Trae实战教程:零基础克隆GitHub项目并生成数据分析报告
用AI编程工具Trae克隆GitHub爬虫项目,爬取小红书数据并生成商业分析报告的完整教程。
文章介绍了如何利用AI编程IDE Trae,在零编程基础下克隆GitHub开源爬虫项目,爬取小红书平台数据,并用Gemini大模型生成深度分析报告。全流程分为工具安装配置、项目克隆运行、数据分析应用三步,展示了AI时代普通人借助开源生态和大模型实现商业洞察的可行路径。
AI时代人人都能编程:从GitHub到商业洞察
编程正在变得越来越平民化。借助AI编程工具,普通人也能把GitHub上的开源项目为己所用,相当于拥有了一个免费的软件工具箱。
这篇文章会完整记录一个实操案例:用Trae这款AI编程IDE,从零开始克隆一个GitHub上的热门爬虫项目,爬取小红书平台数据,再用大模型生成一份有商业价值的分析报告。
整个流程分三步走:工具安装与环境配置 → GitHub项目克隆运行 → 数据深度分析与应用落地。没有任何编程经验也能跟着做完。
Trae是什么?为什么值得用它来编程
AI编程工具的演进背景
集成开发环境(IDE)从最初的文本编辑器演变至今,经历了从Vim、Emacs到Eclipse、Visual Studio,再到VS Code的数十年迭代。AI编程工具的兴起代表了下一个范式转变:2021年GitHub Copilot的发布标志着AI辅助编程进入主流,随后Cursor、Windsurf、Trae等产品相继出现,将AI能力从"代码补全"升级为"自然语言驱动的全流程开发"。这类工具的核心技术是将大语言模型与代码执行环境深度集成,使非专业用户也能通过对话完成原本需要数年编程经验才能实现的操作。
Trae的核心优势
Trae(原名Chain)是一款集成开发环境(IDE),最大的特点是支持用自然语言生成代码、运行项目。跟同类产品Cursor相比,Trae有几个实际的优势:
- 原生中文支持:界面和交互对中文用户更友好,沟通成本低
- 模型选择丰富:集成了Claude 4.0、Gemini 2.5 Pro、GPT 4.1等主流模型
- 价格更实惠:首月3美元,之后每月10美元(Cursor要20美元/月)
- 网络门槛低:登录时需要海外网络环境,日常使用不需要
Trae有CN版和海外版两个版本。CN版接入了豆包、DeepSeek、千问等国内模型,海外版支持Claude、Gemini、GPT系列。如果条件允许,建议优先用海外版,模型整体能力更强。
安装与界面说明
安装过程很简单:打开Trae官网,下载安装包,按提示一步步操作就行。首次启动后选个主题风格,支持导入VS Code或Cursor的已有配置,最后用手机号登录。
打开后的界面是经典的三栏布局:
- 左侧:资源管理器,管理文件和文件夹
- 中间:代码编辑区
- 右侧:AI对话窗口,默认开启Builder智能体模式
右侧的Builder内置了文件系统、终端、联网搜索、预览等工具能力,基本上你只需要用自然语言描述需求,它就能帮你完成操作。
手把手教你克隆GitHub项目
GitHub与开源生态的商业价值
GitHub于2008年创立,2018年被微软以75亿美元收购,目前托管超过3.3亿个代码仓库,月活开发者超过1亿。开源运动的核心理念是"站在巨人的肩膀上"——任何人都可以免费使用、修改和分发开源代码。对普通用户而言,这意味着数十年积累的工程智慧可以零成本获取。爬虫工具、数据分析框架、自动化脚本等原本需要专业团队开发的能力,现在只需找到合适的开源项目即可直接使用。Star数量是衡量项目质量的重要指标,通常反映了社区的认可度和项目的活跃维护状态。
第一步:在GitHub上找到合适的项目
找项目时有几个实用技巧:
- 关键词搜索:支持中英文,比如搜"爬虫""scraper""数据采集"等
- Trending页面:查看近期热门项目,可以按编程语言和时间范围筛选
- 看星标数量:Star数超过1000的项目通常质量不错,维护也比较积极
本次实操选的是一个多平台数据采集工具,支持抓取小红书、抖音、快手、B站、微博、贴吧、知乎等主流平台的公开信息。
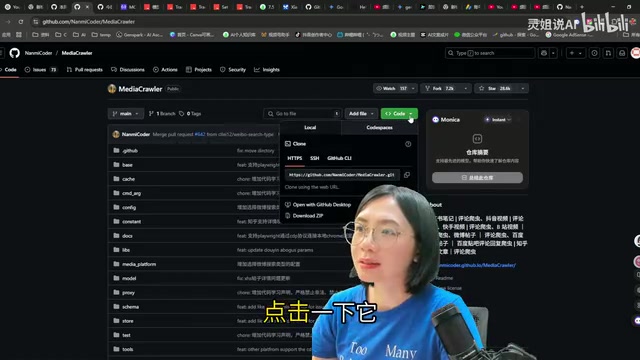
第二步:用Trae一键克隆项目
克隆操作非常简单。在Trae里新建一个文件夹,然后在右侧对话窗口用自然语言告诉Builder:
"请帮我克隆这个项目:[粘贴GitHub仓库的URL]"
Trae会自动执行克隆命令,完成后还会主动解读项目的README文档,告诉你这个项目能做什么、怎么运行、有哪些可配置的参数。整个过程你基本不用动手,像当老板一样看着AI干活就行。
克隆完成后,Trae会整理出关键信息:
- 支持的平台:小红书、抖音、快手、B站等
- 登录方式:扫码登录、手机号登录、Cookie登录
- 爬取类型:关键词搜索、帖子详情页、创作者主页
- 数据保存格式:CSV、JSON、数据库
第三步:运行报错了怎么办
跑项目时遇到报错太正常了,不用慌。处理方式也很直接:把报错信息截图发给Builder,用大白话描述一下情况,它会给出具体的修复方案。
举个例子,运行命令时提示"程序未找到",Builder会告诉你需要先切换到正确的项目目录再执行。把Trae当成一个随时在线的编程高手来对话就好。
数据爬取与AI深度分析实操
网络爬虫的技术原理与合规边界
网络爬虫(Web Scraper)本质上是模拟浏览器行为的自动化程序,通过发送HTTP请求获取网页内容,再解析HTML/JSON数据提取所需信息。现代爬虫工具通常需要处理反爬机制,包括IP限速、验证码、动态渲染(JavaScript执行)等挑战。小红书等平台的公开内容(如帖子标题、点赞数、评论)在技术上可被抓取,但使用时需注意:数据仅限个人研究和商业洞察分析,不得用于大规模转载、训练竞品模型或侵犯用户隐私。各平台的robots.txt文件和服务条款明确了爬取边界,合规使用是前提。
爬取到了什么数据
以"旅行"为关键词爬取小红书热门帖子,最终拿到两个核心数据文件:
Content文件(笔记数据):笔记ID、内容类型(视频/图文)、标题、正文描述、链接URL、发布时间、用户名、点赞数、收藏数、评论数、分享数、IP归属地
Comments文件(评论数据):评论正文、子评论数量、评论点赞数
总共300多条热门帖子的完整数据——相当于把这个领域的爆款内容底层逻辑全部提取出来了。
用Gemini生成三万字分析报告
拿到原始数据后,下一步是交给AI做深度分析。这里选用Google AI Studio中的Gemini 2.5 Pro模型。Gemini 2.5 Pro拥有高达100万token的上下文窗口,是目前商用大模型中上下文容量最大的之一——100万token大约相当于75万个英文单词或约150本普通长度的书籍。这一特性使其特别适合将300多条帖子数据(包含标题、正文、评论等字段)一次性输入模型,不会因为"遗忘
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。