AI编程实测:GPT-5、Gemini 2.5 Pro、Kimi K2、Grok4爬虫任务全部失败
四款顶级大模型在静态爬虫任务中全部失败,Claude仍保持领先
在AI编程擂台赛中,GPT-5、Gemini 2.5 Pro、Kimi K2和Grok 4使用Cursor IDE执行静态网页爬虫任务,结果全部失败。Kimi K2速度最快但内容为空,GPT-5限制10页且正文为空,Grok 4找不到任何链接,Gemini连路径空格都处理不好。而此前Claude成功爬取126页,说明参数规模和品牌不等于工程执行力。
测试背景
在AI编程能力的实际检验中,大模型的表现往往与宣传存在巨大落差。本期AI编程擂台赛第三集,测试者使用同一个IDE(Cursor国际版),对GPT-5、Gemini 2.5 Pro、Kimi K2-0905和Grok 4四款主流大模型进行了静态网页爬虫任务的对比测试。
关于测试工具: Cursor是基于VS Code深度改造的AI原生IDE,其核心特性是将大模型直接集成到代码编辑和终端执行环境中,支持多模型切换。在Cursor的Agent模式下,模型不仅能生成代码,还能自主执行终端命令、读写文件、安装依赖,形成完整的「感知-规划-执行」闭环。这种设置使得测试更贴近真实开发场景,也更能暴露模型在工程执行层面的短板——因为错误会被立即执行并产生真实后果,而非停留在代码生成层面。
关于测试任务: 静态网页爬虫是指针对服务器直接返回完整HTML内容的网页进行数据抓取的技术,与动态爬虫(需要执行JavaScript渲染)相比,理论上难度更低。其核心流程包括:发送HTTP请求获取HTML文档、使用CSS选择器或XPath解析DOM树、提取目标内容、递归跟踪链接。常用工具链包括Python的requests+BeautifulSoup或Scrapy框架。这类任务对AI编程助手而言是一个很好的基准测试,因为它既考验代码生成能力,也考验对目标网站结构的理解和调试能力。
此前的测试中,Claude已经成功爬取了126个页面,成为当前的标杆成绩。那么这四款模型能否超越或至少持平?结果令人大跌眼镜——全部失败。
四款模型执行过程对比
启动速度差异明显
四款模型在接收到相同的爬虫需求后,表现出截然不同的执行策略:
- Grok 4:启动最快,直接开始安装依赖库,没有先写requirements文件,而是直接执行pip install
- Kimi K2:速度惊人,很快就显示Complete状态
- GPT-5:启动明显偏慢,运行了多次虚拟环境配置
- Gemini 2.5 Pro:采取保守策略,必须等虚拟环境完全安装好才开始写代码
工程规范背景: Python虚拟环境(venv/conda)是隔离项目依赖的标准工程实践,避免不同项目间的包版本冲突。规范的流程是:先创建requirements.txt声明依赖,再在虚拟环境中批量安装。Grok 4跳过requirements文件直接pip install,以及Gemini 2.5 Pro串行等待环境安装完成才写代码,都违背了工程最佳实践。前者导致依赖难以复现,后者浪费了可以并行处理的时间窗口,反映出模型对软件工程规范的理解停留在表面。
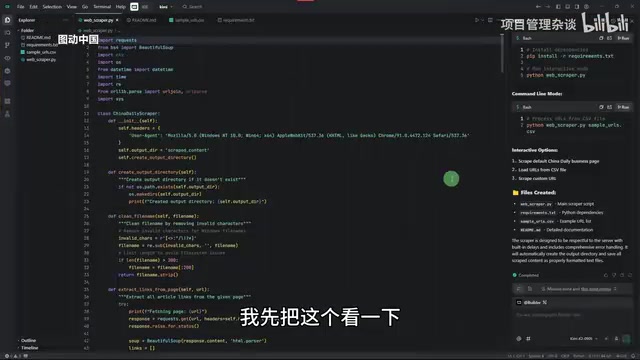
各模型遇到的具体问题
Gemini 2.5 Pro 在环境安装阶段就出了问题——它把文件路径识别错了,原因是路径中包含一个空格。这种基础性错误对于一个顶级大模型来说实在不应该。它的逻辑也存在问题:非要等虚拟环境安装完毕才开始写代码,而不是并行处理。
GPT-5 虽然成功启动了爬取任务,但将最大页面限制设为了10页,且最终爬取的内容全部是空的,正文没有成功抓取。
Grok 4 的表现更加离谱——它不仅安装了一堆平时根本用不到的依赖,还莫名其妙地搞了一个GUI界面出来。最终结果显示"No Links Found",一个链接都没找到。
Kimi K2 虽然完成速度最快,但打开结果文件一看,所有抓取的正文内容都是空的,实质上也是失败的。
为什么会出现「内容为空」? 多款模型出现「正文为空」的问题,通常源于CSS选择器或XPath路径与目标网站实际DOM结构不匹配。现代网站常使用语义化类名(如article__body、post-content)或嵌套较深的div结构,模型若未能正确分析目标页面的HTML结构,就会使用错误的选择器导致抓取结果为空。此外,部分网站会对内容区域使用动态生成的类名或懒加载机制,即便是静态页面也可能存在这类陷阱。GPT-5和Kimi K2的「内容为空」问题,很可能正是选择器定位失败所致。
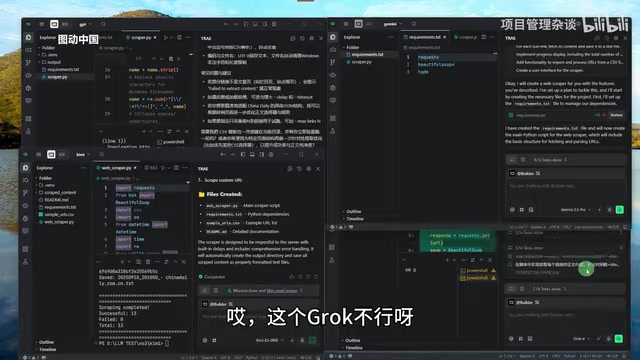
爬虫测试结果汇总
| 模型 | 执行速度 | 爬取页面数 | 内容质量 | 最终结果 |
|---|---|---|---|---|
| Claude (前期测试) | 正常 | 126页 | 正确 | ✅ 成功 |
| Kimi K2-0905 | 最快 | 13页 | 正文为空 | ❌ 失败 |
| GPT-5 | 较慢 | 10页(限制) | 正文为空 | ❌ 失败 |
| Grok 4 | 快 | 0页 | 无内容 | ❌ 失败 |
| Gemini 2.5 Pro | 最慢 | 0页 | 无内容 | ❌ 失败 |
深度分析:为什么全军覆没
这次测试暴露了几个关键问题:
对网页结构的理解不足
静态网页爬虫看似简单,但需要模型准确理解目标网站的DOM结构、链接模式和内容分布。这四款模型显然在这方面的实际执行能力不足。
工程化思维欠缺
Gemini连路径空格都处理不好,Grok安装无关依赖还搞GUI,说明这些模型在实际编程场景中的工程判断力还很弱。
"快"不等于"好"
Kimi K2完成最快,但结果全是空数据。速度优势在质量面前毫无意义。
参数规模不等于工程执行力
业界长期存在一个误区:认为参数规模越大、训练数据越多,模型的编程能力就越强。但实际上,编程执行能力(尤其是Agent模式下的多步骤任务)还高度依赖模型的指令遵循能力、错误自我修正能力和上下文长期记忆能力。GPT-5、Grok 4等模型在基准测试(如HumanEval、SWE-bench)上表现优异,但这些测试通常是单次代码生成,与需要多轮工具调用、动态调试的真实工程任务存在显著差距。这也是为什么「擂台赛」式的实际任务测试比跑分更有参考价值。
对开发者的启示
这个测试结果提醒我们:
- 不要盲目相信模型的品牌光环,实际任务表现才是硬指标
- 在AI辅助编程中,Claude在代码执行类任务上目前仍有明显优势
- 即使是最新版本的顶级模型,在具体工程任务中也可能表现不如预期
- 选择AI编程助手时,应该针对自己的实际使用场景进行测试
- 基准测试(Benchmark)成绩与真实工程任务表现之间存在显著鸿沟,开发者应优先参考贴近自身业务场景的实测数据
总结
本次擂台赛的结果颇具讽刺意味:四款被寄予厚望的顶级大模型,在一个相对基础的静态网页爬虫任务上全部失败,甚至不如之前测试中表现尚可的Claude模型。这说明AI编程能力的竞争远未尘埃落定,模型的参数规模和品牌知名度并不能直接转化为可靠的编程执行力。对于开发者而言,"用哪个模型"这个问题的答案,永远需要通过实际测试来验证。
核心要点
- GPT-5、Gemini 2.5 Pro、Kimi K2、Grok 4在静态网页爬虫任务中全部失败,无一成功抓取有效内容
- Kimi K2完成速度最快但结果为空,Grok 4甚至找不到任何链接,Gemini连路径空格都处理不好
- 此前测试中Claude成功爬取126页,在代码执行类任务上保持明显领先优势
- 模型的品牌知名度和参数规模不能直接转化为可靠的编程执行力
- 开发者选择AI编程工具时应针对实际场景进行测试验证,而非盲目跟风
- Agent模式下的多步骤工程任务与单次代码生成基准测试存在本质差异,后者成绩不能代表前者表现
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。