AI大模型学习路线:从零基础到项目实战的系统学习路径

随着AI大模型技术的持续火爆,越来越多的人希望入门这一领域。然而面对海量碎片化的学习资源,初学者往往陷入"看了很多教程却依然不会做项目"的困境。B站上一套号称748集的AI大模型全套教程引发了广泛关注,其课程设计思路和知识体系架构,恰好为我们提供了一个审视"如何系统学习AI大模型开发"的切入点。
当前AI大模型学习资源存在哪些痛点
该课程作者在制作前花了一个月时间刷遍各大平台的AI大模型开发教程,总结出了当前学习资源的几个普遍问题:内容不够系统、不够完整,大多只讲解单个工具的基础操作,关键的工程化落地流程一笔带过。
这个观察相当精准。目前市面上的AI大模型教程大致分为三类:一是API调用入门级内容,教你如何调用ChatGPT或国产大模型接口;二是某个具体框架(如LangChain)的操作演示;三是偏学术的论文解读。但将这些知识串联成完整开发能力的系统性内容确实稀缺。
尤其是新手最头疼的模型微调、私有化部署、Agent开发等核心环节,很少有教程能讲透彻。这也是为什么很多人学了一堆零散知识,却无法独立完成一个企业级项目。
三段式学习路径:从基础认知到企业实战
这套课程采用了"基础认知→能力进阶→企业实战"的三段式结构,这个设计思路值得所有AI学习者参考。
基础认知篇:打牢大模型学习地基

基础阶段涵盖了几个关键模块:
- 大模型基础概念:理解什么是大语言模型、Token、上下文窗口等核心概念
Token是大语言模型处理文本的基本单位,但它既不等同于单词也不等同于字符。英文中一个Token大约对应4个字符或0.75个单词,中文中一个汉字通常被编码为1-2个Token。模型使用分词器(Tokenizer)将输入文本切分为Token序列,常见的分词算法包括BPE(Byte Pair Encoding)和SentencePiece。上下文窗口(Context Window)则指模型单次能处理的最大Token数量,它直接决定了模型能"看到"多少信息。GPT-3.5的上下文窗口为4K/16K Token,GPT-4 Turbo扩展到128K,Claude 3支持200K。上下文窗口的大小直接影响RAG系统的设计策略和长文档处理能力。
- Transformer底层架构:这是所有大模型的技术根基,理解注意力机制、编码器-解码器结构对后续学习至关重要
Transformer是Google在2017年论文《Attention Is All You Need》中提出的深度学习架构,彻底改变了自然语言处理领域的技术范式。其核心创新在于自注意力机制(Self-Attention),允许模型在处理序列数据时同时关注输入的所有位置,而非像传统RNN那样逐步处理。这种并行化设计不仅大幅提升了训练效率,还使模型能够捕捉长距离依赖关系。当前所有主流大模型——GPT系列、LLaMA、Claude、文心一言等——都基于Transformer架构的变体构建。理解多头注意力、位置编码、前馈网络等组件的工作原理,是深入大模型开发的必要前提。
- 提示词工程(Prompt Engineering):包括零样本提示、少样本提示、思维链(Chain of Thought)等关键技法
很多初学者急于上手写代码,跳过了对Transformer架构的理解。但实际上,只有理解了底层原理,才能在遇到问题时知道如何调优,而不是盲目试错。
能力进阶篇:掌握RAG、Agent等核心技术栈

进阶阶段是整个学习路径中最关键的部分,涉及的技术栈相当全面:
RAG(检索增强生成) 是当前企业应用中最主流的技术方案。它通过将外部知识库与大模型结合,解决了模型"幻觉"和知识时效性问题。掌握RAG的完整链路——从文档解析、向量化、检索到生成——是大模型开发者的必备技能。
RAG(Retrieval-Augmented Generation)由Meta AI在2020年首次提出,其核心思想是在大模型生成回答之前,先从外部知识库中检索相关信息作为上下文输入。完整的RAG工程链路包括:文档加载与分块(Chunking)、文本向量化(通过Embedding模型将文本转为高维向量)、向量存储与索引(使用Milvus、Pinecone、FAISS等向量数据库)、语义检索(基于余弦相似度或ANN算法找到最相关的文档片段)、以及最终的提示词组装与生成。RAG之所以成为企业级应用的首选方案,是因为它无需重新训练模型即可注入领域知识,同时通过引用来源提升了回答的可追溯性和可信度。
Agent智能体开发 是近两年最火热的方向。课程涵盖了LangGraph、LangChain等主流框架的集成实践,这些工具能帮助开发者构建具备自主决策、工具调用能力的AI智能体。
AI Agent(智能体)的概念源自人工智能的经典理论,但在大模型时代获得了全新的实现路径。现代AI Agent的核心能力包括:感知环境、自主规划、工具调用和记忆管理。LangChain是最早将大模型与外部工具链接的开发框架,而LangGraph则在此基础上引入了有向图的工作流编排能力,支持更复杂的多步骤推理和条件分支。2024年以来,Agent框架生态快速扩展,AutoGPT、CrewAI、MetaGPT等项目层出不穷。在企业场景中,Agent通常需要具备Function Calling能力(即模型能够识别何时需要调用外部API或工具),并通过ReAct(Reasoning + Acting)模式实现推理与行动的交替循环。
模型微调与部署 则是从"调用者"进阶为"开发者"的分水岭。LoRA微调、全量微调、本地部署、高并发推理优化等内容,直接决定了你能否将模型真正落地到生产环境。
LoRA(Low-Rank Adaptation)是微软在2021年提出的参数高效微调方法,已成为当前最主流的大模型微调技术。传统全量微调需要更新模型的所有参数,对于动辄数十亿参数的大模型来说,计算成本和显存需求极高。LoRA的核心思想是冻结预训练模型的原始权重,仅在特定层注入低秩分解矩阵进行训练。例如,一个4096×4096的权重矩阵,LoRA可能只训练两个4096×16的小矩阵,将可训练参数量降低数百倍。这使得在单张消费级GPU上微调7B甚至13B参数的模型成为可能。其变体QLoRA进一步结合了4-bit量化技术,将显存需求压缩到更低水平。
企业实战篇:用项目检验学习成果
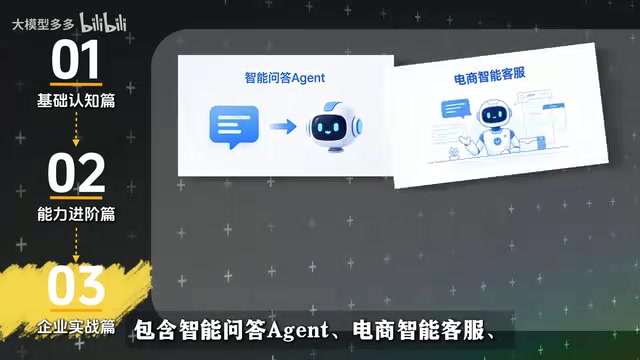
实战项目的选择颇具代表性:
- 智能问答Agent:最基础的RAG应用场景
- 电商智能客服:涉及多轮对话、意图识别、业务流程编排
- 企业级AI智能体:综合性最强,需要整合多种技术能力
- 智能助教:教育场景的垂直应用
这些项目覆盖了当前AI大模型最主流的商业化落地方向,学完后能形成可复用的项目经验。值得注意的是,企业级项目与个人Demo的核心差异在于工程化要求:需要考虑系统的可扩展性、高并发处理能力、错误容错机制、以及持续迭代的数据飞轮设计。例如电商智能客服项目,不仅需要实现基本的问答功能,还需要处理用户意图的多轮澄清、与订单系统和库存系统的API对接、以及对话质量的自动化评估与监控。
理性看待748集课程:三点学习建议
尽管课程体系设计得相当完整,但我们也需要理性看待几个问题:
第一,748集的体量意味着巨大的时间投入。 按每集10-15分钟计算,总时长可能超过100小时。对于在职学习者来说,需要合理规划学习节奏,建议按模块分阶段推进,而非试图一口气看完。
第二,AI领域技术迭代极快。 大模型领域几乎每个月都有新的框架和工具出现。以2024年为例,OpenAI发布了GPT-4o和结构化输出能力,Anthropic推出了Claude 3.5系列,开源社区的LLaMA 3、Qwen 2、DeepSeek等模型持续刷新性能基准。学习者需要在掌握基础原理的同时,保持对新技术的敏感度。原理层面的知识(如Transformer架构、注意力机制、训练范式)具有较长的保质期,而具体框架和工具的API可能随时变化。
第三,"看完"不等于"学会"。 大模型开发是一门实践性极强的技能,光看视频远远不够。建议每学完一个模块就动手实操,遇到报错和问题才是真正学习的开始。可以从搭建本地开发环境开始,使用Ollama或vLLM部署开源模型,然后逐步构建自己的RAG系统和Agent应用。GitHub上的开源项目和Hugging Face上的模型资源都是极好的实践素材。
给AI大模型初学者的路径规划
无论是否选择这套课程,以下学习路径都值得参考:
- 先建立全局认知:花1-2周时间了解大模型技术全景图,明确自己的学习目标。建议阅读一些综述性文章或观看概览性讲座,理解大模型生态中的各个角色——基础模型提供商、中间件开发者、应用层开发者——以及自己希望在哪个层面发力。
- 夯实Python基础:如果编程基础薄弱,先补齐Python和基本的数据处理能力。重点掌握异步编程(asyncio)、HTTP请求处理、JSON数据操作、以及基本的向量运算(NumPy),这些是大模型开发中高频使用的技能。
- 从API调用开始:先学会调用主流大模型API,快速获得成就感。OpenAI的API文档设计清晰,国内的通义千问、智谱AI等平台也提供了免费额度,适合练手。
- 深入RAG和Agent:这是当前就业市场需求最大的两个方向。据多个招聘平台数据显示,2024年AI应用开发岗位中,超过70%要求具备RAG或Agent开发经验。
- 实战驱动学习:尽早开始做项目,在项目中发现知识盲区再回头补课
AI大模型开发正处于快速发展期,系统化的学习路径比碎片化的知识积累更有价值。关键不在于看了多少集教程,而在于你能否将所学转化为可落地的开发能力。
相关推荐
Claude Code实战指南:安装配置到商业级项目落地全流程
详解Claude Code + Opus模型组合的完整实战流程,包括CC Switch安装配置、需求工程化编写方法,以及4小时完成复杂支付系统二次开发的真实案例,附模型选型与成本对比分析。
Claude Code自动生成视频章节进度条动画教程
利用Claude Code的Skill机制和Remotion库,只需导入字幕文件即可自动生成视频章节进度条动画。支持六种内置风格和自定义贴纸,告别繁琐的手动剪辑流程,让视频制作效率大幅提升。
免费无限制使用Claude Code的方法:零成本全模态AI方案
通过Claude Code搭配Agnes AI免费模型和CC Switch开源工具,实现零成本无限制使用AI编程、生图、生视频的完整配置教程,含实测效果对比。