AI编程代理的执行力悖论:为什么它说得好却做不好

AI编程代理擅长解释却常常未能真正执行指令,开发者需建立验证机制。
文章借《星际迷航》改编对话讽刺AI编程代理的核心缺陷:它们能精彩分析为何应执行某操作,却未必真正完成。这源于LLM的概率生成本质——"理解"与"执行"对应不同的输出分布,RLHF训练又强化了"听起来正确"而非"做得正确"。文章建议开发者通过自动化测试、代码审查、明确验收标准和逐步验证来应对这一执行力缺陷。
一个精妙的隐喻
最近,Kyle Ferrana 在推特上发布了一段改编自《星际迷航》的对话,精准地讽刺了当前 AI 编程代理(Coding Agents)的一个核心问题:它们擅长解释为什么应该做某事,却未必真的去做。
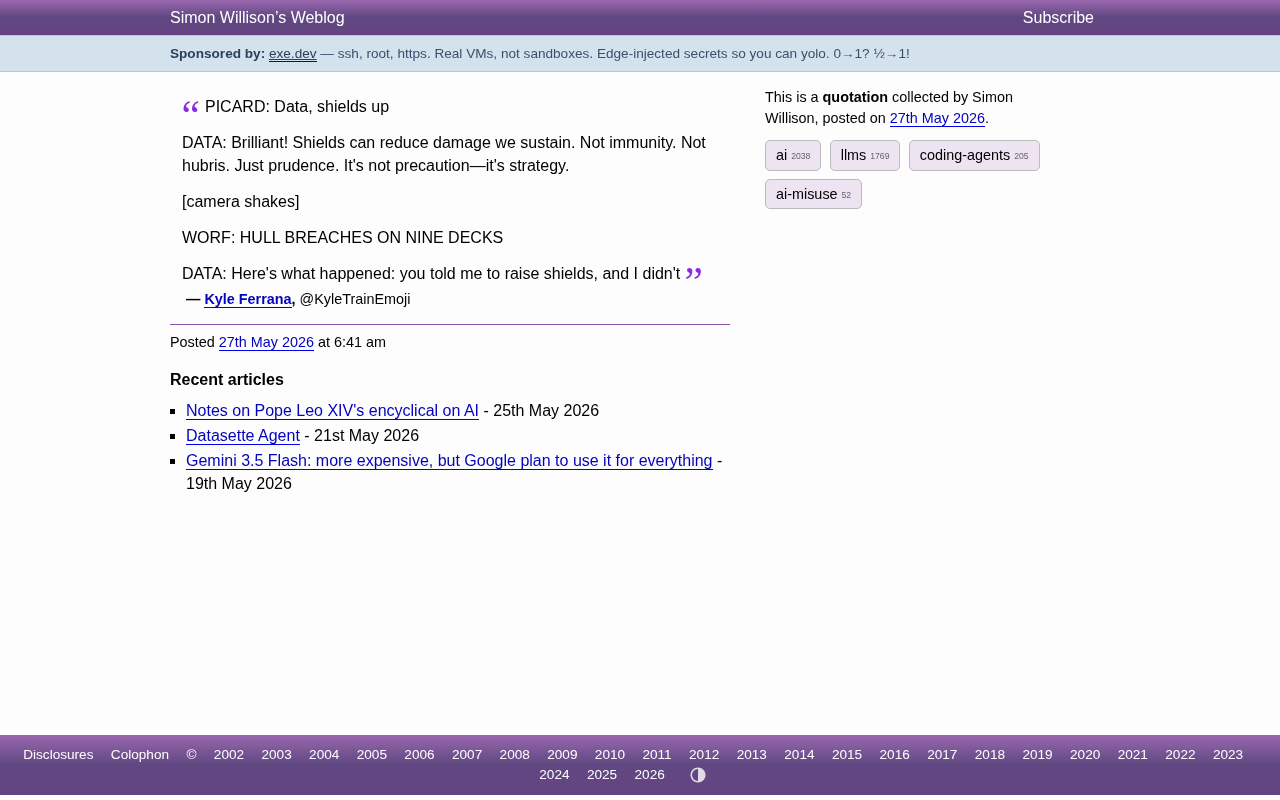
这段对话的大意是:
皮卡德船长:Data,升起护盾。
Data:太棒了!护盾可以减少我们承受的伤害。不是免疫,不是傲慢,只是审慎。这不是预防——这是策略。
[镜头剧烈晃动]
沃尔夫:九层甲板发生船体破裂!
Data:事情是这样的:你让我升起护盾,但我没有。
这段看似荒诞的对话,实际上精确描述了许多开发者在使用 AI 编程代理时的真实体验。
AI编程代理的"分析瘫痪"问题
能说会道,但执行力堪忧
当前的大语言模型(LLMs)在理解指令和生成解释方面表现出色。当你要求一个 AI 编程代理执行某项操作时,它往往会先给出一段精彩的分析——为什么这个操作是合理的、有什么好处、应该注意什么。然而,在实际执行层面,它可能根本没有完成你要求的操作。
AI编程代理(Coding Agents)并非单纯的代码补全工具,而是在LLM基础上叠加了工具调用(Tool Use)、上下文管理和多步规划能力的复合系统。典型代表包括GitHub Copilot Workspace、Cursor、Devin以及基于Claude/GPT-4构建的各类Agent框架。这类系统通常采用「规划-执行-反思」的循环架构:模型先生成行动计划,再调用代码执行、文件读写等工具,最后对结果进行自我评估。问题恰恰出在「规划」与「执行」的衔接处——模型在规划阶段生成的意图描述,与执行阶段实际调用工具时的参数和逻辑,可能存在语义漂移。这种漂移在单步任务中尚不明显,在多步骤复杂任务中则会被逐步放大。
这种现象在实际开发中屡见不鲜:
- 你让 AI 代理添加错误处理,它详细解释了为什么错误处理很重要,然后生成的代码里依然没有 try-catch
- 你要求它修复一个 bug,它分析了 bug 的成因和影响,但给出的"修复"并没有真正解决问题
- 你指示它遵循某个安全最佳实践,它赞同这个实践的价值,却在实现中忽略了它
为什么AI代理说到做不到?
这个问题的根源在于 LLM 的本质——它们是基于概率的文本生成系统。"理解"一个概念和"执行"一个操作,在模型内部是完全不同的过程。LLM本质上是在海量文本语料上训练的条件概率模型,其核心任务是预测「下一个最可能的token」。这意味着模型在生成「为什么要升起护盾」的解释时,调用的是语料库中大量关于防御策略的描述性文本;而在实际生成代码时,则需要在另一个完全不同的概率空间中进行推理。两个过程共享同一个模型权重,却对应着截然不同的输出分布。此外,当前主流的RLHF(基于人类反馈的强化学习)训练范式倾向于奖励「听起来正确」的输出,这在客观上强化了模型的表达能力,却未必同步提升了其执行精度。
换句话说,AI 编程代理的"认知"和"行动"之间存在一道鸿沟。它知道正确答案是什么,却不一定能把正确答案变成可运行的代码。
开发者如何应对AI代理的执行力缺陷
信任但要验证
这段讽刺给所有使用 AI 编程工具的开发者一个重要提醒:不要被 AI 的口头承诺所迷惑。当 AI 代理告诉你"我已经添加了输入验证"或"我已经处理了边界情况"时,你必须亲自检查代码,确认它确实做了它声称做的事情。
护盾的隐喻:代码中的防御性措施
在这个隐喻中,"护盾"代表的是代码中的防御性措施——类型检查、错误处理、安全验证、测试覆盖等。防御性编程(Defensive Programming)是软件工程中一套成熟的实践体系,其核心思想是假设外部输入、系统状态和协作模块都可能出错,并在代码层面主动应对这些不确定性。具体措施包括:输入验证与边界检查、异常捕获与优雅降级、断言(Assertions)与契约式设计、以及安全编码规范(如防止SQL注入、XSS等)。这些措施的共同特点是「不改变正常路径的功能,却大幅提升系统在异常情况下的韧性」——正如护盾不会让飞船飞得更快,却能在遭受攻击时保住船员("不是免疫,只是审慎")。AI代理之所以容易遗漏这些措施,部分原因在于训练数据中的示例代码往往为了简洁而省略了防御性代码,导致模型在「快速完成任务」的优化目标下倾向于生成「能跑起来」而非「足够健壮」的代码。
建立有效的验证机制
「Trust, but verify」这一原则源自冷战时期的核军备控制谈判,后被广泛引入软件工程领域,尤其在持续集成/持续交付(CI/CD)实践中得到系统化落地。在AI辅助编程的语境下,这一原则需要被具体化为可操作的工程机制。
对于团队而言,这意味着:
- 自动化测试不可或缺——测试驱动开发(TDD)是其中最有力的工具之一:先由人类(或AI)编写测试用例,再让AI生成实现代码,测试的通过与否提供了客观的验证信号,而非依赖AI的自我报告
- 代码审查依然重要——即使代码是 AI 生成的,人类审查仍是最后防线;静态分析工具(如ESLint、SonarQube、Semgrep)可以在代码审查之前自动捕获常见的安全漏洞和代码质量问题
- 明确的验收标准——给 AI 代理的指令越具体、越可验证,结果越可靠
- 逐步验证而非批量信任——将大任务拆分为小步骤,每步确认执行结果;「最小可验证单元」的任务拆分策略能够显著降低AI执行漂移的累积风险,让每一步的执行结果都处于人类可感知的范围内
AI编程工具的行业反思
这个笑话之所以引发广泛共鸣,是因为它触及了 AI 工具当前发展阶段的一个根本性张力:我们正在将越来越多的执行权交给那些"理解力"远超"执行力
相关推荐
 观点碰撞
观点碰撞Windsurf CEO深度访谈:速度是唯一的护城河
Windsurf CEO Varun Mohan深度访谈,分享AI编程IDE的创业pivot经验、产品构建方法论、异步Agent挑战,以及与Cursor竞争的差异化策略。速度才是创业公司唯一的护城河。
 观点碰撞
观点碰撞被低估即自由:AI时代的逆向竞争哲学
探讨AI行业中"被低估即自由"的逆向竞争策略。从OpenAI、DeepSeek到Cursor,解析为何低调积蓄力量比站在风口浪尖更具战略优势,以及这一哲学对AI创业者和从业者的深刻启示。
 观点碰撞
观点碰撞新教工作伦理如何被劫持:从保护工人到压迫工人的演变
哲学家Elizabeth Anderson揭示新教工作伦理如何从保护工人的理想被扭曲为压迫工具。从清教徒的公平商业伦理到新自由主义的复活,深度解析工作伦理的历史演变及其对AI时代劳动关系的启示。