AI编程Token消耗太快?5个实用策略帮你省下80%费用

解析AI编程工具Token消耗快的原因及节省策略
AI编程工具Token消耗极快,根本原因在于大模型的无状态特性——每轮对话需携带全部历史上下文,且代码场景文本量大、修改频繁。核心节省策略包括:一次性描述清楚需求、保持干净上下文(3-4轮拉锯后清空重来)、先规划后编码,以及通过减少口语化表达、善用图片、精确指定文件路径来优化输入输出Token消耗。
为什么AI编程如此烧Token?
很多使用AI编程工具(如Cursor、Claude等)的开发者都有同感:10天就能花光一个月的额度。Token消耗速度远超预期,这背后的原因与大模型的工作机制密切相关。
大模型的无状态本质
大模型本质上是无状态的——它不记得之前说过什么。这一特性源于Transformer架构的设计原理:每次推理时,模型只能看到当前输入的Token序列,没有任何持久化的"记忆"存储。为了维持多轮对话的连贯性,工程上的解决方案是将历史对话拼接成一个完整的文本序列,整体送入模型。这个序列的最大长度就是"上下文窗口"(Context Window),目前主流模型从32K到200K Token不等。
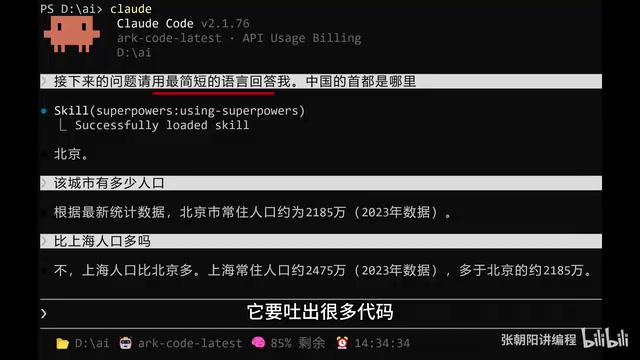
举个简单例子:
- 第一问:"中国首都是哪里?" → "北京"
- 第二问:"该城市多少人口?" → "2185万"
- 第三问:"比上海人口多吗?" → "不"
看似简单的三问三答,实际上第二问发出时,系统会把第一轮的问题和答案一并提交给大模型(否则它不知道"该城市"指的是北京)。第三问发出时,前两轮的完整对话都会被打包发送。
这意味着:在一个对话窗口里,提问轮次越多,后面每一轮消耗的Token就越大。 上下文窗口越大,能承载的对话历史越长,但计算成本也随之线性甚至超线性增长——这正是Token消耗快速膨胀的根本原因。
当界面显示"上下文还剩余85%"时,它指的不是整个对话累计用了15%,而是你最后一次提问就消耗了15%的上下文窗口。
编程场景为何特别费Token
Token是大模型处理文本的基本单位,既不等于字符,也不等于单词。英文中,一个Token大约对应4个字符或0.75个单词;中文通常1-2个汉字对应1个Token。代码场景下,变量名、括号、缩进空格都会被单独计为Token——这也是代码比普通文本更"费Token"的原因之一。
在编程场景下,Token消耗问题更加严峻:
- 整个文件甚至整个项目的代码需要提交给大模型
- 大模型修改后要输出大量代码
- 后续每轮问答都会把之前的代码"卷"进上下文
这就是Coding Plan如此吃Token的根本原因——代码量大、修改频繁、上下文膨胀迅速。
减少Token消耗的核心策略
策略一:一次性把需求描述清楚
避免这种低效模式:提一个模糊需求 → AI写好代码 → 发现要加功能 → AI重新扫描整体代码修改 → 又要加功能 → 反复循环。
每一次反复,AI都要重新处理之前所有的代码和对话历史。正确做法是在开始前就把需求想清楚、写完整,一次性交代所有要求。
策略二:保持干净的上下文环境
当AI写的代码出错,你纠正它,它改完还不对,你再纠正——这种拉锯超过三四轮后,上下文中充斥着大量错误代码。这不仅浪费Token,还会让大模型产生混乱,因为它本质上是根据上下文来推测输出内容的。
建议:拉锯超过3-4轮后,直接清空上下文从头再来。 根据上次AI容易犯的错误,重新组织更精确的需求描述。

对于不相关的任务,更应该放到不同的对话中完成。一件事做完执行clear,再开始第二件事——第二件事完全不需要知道第一件事的背景。
策略三:先规划后动手
在项目开发前,先让AI做规划,把规划逐条对齐确认,然后再让它开始写代码。明确告诉AI:
- 如果有疑义必须停下来询问,不要带着猜测写代码
- 没说要改的地方禁止修改
否则这边改对了,那边又改错了,又需要反复拉锯,白白消耗Token。
降低输入输出Token成本的技巧
理解Token定价差异
任何大模型的输出Token都比输入Token贵很多。以某模型为例:输入每1000个Token 0.0032元,输出每1000个Token 0.016元——输出价格是输入的5倍。输出Token之所以更贵,是因为生成过程需要逐Token自回归推理,每生成一个Token都需要完整的前向计算,其计算量远高于一次性编码输入序列的过程。因此控制输出量尤为重要。
输入端优化方法
- 避免口语化表达:使用专业术语,言简意赅
- 善用图片传达信息:流程图、代码结构图、示例截图,都比纯文字描述更简洁,且更便于大模型理解
- 精确指定文件路径:如果你知道是哪个文件有问题,明确告诉大模型具体路径,不要让它扫描整个代码库
输出端优化方法
通过规则约束AI,避免输出无价值信息:
- 禁止说"好的,我明白了
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。