AI编程一体机vs在线大模型:48万年费能换4套本地方案?
OnePanel AI编程一体机通过本地化部署,大幅降低团队AI编程成本并解决安全合规问题。
针对在线大模型API在AI编程中费用高、延迟大、代码安全风险和合规限制等痛点,OnePanel推出AI编程一体机,配备双GB10芯片、256GB统一内存和千问3.6 27B模型,支持8并发稳定响应。20人团队年API费用约48万元,而一体机定价9.9万元,约两个半月即可回本,将持续可变成本转化为一次性技术资产投入。
当越来越多的开发团队将AI编程融入日常工作流,Token费用正在成为一笔不可忽视的持续性开支。一个20人的开发团队,每年在线大模型API调用费用可能高达48万元。而现在,一种将AI编程能力本地化部署的一体机方案,正试图从根本上改变这一成本结构。
在线大模型用于AI编程的四大痛点
对于深度使用AI编程的团队来说,调用在线大模型API面临的问题远不止费用一项:
第一,Token按量付费,成本持续攀升。 Token是大语言模型处理文本的基本单位,通常一个英文单词约等于1-2个Token,一个中文汉字约等于1-2个Token。在API调用中,费用分为输入Token(发送给模型的提示词、代码上下文等)和输出Token(模型生成的回复)两部分计费,且输出Token单价通常是输入Token的4-6倍。AI编程场景中,每次代码补全、Debug分析都需要将当前文件、相关上下文一并发送,这正是Token消耗量远超普通对话场景的根本原因。随着AI参与开发的比重越来越高,每人每天消耗1000万到3000万Token已经是很多团队的真实现状,这笔费用只会越来越高。
第二,网络延迟影响开发体验。 公网环境下网速不稳定,代码补全等待时间过长,直接打断开发者的思路和工作流。
第三,代码安全风险。 将核心业务代码发送给第三方大模型,数据泄露的风险始终是悬在头上的一把剑。
第四,合规硬性要求。 金融、政企等行业的代码根本不允许出内网,在线大模型方案直接被排除在外。
OnePanel AI编程一体机:本地化部署方案详解
针对上述痛点,OnePanel推出了AI编程一体机,将AI编程能力完整地部署在本地内网环境中。
硬件配置与模型性能
这款一体机配备两颗英伟达GB10芯片,拥有256GB统一内存,内置千问3.6 27B大模型,专注于AI编程场景。
GB10是英伟达基于Blackwell架构的边缘/桌面级AI芯片,专为本地推理场景设计,集成了GPU与CPU的统一内存架构(Unified Memory)。统一内存的核心优势在于GPU和CPU共享同一块物理内存池,避免了传统架构中数据在显存与内存之间频繁搬运的瓶颈,使得大参数量模型能够以更低延迟完成推理。256GB统一内存的配置,意味着27B参数模型在FP16精度下(约54GB)有充裕的内存余量用于存储KV Cache,从而支撑多用户并发请求而不产生显著的性能衰减。
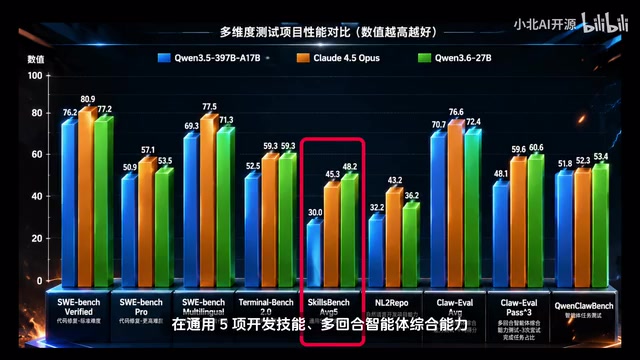
从实测对比数据来看,千问3.6在多个维度上的表现值得关注:在通用编程能力、开发技能、多回合智能体增强能力、智能体任务测试等维度上,多方面领先千问3.5,接近甚至在部分指标上高于Claude 4.5 Opus的水平。
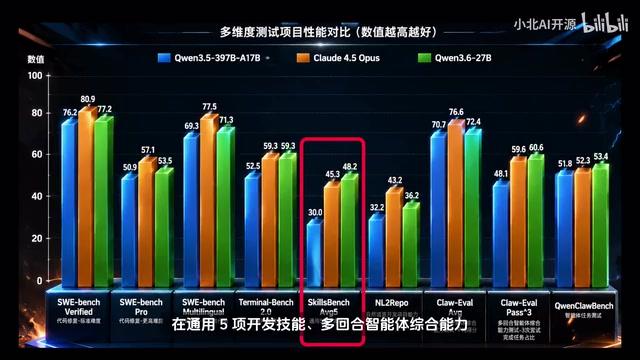
千问(Qwen)系列是阿里云通义实验室开发的开源大语言模型家族,27B参数规模是当前本地部署的"甜蜜点"——相比7B/14B模型有显著的能力提升,相比70B+模型又对硬件要求更为友好。千问3.6本身支持256K超长上下文,这对AI编程场景意义重大:主流前端框架(如Vue、React)的大型项目往往包含数十个相互引用的文件,短上下文模型只能处理局部代码片段,容易产生与整体架构不一致的建议;而256K上下文理论上可容纳约20万行代码,能够让模型完整理解VUE、React、Redis等项目的全量代码和架构,而不是只能处理片段。
并发性能实测数据
在实际多用户场景下,不论是FP8精度还是BF16精度,8个并发用户同时使用时,实测秒级响应,整体吞吐量分别达到51 Token/秒和65 Token/秒,能够稳定支撑多用户同时流畅对话,满足团队级别的使用需求。
FP8(8位浮点)和BF16(16位脑浮点)是大模型推理中常用的两种数值精度格式。BF16是目前AI训练和推理的主流精度,在保持较高数值范围的同时将存储需求减半(相比FP32);FP8则进一步将存储压缩至BF16的一半,可显著提升推理吞吐量,但需要硬件原生支持(Blackwell架构对FP8有专门优化)。实测中两种精度各有适用场景,在实际部署时可根据团队对吞吐量与精度的不同侧重灵活选择。
团队管理与DevOps工具链集成
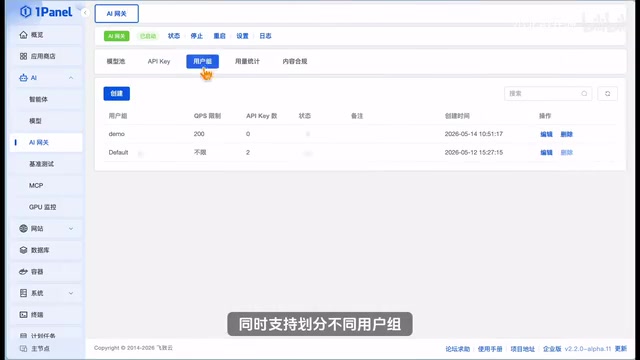
一体机内置OnePanel管理面板,提供了完善的团队管理能力,其核心是AI网关(AI Gateway)——这是在传统API网关基础上针对大模型调用场景扩展的中间件,核心功能包括统一的API Key管理与鉴权、按用户/团队的QPS限流与配额控制、请求日志审计等。在企业级AI编程场景中,AI网关解决了"谁在用、用了多少、用在哪里"的可见性问题,是将个人工具升级为团队基础设施的关键组件:
- 统一管控: 用户、大模型全线由AI网关统一管控
- 灵活分配: 团队成员通过API网关分配的API Key调用一体机
- 精细化配置: 支持划分不同用户组,可根据各小组开发需求单独配置每组的QPS和访问限额
此外,OnePanel的应用商店内置了项目管理、代码托管、制品库、CI/CD等全套DevOps工具,无需额外部署配置。这代表了"AI-Native DevOps"的演进方向——AI不再只是辅助写代码的工具,而是嵌入整个软件交付流水线的协作者。开发者无需切换工具,AI生成代码后可直接通过工具链完成后续操作,实现AI编程加DevOps一体化闭环。
成本对比:在线大模型vs本地一体机
这套方案最具说服力的部分在于成本测算。以一个20人开发团队为例,按日常开发场景计算:
- 每天工作8小时,AI参与开发时长4-6小时
- 用于生成代码、Debug、写文档等场景
- 每人每天消耗1000万到3000万Token

按照输入占比90%-95%、输出占比5%-10%的比例,参考阿里云公开定价(输入每百万Token 3元,输出每百万Token 18元),具体测算如下:
| 日均Token消耗 | 单人单日费用 | 20人月度费用 |
|---|---|---|
| 1000万 | 30-75元 | 约1.35万 |
| 2000万 | 约61.5元 | 约2.71万 |
| 3000万 | 约92.25元 | 约4.06万 |

按20人团队每月Token花费4万来测算,一年在线大模型开销接近48万元。而OnePanel AI编程一体机目前定价9.9万元,粗略测算两个半月即可摊回成本。同样的48万预算,可以购买4套AI一体机,还有剩余。
从可变成本到技术资产的转变
这个方案的核心逻辑其实很清晰:将AI能力从持续的可变成本,转化为一次性投入的技术资产。
对于中大型开发团队而言,尤其是对数据安全和合规有硬性要求的金融、政企客户,本地化AI编程方案的价值不仅仅体现在成本节省上,更在于:
- 代码全程内网闭环,不外泄、不出网,安全自主可控
- 算力稳定可预期,不受公网波动影响
- 一次投入长期使用,边际成本趋近于零
- 团队管理精细化,支持多用户组、多权限的灵活配置
当然,本地化方案也有其局限性——模型更新迭代不如在线服务及时,单机算力上限固定,且需要一定的运维投入。但对于AI编程这个相对聚焦的场景来说,当前27B参数量级的模型已经能够覆盖大部分日常开发需求。
在AI编程从"尝鲜"走向"标配"的过程中,如何平衡性能、成本与安全,是每个技术团队都需要认真思考的问题。本地化AI编程一体机提供了一个务实的选项,值得有相关需求的团队深入评估。
核心要点
- 20人开发团队每年在线大模型API调用费用可达48万元,而同等预算可购买4套本地AI编程一体机
- OnePanel AI编程一体机配备双GB10芯片和256GB统一内存,内置千问3.6 27B模型,8并发下吞吐量达51-65 Token/秒
- 一体机内置AI网关、DevOps工具链,支持多用户组精细化管理,实现AI编程加DevOps一体化闭环
- 本地化部署解决了代码安全、网络延迟、合规要求等在线大模型的核心痛点,将可变成本转化为一次性技术资产投入
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。