AI加持Frida逆向:高效抓包一把梭哈

AI+Frida实现高效移动应用抓包与协议逆向
文章介绍了传统抓包工具面临SSL Pinning等反检测困境,提出使用Frida动态插桩+AI辅助的新方案。通过JADX反编译获取源码,让AI分析加密逻辑并自动生成Hook脚本,在加密前直接拦截明文数据,四步完成协议逆向。
传统抓包的困境
在移动应用逆向工程领域,抓包一直是分析网络协议的核心手段。然而,传统的抓包方案正面临越来越严峻的挑战。
提到抓包,大多数人第一反应是Charles或Fiddler这类代理层抓包工具。这类工具本质上是HTTP/HTTPS代理服务器,通过在客户端和服务器之间插入一个中间人(Man-in-the-Middle)来截获流量。对于HTTPS流量,需要在设备上安装自签名CA证书,让代理能够解密TLS加密的内容。但现实是,现在的APP对代理检测越来越严格,代理层抓包几乎秒被识别。现代APP普遍采用SSL Pinning(证书锁定)技术,即在应用内部硬编码服务器证书的指纹,拒绝任何非预期证书的TLS连接。此外,APP还会检测系统代理设置、VPN接口状态,甚至通过NetworkInfo API判断当前网络是否经过代理转发,从而在检测到抓包行为时拒绝发送请求或返回虚假数据。
进阶一些的方案如APPF(应用层抓包框架),虽然功能强大,但配置繁琐、侵入性强,并非万能解药。
那么,如何实现真正高效的抓包?答案是:Frida + AI。

为什么选择Frida
Frida的核心优势
Frida是一款动态插桩工具,核心理念是直接在运行时注入代码,Hook目标函数,从底层拦截数据流。其底层实现基于动态二进制插桩(Dynamic Binary Instrumentation, DBI)技术。在Android平台上,Frida通过ptrace系统调用附加到目标进程,然后注入一个共享库(frida-agent),该库内嵌了V8 JavaScript引擎。注入完成后,用户编写的JS脚本在目标进程的地址空间内执行,可以直接访问进程内存、替换函数实现、读取寄存器值。对于Java层的Hook,Frida利用Android Runtime(ART)提供的内部接口,修改方法的入口点,将调用重定向到用户定义的回调函数。
相比传统抓包工具只能在网络层截获数据,Frida可以深入到应用的任何层级:
- 绕过加密:在数据加密之前或解密之后直接拦截明文
- 万物皆可Hook:无论是自定义协议还是加密心跳包,都能在底层捕获
- 灵活性极高:通过JavaScript脚本实现任意逻辑
这种在进程内部运行的方式,使得Frida能够在数据到达网络层之前就进行拦截,完全不依赖网络代理,从根本上规避了代理检测的问题。
在AI的加持下,Frida的使用门槛大幅降低。过去需要深入理解smali代码和Java反编译才能编写的Hook脚本,现在可以让AI根据反编译结果自动生成。
应对反检测:魔改版Frida
当然,Frida也有其软肋——大厂的反Frida检测。大厂APP通常会部署多层Frida检测机制:第一层是扫描进程的/proc/self/maps文件,查找frida-agent.so等特征库名;第二层是检测默认的Frida通信端口(27042)是否开放;第三层是扫描内存中的Frida特征字符串如"LIBFRIDA";第四层是通过inline hook检测,验证关键函数的前几个字节是否被修改为跳转指令。
遇到这种情况,有两个推荐的魔改项目:
- Rashda:强力过检测能力
- Chunga:同样具备极强的反检测绕过能力
这两个项目通过重命名共享库、随机化通信端口、抹除内存特征字符串、使用更隐蔽的hook方式(如修改虚函数表而非inline patch)等手段来规避检测。其过检测能力非常夸张,能够应对大部分主流APP的Frida检测机制。
AI辅助逆向实战流程
第一步:信息搜集与加固分析
以某APP为例,首先需要分析目标应用使用了什么加固产品。APP加固(也称加壳)是一种代码保护技术,主流方案包括360加固、梆梆加固、爱加密等。加固的基本原理是将原始DEX文件(Dalvik可执行文件,包含应用的Java/Kotlin字节码)进行加密或变换,运行时由壳程序(loader)在内存中动态解密并加载。这意味着直接对APK进行反编译只能看到壳代码,无法获取真实业务逻辑。
通过专用工具扫描后,如果显示"未加固",那么解剖起来相对容易。如果检测到加固(如360加固),则需要先进行脱壳处理。脱壳的核心思路是在DEX被解密加载到内存后,从内存中dump出完整的DEX文件。常用的脱壳工具包括Frida-DEXDump、FART(基于ART修改的主动调用脱壳机)等,它们利用ART虚拟机加载类的时机点来获取解密后的代码。
第二步:反编译获取源码
使用JADX对APK进行反编译,将Java源代码完整还原出来。JADX是目前最主流的Android反编译工具之一,它能够将DEX字节码直接转换为可读的Java源代码,而非中间的smali汇编语言。相比早期的dex2jar+JD-GUI工作流,JADX提供了更好的代码还原质量和一体化的GUI界面。
JADX支持反混淆映射、交叉引用分析、字符串搜索等功能,对于逆向分析网络请求逻辑尤为重要——分析者可以通过搜索URL字符串、HTTP方法调用等快速定位网络层代码,进而追踪参数的加密和签名流程。反编译后的内容会以JAR压缩文件的形式导出,包含了应用的核心业务逻辑代码。
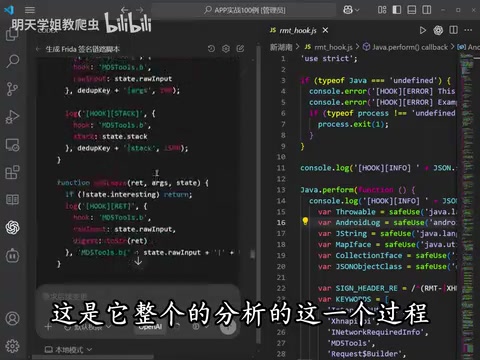
第三步:AI生成Hook脚本
这是整个流程中最关键的一步——将反编译得到的源码交给AI,让它分析加密逻辑并自动生成Frida Hook脚本。
AI(如GPT-4、Claude等大语言模型)在分析反编译代码时,能够识别常见的加密模式,例如AES/RSA加密调用、HMAC签名计算、自定义编码算法等。AI会根据函数签名、参数类型和调用链,判断哪些函数是最佳的Hook点——通常选择加密函数的入参(获取明文)和出参(获取密文),以及网络请求构造函数(获取完整的请求参数)。
AI会完成以下工作:
- 分析代码中的加密函数和网络请求逻辑
- 识别关键的Hook点(如加密前的明文参数)
- 生成完整的JavaScript Hook脚本
- 说明脚本能够提取哪些信息
生成的Frida脚本通常使用Java.perform()包裹,通过Java.use()获取目标类的引用,再用implementation属性替换目标方法的实现,在新实现中打印参数后调用原始方法,实现透明的数据拦截。
第四步:执行与验证
将AI生成的JS脚本通过命令行注入目标进程。具体操作通常是使用frida -U -f com.target.app -l hook.js命令,其中-U表示连接USB设备,-f指定以spawn模式启动目标应用(确保从应用启动之初就开始Hook),-l加载指定的JS脚本文件。
在实际测试中,脚本启动后,那些原本加密的心跳包和参数报文全部现出原形——以明文形式被完整捕获。控制台会实时输出每次目标函数被调用时的参数值和返回值,包括请求URL、请求体明文、签名计算的输入输出等关键信息。
核心方法论:明文溯源加密逻辑
这套AI+Frida的工作流,其精髓在于:
通过明文参数反向溯源加密逻辑,这才是协议级逆向的核心思路。
传统方式是先理解加密算法再尝试解密,这往往需要逆向分析者具备密码学知识,能够识别算法类型、找到密钥、理解填充模式和分组模式等细节,耗时且容易出错。而Frida的方式是直接在加密发生之前截获数据,完全绕过了"破解加密"这个难题。这种思路的本质是将问题从"密码分析"降维为"代码定位"——只要找到加密函数的调用位置,就能同时获得明文和密文,甚至能直接提取加密密钥。
AI的加入则进一步降低了编写Hook脚本的技术门槛,让整个流程变得高效且可复制。即使面对经过ProGuard或R8混淆的代码(变量名和方法名被替换为无意义的短字符),AI也能通过分析代码结构、API调用模式和数据流向来推断函数的实际用途。
总结
相比复杂的MCP配置或传统抓包方案,Frida命令行直接注入的方式确实更加高效直接。结合AI自动生成Hook脚本的能力,即使是加密协议也能快速突破。整个流程可以概括为:
- 工具扫描加固状态
- JADX反编译获取源码
- AI分析生成Hook脚本
- Frida命令行注入执行
四步完成从加密到明文的全链路突破,这就是AI时代逆向工程的新范式。这套方法论的核心价值在于将原本需要数天甚至数周的逆向分析工作,压缩到数小时内完成,同时将技术门槛从"资深安全研究员"降低到"具备基础开发能力的工程师",极大地提升了协议分析的效率和可达性。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。