AI编程代理基准测试:80+工具横评排名与选型指南

AI编程代理工具横评项目,覆盖80+工具的基准测试与选型指南
GitHub用户murataslan1创建的ai-agent-benchmark项目,系统化对比了80多款AI编程代理工具(包括Devin、Cursor、Claude Code、GitHub Copilot等),采用SWE-Bench基准测试进行性能排名,并整合定价信息,为开发者提供从性能到性价比的全面选型参考。项目揭示了2025年AI编程市场从代码辅助向自主编程演进的趋势。
概述
AI编程助手市场正经历爆发式增长,开发者面临前所未有的选择难题。从Devin、Cursor到Claude Code、GitHub Copilot,市场上已涌现出超过80款AI编程代理工具,功能定位和定价策略各不相同。
GitHub用户murataslan1创建的ai-agent-benchmark项目,通过系统化的基准测试和横向对比,为开发者整理了一份覆盖面广、数据详实的选型参考指南。
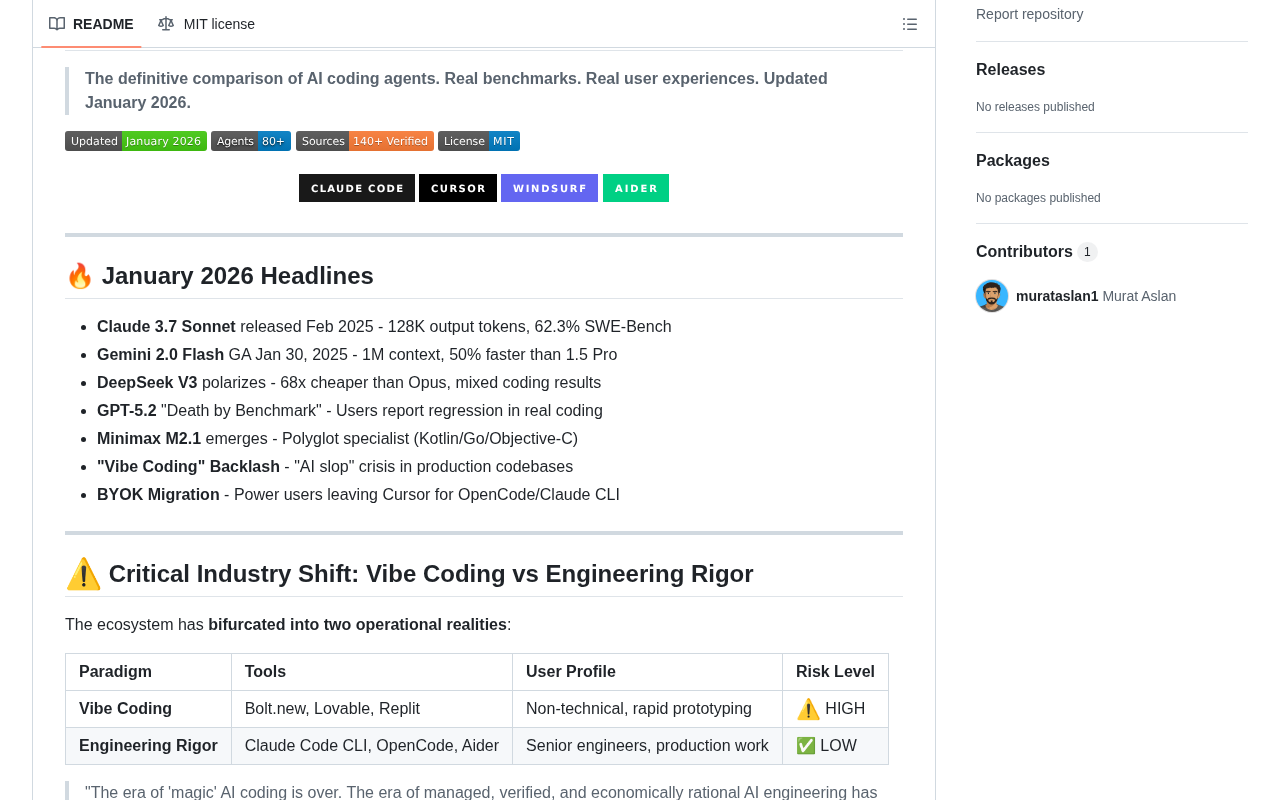
项目覆盖了哪些AI编程代理工具
该项目收录了80多款AI编程代理工具,几乎涵盖了当前市场上所有主流产品和值得关注的新兴选手。其中包括开发者讨论度最高的几款:
-
Devin:Cognition Labs推出的全自动AI软件工程师,能够独立完成从需求理解到代码提交的完整流程。Devin于2024年3月首次公开演示,被称为"世界上第一个AI软件工程师"。它的核心技术架构基于大语言模型的Agent框架,具备独立的代码编辑器、浏览器和终端环境,能够在一个沙盒化的开发环境中自主完成从阅读需求文档、搜索技术方案、编写代码、运行调试到提交Pull Request的完整软件开发流程。这种"端到端自主开发"的范式与传统的代码补全工具有本质区别——后者只是在开发者编码过程中提供片段建议,而Devin试图替代开发者完成整个任务链。
-
Cursor:基于VS Code深度改造的AI增强编辑器,以流畅的交互体验著称。Cursor由Anysphere公司开发,其技术路线是在VS Code的开源代码基础上进行深度Fork和改造,而非简单地开发一个VS Code插件。这种架构选择使得Cursor能够在编辑器的底层实现AI功能的深度集成,包括对编辑器的光标移动、文件导航、终端操作等核心交互进行AI增强。Cursor的核心能力包括Tab键智能补全(能预测开发者接下来要编辑的多个位置)、内联编辑(Cmd+K直接在代码中描述修改意图)、以及Chat模式(能够感知整个项目的代码库上下文)。2024年Cursor的用户量经历了爆发式增长,成为AI原生IDE这一新品类的代表性产品。
-
Claude Code:Anthropic推出的命令行编程助手,擅长处理复杂的多文件编辑任务。Claude Code采用了与IDE插件截然不同的交互范式——开发者在终端中通过自然语言与AI对话,Claude Code直接在本地文件系统上读取、创建和修改代码文件。这种命令行原生的设计理念源于一个观察:许多高级开发者的工作流本身就以终端为中心(使用Vim/Neovim、tmux等工具),命令行工具能够更自然地融入这类工作流。Claude Code的技术优势在于Anthropic的Claude模型本身在长上下文理解和复杂推理方面的能力,使其在处理需要跨多个文件进行关联修改的复杂重构任务时表现突出。
-
GitHub Copilot:微软与GitHub联合打造的AI编程伴侣,拥有最大的用户基数。Copilot于2021年6月首次以技术预览形式发布,是最早进入市场的AI编程助手之一。其最大的竞争优势在于生态整合:作为GitHub平台的原生产品,Copilot能够无缝集成到全球超过1亿开发者使用的GitHub工作流中,包括代码仓库、Pull Request审查、GitHub Actions CI/CD等环节。Copilot经历了从单纯的代码补全到对话式编程(Copilot Chat)再到自主编程代理(Copilot Coding Agent)的三个阶段演进,2025年已正式进入自主编程代理的竞争行列。
除此之外,还有数十款定位各异的工具,共同构成了目前最完整的AI编程代理对比数据库之一。
SWE-Bench基准测试排行榜解读
项目采用业界公认的SWE-Bench作为核心评测标准。SWE-Bench是一个基于真实GitHub Issue构建的软件工程基准测试,要求AI代理理解问题描述并生成正确的代码修复方案。
SWE-Bench由普林斯顿大学的研究团队于2023年10月发布,其数据集从12个流行的Python开源项目(包括Django、Flask、scikit-learn、sympy等)中提取了2294个真实的GitHub Issue及其对应的Pull Request修复方案。每个测试用例要求AI代理在给定代码仓库的特定历史版本上,仅根据Issue描述生成正确的代码补丁,并通过项目自带的单元测试验证。后来研究团队又推出了SWE-Bench Verified(经人工验证的500道高质量子集)和SWE-Bench Lite(300道较简单的子集),以提供不同难度层次的评测。
为什么SWE-Bench是可靠的评测标准
- 真实任务驱动:测试用例来自真实开源项目的Bug修复和功能需求,而非人工构造的编程题。这与此前广泛使用的HumanEval、MBPP等基准测试形成鲜明对比——后者只考察独立函数级别的代码生成能力,而SWE-Bench要求AI理解整个项目的代码结构、依赖关系和上下文语义,这更接近真实软件工程的复杂度。
- 多语言多场景覆盖:涵盖Python、JavaScript等多种编程语言和不同类型的项目
- 端到端能力评估:考察的是从问题理解到代码生成的完整解决能力,不只是片段补全
通过统一的评测标准,开发者可以更客观地比较不同AI编程工具的实际编码水平,避免被营销宣传误导。
定价信息对比与性价比分析
除了性能排名,项目还整合了各工具的定价信息。这对个人开发者和企业团队来说同样关键——在AI编程工具的选择中,性价比往往是最终决策的关键因素。
目前市面上的AI编程工具定价模式差异很大:
- 按月订阅:如Cursor Pro(约20美元/月)、GitHub Copilot(个人版10美元/月,企业版19美元/月),适合日常高频使用。这种模式的优势在于成本可预测,开发者可以不受限制地使用工具的核心功能。
- 按使用量计费:如部分API驱动的工具,适合用量波动较大的团队。这类模式通常按Token消耗量或API调用次数收费,在使用量较低时成本更优,但在高频使用场景下可能产生较高费用。
- 免费+增值:部分工具提供基础免费版,高级功能需付费解锁。例如GitHub Copilot推出了免费版本以扩大用户基数,但在模型选择和使用额度上有所限制。
统一的价格对比让开发者能够在性能和成本之间找到最佳平衡点。
2025年AI编程代理市场趋势
这份覆盖80多款工具的数据揭示了AI编程领域的几个重要趋势:
市场竞争格局
80+的工具数量说明市场仍处于高度竞争的早期阶段。大量创业公司和科技巨头同时涌入,产品迭代速度极快,几乎每周都有新工具发布或重大更新。这种竞争态势与移动互联网早期的App爆发期类似,市场最终大概率会经历整合和淘汰,但目前仍处于"百花齐放"的阶段。
能力趋同与场景分化
头部AI编程工具在基础代码生成能力上的差距正在缩小,但在特定场景上开始明显分化。比如大型代码库的上下文理解、跨文件重构、测试用例生成等方面,不同工具的表现差异显著。这种分化的背后是各工具在Agent架构设计上的不同选择——有的侧重于上下文窗口的高效利用,有的侧重于工具调用链的编排能力,有的则在特定编程语言或框架上做了深度优化。
从代码辅助到自主编程
工具形态正从早期的"代码补全"向"自主完成开发任务"快速演进。当前AI编程工具的技术架构正在从"单次推理"向"多步Agent"快速演进。早期的代码补全工具采用的是单次推理模式:将当前代码上下文输入模型,模型一次性输出补全建议。而新一代的AI编程代理采用的是Agent架构,其核心是一个"观察-思考-行动"的循环:AI首先观察当前代码状态和任务要求,然后制定执行计划,接着调用工具(如文件读写、终端命令执行、网络搜索等)执行具体操作,再根据执行结果调整下一步行动。Devin等产品代表了这一方向——AI不再只是提供建议,而是能够独立规划和执行编程任务。ReAct(Reasoning and Acting)框架和Tool Use机制是支撑这一架构演进的关键技术基础。
开发者如何选择合适的AI编程工具
面对80多款工具,开发者可以从以下四个维度进行筛选:
- 任务复杂度:如果主要需求是代码补全和简单生成,轻量级工具即可满足;如果涉及完整功能开发或Bug修复,需要选择具备强上下文理解能力的产品。SWE-Bench的测试结果在这个维度上具有很强的参考价值,因为它直接衡量的就是AI处理真实复杂任务的能力。
- 集成方式:IDE插件(如Copilot)、独立编辑器(如Cursor)、命令行工具(如Claude Code)还是独立Web平台(如Devin),取决于你的工作流偏好。值得注意的是,不同集成方式对AI能力的发挥也有影响——深度集成到编辑器中的工具能够获取更丰富的上下文信息(如光标位置、打开的文件、最近的编辑历史),而命令行工具则在自动化脚本和CI/CD集成方面更具灵活性。
- 团队规模:个人开发者更关注易用性和价格,团队协作则需要考虑权限管理、代码审查集成等企业级功能
- 预算约束:免费方案通常在模型能力和使用额度上有限制,付费方案之间的能力差距也值得仔细对比
项目的价值与使用建议
该项目虽然目前Star数量不多,但其系统化的对比方式填补了市场上缺乏统一评测参考的空白。
不过使用时也需要注意几点:AI编程工具迭代极快,基准测试结果可能在数周内就发生明显变化;SWE-Bench虽然权威,但无法完全还原日常开发中的真实体验——例如它目前主要覆盖Python项目,对其他编程语言的评估能力有限,且无法衡量AI在交互式对话、需求澄清等软技能方面的表现;最终选型建议结合基准数据和实际试用,找到最适合自己工作场景的工具。
总结
在AI编程代理百花齐放的2025年,这类系统化的横评项目为开发者提供了难得的决策参考。无论你是想了解各工具在SWE-Bench上的排名差异,还是想对比不同产品的定价方案,这个项目都值得收藏关注。随着社区贡献者的增加和数据的持续更新,它有望成为AI编程工具选型领域的重要参考资源。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。