Ollama+OpenCode本地部署AI编程:零成本替代Cursor的完整方案
用Ollama+OpenCode本地部署千问3 Coder,实现零成本AI编程
文章介绍了一套完全免费的本地AI编程方案:通过Ollama框架部署千问3 Coder 30B编程大模型,搭配开源终端工具OpenCode,实现代码生成、自动调试和一键运行的完整编程体验。该方案无需订阅付费、无需联网,代码隐私完全可控,32GB内存加8GB显存以上的普通电脑即可流畅运行。
AI编程不花钱:本地跑大模型就够了
用 Cursor 或 GitHub Copilot 写代码确实爽,但每月十几二十美元的订阅费,对个人开发者来说多少有点肉疼。好消息是,随着开源大模型的能力飞速提升,我们完全可以在自己电脑上搭一套免费的AI编程环境,效果并不逊色。
本文手把手教你用 Ollama + OpenCode 这套组合,在本地部署千问3 Coder编程大模型,实现代码生成、自动调试、一键运行的完整AI编程体验——全程不花一分钱。
Ollama和OpenCode是什么?
Ollama:一行命令跑大模型
Ollama 是一个开源的本地大模型运行框架,你可以把它理解为大模型的"Docker"。装好之后,一行命令就能下载并运行各种开源模型,不用折腾Python环境、不用手动配置CUDA,对新手非常友好。
之所以用"Docker"来类比,是因为 Ollama 将模型的下载、量化、推理运行时等复杂环节封装成了统一的命令行接口。在 Ollama 出现之前,本地运行大模型通常需要手动配置 Python 虚拟环境、安装 PyTorch 对应版本、配置 CUDA 和 cuDNN 驱动、下载并转换模型权重格式——这一系列操作对非AI从业者来说门槛极高。Ollama 底层基于 llama.cpp 推理引擎,该引擎使用纯 C/C++ 实现,支持 GGUF 量化格式,能够在消费级硬件上高效运行大语言模型。这里提到的"量化"(Quantization)是一种关键的模型压缩技术,通过将模型参数从 32 位浮点数降低到 4 位或 8 位整数表示,大幅减少内存占用和计算量,同时尽可能保留模型的推理能力。这也是为什么一个原本需要 60GB 显存的 30B 参数模型,经过量化后能在 16GB 甚至 8GB 显存的消费级显卡上运行的关键原因。
目前 Ollama 模型库里有大量编程专用模型可选。经过实测,千问3 Coder(Qwen3 Coder) 的 30B 参数版本表现相当亮眼——在普通家用电脑上就能流畅运行,代码生成质量也足够应付日常开发需求。
千问3 Coder 是阿里云通义千问团队推出的编程专用大语言模型,属于 Qwen3 系列的代码特化版本。与通用大模型不同,编程专用模型在训练阶段会大量使用 GitHub 开源代码库、Stack Overflow 问答数据、技术文档等编程相关语料进行微调(Fine-tuning),从而在代码生成、代码补全、Bug 修复、代码解释等任务上获得显著优于通用模型的表现。30B(300亿)参数量是当前本地部署的一个"甜蜜点"——它比 7B 模型有更强的逻辑推理和长上下文理解能力,又不像 70B 或更大的模型那样对硬件要求苛刻。在编程基准测试(如 HumanEval、MBPP 等)中,千问3 Coder 30B 的表现已经接近甚至超过部分早期商业闭源模型,这也是开源模型近两年快速追赶闭源模型的一个缩影。
OpenCode:免费版的Cursor终端
OpenCode 是一款开源AI编程工具,功能定位类似 Cursor,但它天然支持调用本地部署的开源模型。换句话说,搭配 Ollama 使用时,你不需要任何API Key,也不会产生任何费用。
要理解 OpenCode 的定位,有必要先了解它对标的 Cursor。Cursor 是目前最受欢迎的 AI 编程 IDE 之一,它基于 VS Code 深度改造,内置了代码生成、智能补全、多文件编辑等 AI 功能,但其核心依赖云端的 GPT-4、Claude 等闭源模型 API,因此需要付费订阅。OpenCode 的设计思路不同——它是一款运行在终端(Terminal)中的 AI 编程助手,采用 TUI(文本用户界面)交互方式,天然支持通过 OpenAI 兼容 API 格式连接本地模型。由于 Ollama 默认在本地 11434 端口暴露一个兼容 OpenAI API 格式的接口,OpenCode 可以无缝对接,无需额外配置。这种"终端优先"的设计虽然没有图形化 IDE 那样直观,但对于习惯命令行操作的开发者来说反而更高效,且资源占用极低。
安装过程极其简单,下载后开箱即用。
实战教程:三步搭建本地AI编程环境
第一步:安装Ollama并下载千问3 Coder模型
整个环境搭建只需要两件事:
- 安装 Ollama:前往 Ollama 官网 下载对应系统的安装包,安装过程一路默认即可。
- 下载编程模型:安装完成后,在 Ollama 模型库中搜索"Coder",找到千问3 Coder 的 30B 版本,一行命令完成下载。
第二步:安装OpenCode并连接本地模型
下载安装 OpenCode 后,创建一个项目工作目录,在该目录下打开命令行(CMD 或 Terminal),通过命令启动 OpenCode 并指定使用本地的千问3 Coder模型。
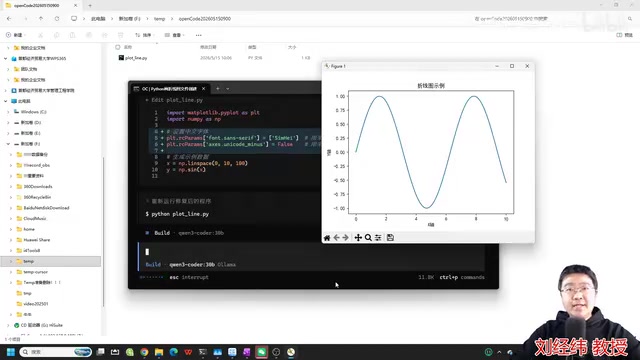
第三步:用自然语言写代码
环境就绪后,直接用中文下达编程指令就行。比如输入:
"帮我创建一个Python文件,画一个折线图"
OpenCode 会调用本地的千问3 Coder 模型开始生成代码。整个过程完全在本机完成,断网都能用,不需要调用任何云端API。几秒钟后,模型就会自动生成完整的Python代码文件,保存到当前工作目录。
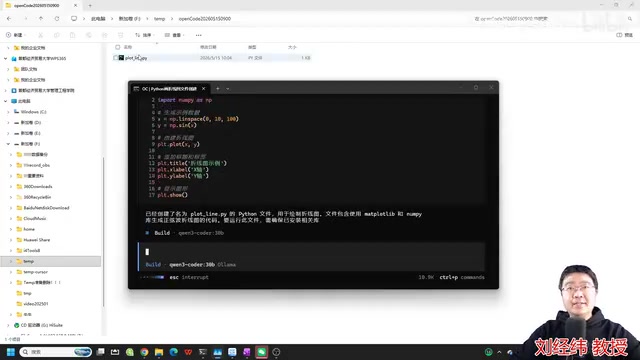
自动调试能力演示:AI帮你修Bug
代码生成只是第一步,这套方案真正让人惊喜的是自动调试能力。
在实际演示中,生成的折线图程序首次运行后出现了中文乱码——这是Python绑定matplotlib时的经典问题。这时候不需要自己去查Stack Overflow,直接告诉AI:
"程序运行后画图,图中出现了中文乱码,请修复"
AI会自动定位问题根源,在代码中精准插入中文字体配置(通常就两行代码),然后自动重新运行程序验证修复效果。
这里值得展开说说这个中文乱码问题的技术原理。matplotlib 是 Python 生态中最常用的数据可视化库,但它默认使用的字体(通常是 DejaVu Sans)不包含中文字符集,因此在图表中显示中文时会出现方块乱码。这个问题在中文开发者社区中极为常见,几乎是每个 Python 数据分析初学者都会遇到的"第一个坑"。修复方法通常是在代码中手动指定一个包含中文字符的字体,例如在 Windows 系统上使用 SimHei(黑体)或 Microsoft YaHei(微软雅黑),在 macOS 上使用 PingFang SC(苹方)。AI 能够精准修复这个问题,恰好体现了编程大模型在处理"高频常见问题"上的优势——这类问题在训练数据中出现过大量的问答和解决方案,模型已经形成了非常可靠的修复模式。
修复完成后,折线图上的中文标签正常显示。AI还会输出一份修复总结,清楚说明改了什么、为什么这样改。这种"写代码→跑程序→发现问题→自动修复"的闭环体验,和付费工具几乎没有差别。
为什么推荐这套本地部署方案?
完全免费,没有隐性成本
Ollama 开源免费,OpenCode 开源免费,千问3 Coder 模型开源免费。所有计算都在本地GPU或CPU上完成,不产生任何API调用费用。对比 Cursor Pro 每月20美元、GitHub Copilot 每月10美元的订阅价格,长期使用省下的钱相当可观。
从成本结构上看,选择本地部署还是云端 API,本质上是在成本结构、响应延迟、隐私安全和模型能力之间做权衡。云端 API(如 OpenAI、Anthropic)提供的是最顶尖的闭源模型能力,但按 Token 计费——以 GPT-4o 为例,每百万输入 Token 约 2.5 美元,频繁使用时成本会快速累积。Cursor Pro 的 20 美元月费实际上也包含了请求次数限制,超出后需要额外付费。本地部署的边际成本几乎为零(只有电费),但前期需要一定的硬件投入,且模型能力受限于本地算力。不过随着模型量化技术和开源模型能力的双重进步,这个差距正在快速缩小。对于日常的代码生成、脚本编写、Bug 修复等中等复杂度任务,本地 30B 量化模型已经能提供令人满意的体验,只有在处理极其复杂的架构设计或超长上下文推理时,云端大模型才有明显优势。
代码隐私完全可控
所有代码和数据都留在你自己的电脑上,不会上传到任何云端服务器。如果你在开发涉及商业机密或企业内部系统的项目,这一点尤为关键。
功能覆盖日常开发需求
从实测来看,这套方案具备以下核心能力:
- 自然语言生成代码:用中文描述需求,AI自动输出完整可运行的代码
- 智能调试修复:分析报错信息,定位问题并自动修改代码
- 一键运行验证:在终端中直接执行程序,查看运行结果
- 多轮迭代优化:根据反馈不断改进代码,直到满足要求
工具生态持续壮大
Ollama 上的模型不只能配合 OpenCode 使用,还兼容 Cline、Aider 等多种开源AI编程工具,以及当下流行的 Vibe Coding 等新兴编程范式。随着开源社区的持续投入,可选的模型和工具只会越来越多。
这里提到的 Vibe Coding(氛围编程)是由 OpenAI 联合创始人 Andrej Karpathy 在 2025 年初提出的概念,指的是开发者完全通过自然语言描述需求,由 AI 生成全部代码,开发者本人不直接编写任何代码,只负责描述意图、审查结果和提出修改要求。这种范式代表了 AI 编程工具从"辅助编码"向"自主编码"演进的趋势。与之相关的 Aider 专注于在终端中通过对话修改现有代码仓库,支持 Git 集成和多文件编辑;Cline 则是 VS Code 的插件形式,提供类似 Cursor 的体验但支持自定义模型后端。这些工具共同构成了一个日益成熟的开源 AI 编程工具生态,而 Ollama 作为统一的本地模型运行层,成为了连接这些工具与开源模型之间的关键桥梁。
本地跑AI编程模型需要什么配置?
运行千问3 Coder 30B 参数模型,建议电脑至少满足以下配置:
| 硬件 | 推荐配置 | 说明 |
|---|---|---|
| 内存 | 32GB 及以上 | 模型加载需要较大内存空间 |
| 显卡 | NVIDIA独显(8GB显存以上) | 有GPU推理速度快很多,但纯CPU也能跑 |
| 硬盘 | 预留20-30GB | 用于存放模型权重文件 |
如果你的电脑配置偏低,可以退而求其次选择 7B 或 14B 参数的小模型。代码生成质量会有所下降,但处理简单的编程任务仍然够用。
总结:AI编程的平民化时代到了
本地部署大模型做AI编程,已经从极客的实验项目变成了实实在在的生产力工具。Ollama 解决了模型部署的门槛问题,千问3 Coder 提供了媲美商业模型的代码生成能力,OpenCode 则补齐了交互体验的最后一环。
三者组合在一起,让每个开发者都能零成本用上AI编程——不用订阅、不用联网、不用担心数据泄露。
如果你是个人开发者或者小团队负责人,强烈建议花半小时试试这套方案。省钱是一方面,更重要的是:你的代码、你的数据、你的AI工具,全都掌握在自己手里。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。