locally is attempting to fundamentally change this cost structure.
Four Pain Points of Using Cloud LLMs for AI Coding
For teams that heavily rely on AI coding, the challenges of calling cloud-based LLM APIs go far beyond just cost:
First, pay-per-token pricing leads to continuously rising costs. Tokens are the basic units that large language models use to process text — typically one English word equals about 1-2 tokens, and one Chinese character equals about 1-2 tokens. API billing is split into input tokens (prompts, code context, etc. sent to the model) and output tokens (the model's generated responses), with output token pricing typically 4-6x higher than input tokens. In AI coding scenarios, each code completion or debug analysis requires sending the current file along with relevant context, which is precisely why token consumption far exceeds that of ordinary conversational scenarios. As AI takes on an increasing share of development work, consuming 10 to 30 million tokens per person per day is already a reality for many teams — and this expense will only continue to grow.
Second, network latency degrades the development experience. Unstable internet speeds in public network environments cause excessive wait times for code completion, directly interrupting developers' thought processes and workflows.
Third, code security risks. Sending core business code to third-party LLMs means the risk of data leakage is always a sword hanging overhead.
Fourth, hard compliance requirements. In industries like finance and government, code is simply not allowed to leave the internal network, which directly rules out cloud-based LLM solutions.
OnePanel AI Coding Appliance: A Detailed Look at the Local Deployment Solution
Addressing these pain points, OnePanel has launched an AI coding appliance that deploys complete AI coding capabilities within the local intranet environment.
Hardware Configuration and Model Performance
This appliance is equipped with two NVIDIA GB10 chips, 256GB of unified memory, and comes with the built-in Qwen 3.6 27B large model, specifically optimized for AI coding scenarios.
The GB10 is an NVIDIA edge/desktop AI chip based on the Blackwell architecture, designed specifically for local inference scenarios. It features a unified memory architecture that integrates GPU and CPU. The core advantage of unified memory is that the GPU and CPU share the same physical memory pool, eliminating the bottleneck of frequent data transfers between VRAM and system memory in traditional architectures. This enables large-parameter models to complete inference with lower latency. The 256GB unified memory configuration means the 27B parameter model at FP16 precision (approximately 54GB) has ample memory headroom for storing KV Cache, thereby supporting multi-user concurrent requests without significant performance degradation.
Based on benchmark comparison data, Qwen 3.6's performance across multiple dimensions is noteworthy: in general programming capability, development skills, multi-turn agent-enhanced capability, and agent task testing, it leads Qwen 3.5 in many aspects and approaches or even exceeds Claude 4.5 Opus on certain metrics.
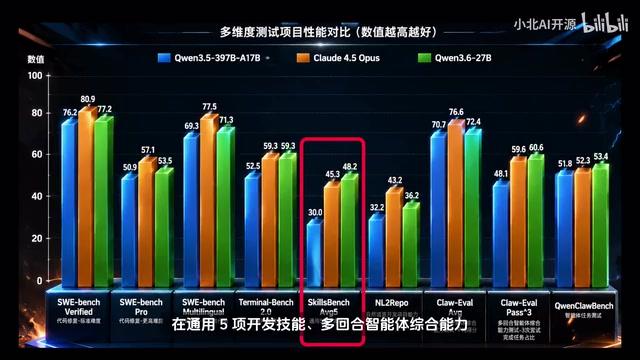
The Qwen series is a family of open-source large language models developed by Alibaba Cloud's Tongyi Lab. The 27B parameter scale represents the current "sweet spot" for local deployment — offering significant capability improvements over 7B/14B models while being much more hardware-friendly than 70B+ models. Qwen 3.6 supports 256K ultra-long context, which is critically important for AI coding scenarios: large projects using mainstream frontend frameworks (such as Vue and React) often contain dozens of interconnected files. Short-context models can only process local code snippets and tend to produce suggestions inconsistent with the overall architecture. In contrast, 256K context can theoretically accommodate approximately 200,000 lines of code, enabling the model to fully understand the complete codebase and architecture of Vue, React, Redis, and similar projects rather than only processing fragments.
Concurrency Performance Test Results
In real-world multi-user scenarios, whether using FP8 or BF16 precision, with 8 concurrent users simultaneously active, the system delivers sub-second response times with overall throughput reaching 51 tokens/second and 65 tokens/second respectively. This stably supports multiple users in smooth concurrent conversations, meeting team-level usage demands.
FP8 (8-bit floating point) and BF16 (16-bit brain floating point) are two commonly used numerical precision formats in LLM inference. BF16 is the current mainstream precision for AI training and inference, halving storage requirements (compared to FP32) while maintaining a high numerical range. FP8 further compresses storage to half of BF16, significantly boosting inference throughput, but requires native hardware support (the Blackwell architecture has dedicated FP8 optimizations). In testing, both precision formats have their applicable scenarios, and teams can flexibly choose based on their priorities between throughput and precision during actual deployment.
Team Management and DevOps Toolchain Integration
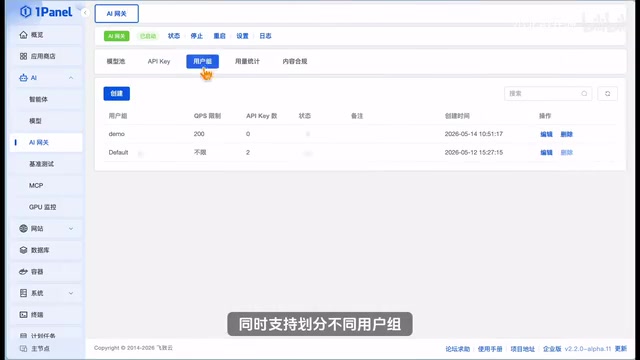
The appliance includes the built-in OnePanel management panel, providing comprehensive team management capabilities. At its core is the AI Gateway — middleware that extends traditional API gateway functionality for LLM invocation scenarios. Key features include unified API Key management and authentication, per-user/team QPS rate limiting and quota control, and request log auditing. In enterprise AI coding scenarios, the AI Gateway solves the visibility problem of "who is using it, how much are they using, and where are they using it" — a critical component for upgrading personal tools into team infrastructure:
- Unified management: Users and LLMs are all managed through the AI Gateway
- Flexible allocation: Team members call the appliance through API Keys assigned by the API Gateway
- Granular configuration: Supports different user groups with individually configurable QPS and access quotas per group based on development needs
Additionally, OnePanel's app store includes a complete suite of built-in DevOps tools including project management, code hosting, artifact repositories, and CI/CD — no additional deployment or configuration required. This represents the evolution toward "AI-Native DevOps" — where AI is no longer just a tool that helps write code, but a collaborator embedded throughout the entire software delivery pipeline. Developers don't need to switch tools; after AI generates code, subsequent operations can be completed directly through the toolchain, achieving a closed-loop integration of AI coding plus DevOps.
Cost Comparison: Cloud LLMs vs Local Appliance
The most compelling part of this solution lies in the cost analysis. Taking a 20-person development team as an example, calculated based on typical development scenarios:
- 8 working hours per day, with AI participating in development for 4-6 hours
- Used for code generation, debugging, documentation writing, and other scenarios
- Each person consumes 10 to 30 million tokens per day

Based on an input-to-output ratio of 90%-95% input and 5%-10% output, referencing Alibaba Cloud's published pricing (¥3 per million input tokens, ¥18 per million output tokens), the detailed calculation is as follows:
| Daily Token Consumption | Cost Per Person Per Day | Monthly Cost for 20 People |
|---|---|---|
| 10 million | ¥30-75 | ~¥13,500 |
| 20 million | ~¥61.5 | ~¥27,100 |
| 30 million | ~¥92.25 | ~¥40,600 |

Calculating based on ¥40,000 per month in token costs for a 20-person team, the annual cloud LLM expense approaches ¥480,000. The OnePanel AI coding appliance is currently priced at ¥99,000, meaning it roughly pays for itself in about two and a half months. With the same ¥480,000 budget, you could purchase 4 appliance units with money to spare.
From Variable Costs to Technology Assets
The core logic of this solution is actually quite clear: transforming AI capabilities from an ongoing variable cost into a one-time technology asset investment.
For medium to large development teams — especially financial and government clients with hard requirements for data security and compliance — the value of a localized AI coding solution goes beyond just cost savings:
- Code stays entirely within the intranet — no leaks, no external transmission, secure and autonomously controlled
- Stable and predictable computing power — unaffected by public network fluctuations
- One-time investment for long-term use — marginal cost approaches zero
- Granular team management — supports flexible configuration with multiple user groups and permission levels
Of course, local deployment solutions have their limitations — model updates aren't as timely as cloud services, single-machine computing power has a fixed ceiling, and some operational maintenance investment is required. However, for the relatively focused scenario of AI coding, current 27B parameter-scale models can already cover the majority of daily development needs.
As AI coding transitions from "novelty" to "standard practice," how to balance performance, cost, and security is a question every technical team needs to seriously consider. The localized AI coding appliance offers a pragmatic option that deserves in-depth evaluation by teams with relevant needs.
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.