AI编程实践:好的Skill不需要手写,从实战中自动沉淀

通过实践让AI自动沉淀可复用的Skill,而非手写提示词
文章通过K8S集群搭建案例,展示了一套Skill构建方法论:先让AI在真实环境中执行任务,再从结果中提炼Skill文档,然后在纯净环境中验证暴露隐藏问题,最后通过迭代补丁持续完善。核心观点是好的Skill应从实践中自然沉淀,而非手工编写,人的角色从执行者转变为验证者和方向指引者。
引言:让AI自己沉淀经验
在AI编程的实践中,很多人纠结于如何写出一份完美的Skill(技能提示词)。B站UP主IT老齐在其「AI编程300讲」系列中分享了一个核心观点:好的Skill根本不需要手写,它应该从实践过程中自然沉淀出来。
这个理念通过一个真实的K8S集群搭建案例得到了完整验证——从零开始,让AI执行任务、发现问题、修复问题,最终将整个过程凝练为可复用的Skill文档。
实战起点:让AI自主搭建K8S集群
第一版尝试:用简单提示词启动
老齐的需求很明确:在虚拟机环境中搭建一个K8S一主两从的小集群。Kubernetes(简称K8S)是Google开源的容器编排平台,已成为云原生应用部署的事实标准。它通过Master节点(负责调度和管理)和Worker节点(负责运行容器)的架构,实现应用的自动化部署、扩缩容和故障恢复。kubeadm是Kubernetes官方提供的集群引导工具,它将原本需要手动配置证书、etcd数据库、API Server等十余个组件的复杂操作,封装为几条命令即可完成。一主两从是最小化的生产级集群拓扑,一个Master节点负责集群控制面,两个Worker节点提供基本的高可用和负载分担能力。
他给AI的第一版提示词非常简洁:
我现在有一台服务器230,用户名密码是XXX,希望在这台服务器上利用kubeadm来安装master 1.29版本。
AI通过Agent方式,从本地Windows环境连接到远程Linux服务器,使用PowerShell原生脚本不断试错。这里的Agent模式是当前AI编程工具(如Cursor、Windsurf、Claude Code等)的核心能力之一,它允许AI不仅生成代码建议,还能直接执行Shell命令、读写文件、调用API等操作。与传统的Chat模式(仅对话)或Copilot模式(仅补全代码)不同,Agent模式赋予了AI自主规划任务、分步执行、观察结果并调整策略的能力。这意味着AI可以像一个远程运维工程师一样,通过SSH连接服务器、运行安装命令、检查日志、诊断错误并自动修复,形成一个完整的"观察-思考-行动"循环。
整个过程中,AI自动总结中间出现的问题并尝试修正,最终成功完成了master节点的部署。
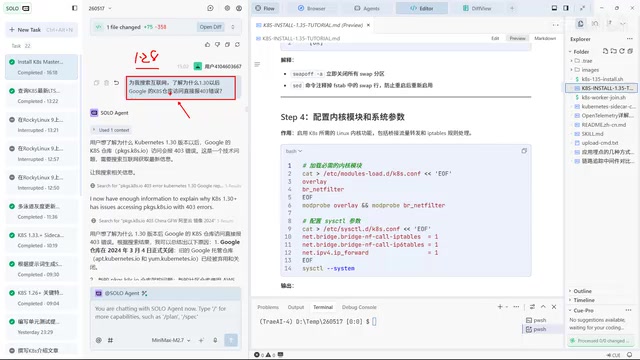
版本踩坑:国内镜像源的困境
然而问题很快暴露——老齐实际需要的是1.35或1.36版本,但AI安装的是1.28这个旧版本。深入调查后发现:
- Google官方仓库对国内IP已屏蔽
- 2024年3月4日后旧仓库关闭,新的AWS仓库同样屏蔽大陆IP
- 华为云镜像已不对外提供
- 阿里云官方文档声称只支持到1.29
这背后是一个影响整个国内K8S社区的行业性问题。2024年是一个重要转折点:Kubernetes社区将包仓库从Google托管迁移到由AWS CloudFront支撑的pkgs.k8s.io,但新仓库同样对大陆IP存在访问限制。与此同时,曾经广泛使用的华为云、中科大等镜像源陆续停止维护或限制访问范围。阿里云虽然持续维护镜像,但其官方文档更新滞后于实际仓库内容,导致用户误以为只支持旧版本。这种"文档说不支持但实际已有"的信息差,恰恰体现了AI辅助探索的价值——AI可以通过实际请求验证仓库中的可用版本,而不受过时文档的误导。
但老齐顺藤摸瓜,发现阿里云实际上已经有1.32-1.35的新版本镜像,只是官方文档未披露。他将这些信息收集后让AI验证,确认了可用的镜像源。
核心方法论:从实践到Skill的自动沉淀
第一步:生成初始Skill
当所有问题解决、master节点成功部署后,老齐说了一句关键的话:
生成安装K8S的Skill。
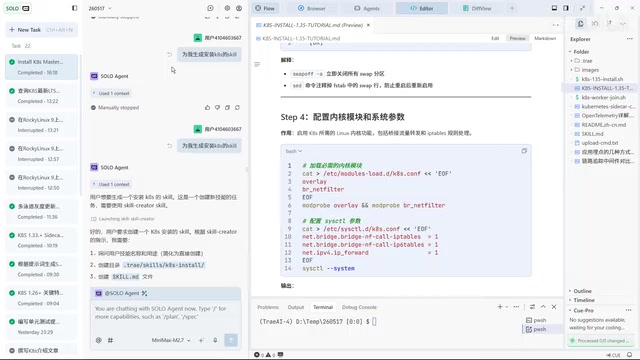
这里的Skill,是AI编程语境中一种结构化的提示词文档,通常以Markdown文件形式存储在项目中(如.cursorrules、CLAUDE.md等),用于指导AI在特定任务场景下的行为模式。它与普通Prompt的区别在于:Prompt是一次性的对话指令,而Skill是持久化的、可复用的经验沉淀。从Prompt Engineering的演进来看,行业经历了从"手工精调单条提示词"到"系统化管理提示词库"的转变。早期用户花大量时间在措辞优化上,而Skill范式的核心洞察是:与其事前设计完美提示词,不如让AI在实践中自动生成和迭代提示词,将隐性经验转化为显性的、可执行的知识资产。
AI将整个安装过程中积累的经验——包括镜像源选择、版本适配、网络配置等——自动整理成了一份结构化的Skill文档,存放在cluster-init目录下。
第二步:验证Skill的可复用性
为了验证Skill是否真正可用,老齐做了一个关键操作:删除已有集群,重置为初始状态,让AI仅凭Skill重新执行一遍。结果证明,1.35版本的master节点顺利安装成功。
随后,他用同样的方式让232服务器以worker身份加入集群,过程异常顺利。这又产生了第二个Skill——worker-join。
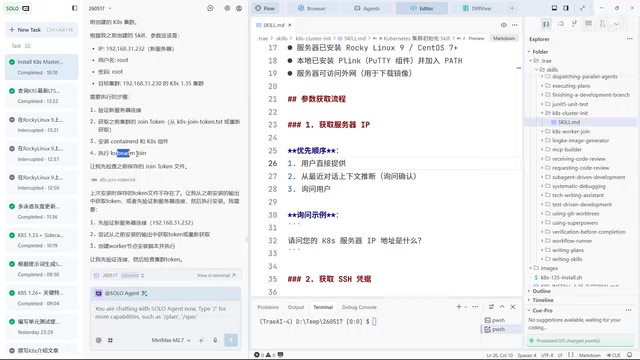
第三步:在纯净环境中暴露隐藏问题
真正的考验来了。老齐新建了一个全新工程,创建三台服务器,只保留两个Skill文件。结果立刻暴露了一个低级但致命的错误:
版本号格式不一致——URL中需要两段式(如1.35),而kubeadm初始化需要三段式(如1.35.5)。之前有上下文时AI能自动推断,但在纯净环境下直接报错。
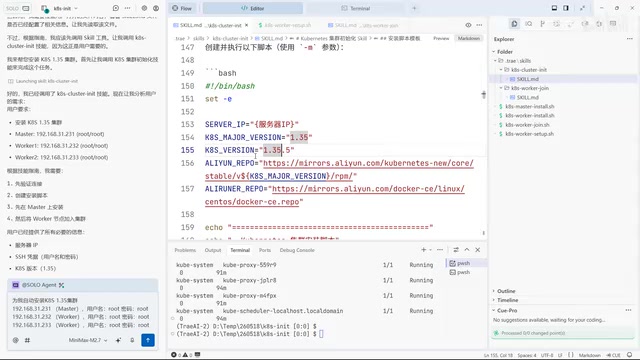
纯净环境验证的思想源自软件工程中的多个经典实践。在持续集成(CI)领域,每次构建都在全新的容器或虚拟机中执行,确保构建结果不依赖开发者本地的特殊配置。在可重复性研究中,实验必须在独立环境中复现才被认可。老齐的做法本质上是将这些原则应用到了Skill验证中:当AI在有上下文的环境中工作时,它可以从对话历史中推断缺失信息(如完整版本号),这种"隐式依赖"在纯净环境中会立即暴露为错误。这与Docker的"在我机器上能跑"问题如出一辙——只有消除所有隐式依赖,才能确保真正的可移植性和可复用性。
更糟糕的是,一旦报错,AI就开始"胡编乱造"。这是大语言模型的一个已知问题——幻觉(Hallucination)。当AI遇到无法解决的错误时,它可能生成看似合理但实际不存在的命令、参数或解决方案。在运维场景中,这种幻觉尤其危险,因为错误的命令可能导致系统配置损坏甚至数据丢失。Skill的防护作用在于:它为AI提供了经过验证的正确路径,减少了AI需要"创造性推理"的空间。当Skill中明确规定了版本号格式、镜像源地址、参数配置等关键信息时,AI只需按照既定路径执行,大幅降低了幻觉发生的概率。这也解释了为什么Skill的精确性如此重要——每一个模糊之处都可能成为幻觉的入口。
这说明Skill必须经过纯净环境的验证才算合格。
第四步:持续打补丁完善Skill
老齐的修复策略很有启发性:
- 拆分版本号参数:将单一的版本号拆分为
major_version和k8s_version两个变量,各自用于不同场景 - 补充IP获取规则:在Skill中声明"可以要求用户指定或自动查询环境信息,无法确认时必须询问用户"
- 沉淀运行时经验:比如主机名默认为localhost会导致问题、P-Link参数设置错误等,都在裸验证中被发现并补充进Skill
老齐使用了一个精妙的提示词:
有什么可以在Skill中补充的经验吗?
AI自动将验证过程中解决的问题整理成优先级表格,老齐再将高优先级和中优先级的项目补充到Skill中。
方法论总结:Skill的正确构建流程
整个过程揭示了一套清晰的Skill构建方法论:
- 先让AI做事:给出目标,让AI在真实环境中执行,不要预设太多
- 从结果中提炼:任务完成后,让AI将过程总结为Skill
- 纯净环境验证:在没有上下文的全新环境中测试Skill
- 发现问题就打补丁:不手动改Skill,而是描述问题让AI修复并沉淀
- 持续迭代:每次使用都可能发现新问题,不断完善
这套流程与软件工程中的测试驱动开发(TDD)有异曲同工之妙:先写测试(纯净环境验证)、再写实现(Skill内容)、发现失败就修复,通过红-绿-重构的循环不断提升质量。不同之处在于,这里的"测试"是在真实环境中的端到端验证,而"实现"是由AI自动生成和修正的。
最终效果是:只需告诉AI哪台服务器是主节点、哪些是工作节点,一回车就能自动完成所有版本调整和适配,实现真正的一键部署。
启示:AI时代的知识管理新范式
这个案例的价值不仅在于K8S部署本身,更在于它展示了一种AI时代的知识沉淀范式:
- 知识不再是静态文档,而是可执行、可验证的Skill
- 经验积累不靠人工总结,而是从实践中自动提炼
- Skill的质量通过反复验证和补丁迭代来保证
- 人的角色从"执行者"变成了"验证者"和"方向指引者"
这种范式的深层意义在于,它重新定义了"专家知识"的载体。传统上,运维专家的价值体现在脑中积累的经验——哪些坑踩过、哪些配置容易出错、哪些版本组合有兼容性问题。这些隐性知识难以传承,专家离职往往意味着知识流失。而Skill范式将这些隐性知识显性化为可版本管理、可共享、可持续迭代的文档资产。更重要的是,这些知识资产是"活"的——它们可以被AI直接执行和验证,而不仅仅是供人阅读的参考文档。
正如老齐所说:"通过沉淀Skill,你会让你的AI跑得越来越快、越来越好。"这或许就是AI编程时代最重要的个人竞争力——不是写代码的能力,而是让AI为你积累和复用经验的能力。
核心要点
- 好的Skill不需要手写,应从AI实际执行任务的过程中自然沉淀而来
- Skill必须在纯净环境中验证才算合格,有上下文时能跑通不代表真正可复用
- 通过"发现问题→让AI修复→补充到Skill"的循环迭代,持续完善Skill质量
- 版本号格式、环境变量获取等细节问题往往在纯净验证时才会暴露
- 人的角色从执行者转变为验证者和方向指引者,核心竞争力在于让AI积累和复用经验
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。