AI进步需要更细致的审视:超越炒作与恐慌的理性框架
引言:超越AI炒作与恐慌的理性思考
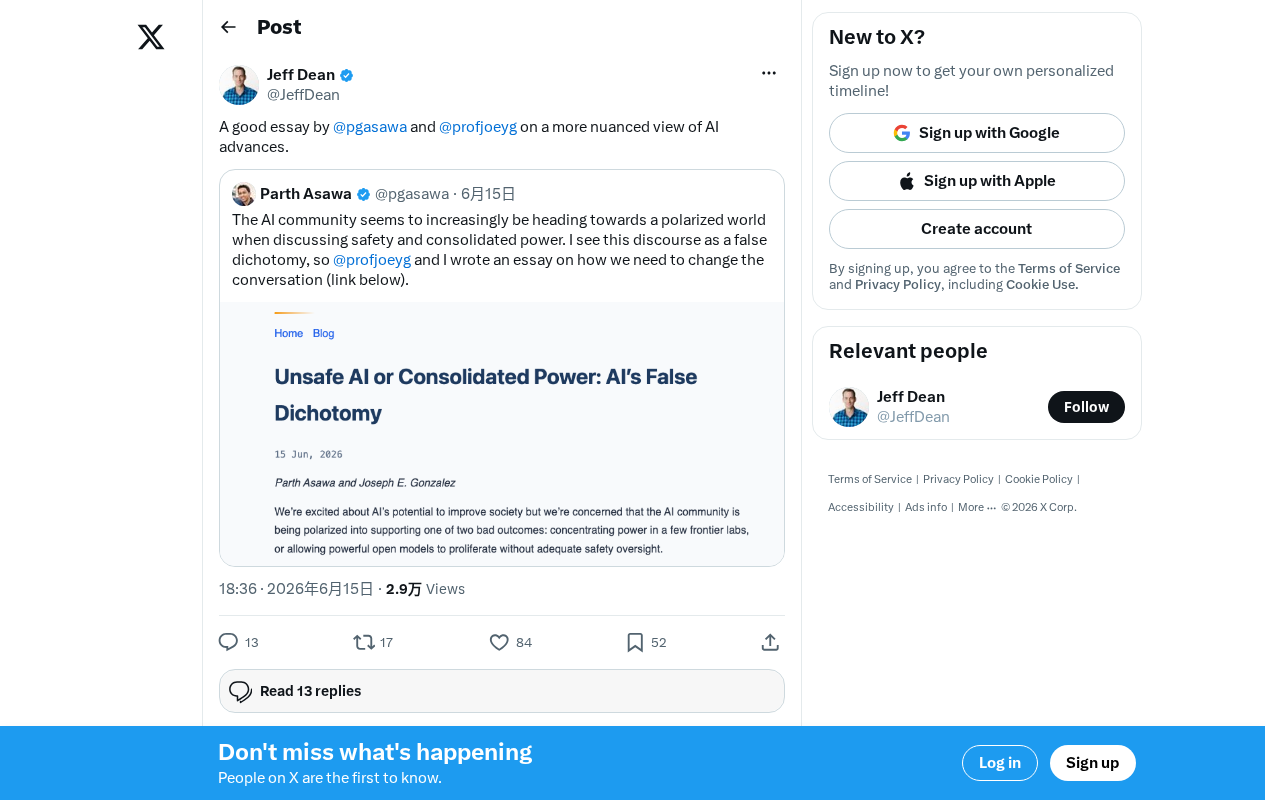
在AI领域,舆论往往在两个极端之间摇摆——要么是"AGI即将到来"的狂热乐观,要么是"AI将取代一切"的深度焦虑。近日,研究者Pranav Gasawa(@pgasawa)和Joey Gonzalez教授(@profjoeyg)联合发表了一篇引发广泛关注的文章,呼吁业界和公众以更加细致入微(nuanced)的视角来看待AI的真实进展。
这篇文章在技术社区获得了积极反响,被认为是当前AI讨论中难得的理性声音。
为什么我们需要更细致的AI评估视角?
当前AI叙事的两极化问题
当前围绕AI的公共讨论存在严重的两极化倾向。一方面,科技公司和部分研究者不断发布令人震撼的基准测试成绩,营造出AI能力飞速提升的印象;另一方面,批评者则指出这些模型在实际应用中的种种局限,质疑所谓"进步"的真实含义。
这种非黑即白的讨论框架,对理解AI的真实状态毫无帮助。我们需要的是一种能够同时承认进步与局限的分析框架——既不盲目乐观,也不一味悲观。这种思维方式在科学哲学中被称为"批判性实在论"(Critical Realism),它承认客观进步的存在,但同时强调我们对进步的认知总是受到测量工具和理论框架的限制。
基准测试与实际能力之间的鸿沟
AI领域长期存在一个被反复讨论但始终未被充分重视的问题:基准测试(benchmark)上的优异表现,并不等同于真实世界中的可靠能力。模型可能在标准化测试中表现出色,但在面对稍有变化的实际场景时却表现不佳。
要理解这一问题的深层原因,需要了解当前AI基准测试的运作方式。常见的基准测试包括MMLU(大规模多任务语言理解)、HumanEval(代码生成)、GSM8K(数学推理)等,它们通过标准化的题目集来衡量模型能力。然而,这里存在几个结构性问题:首先是Goodhart定律的体现——"当一个指标成为目标时,它就不再是一个好的指标"。当研究团队针对特定基准进行优化时,模型可能学会了解题的"捷径"而非真正掌握底层能力。其次是数据污染(data contamination)问题:由于大语言模型的训练数据来自互联网,基准测试的题目和答案很可能已经出现在训练集中,导致模型的"推理"实际上是"记忆"。此外,基准测试通常是静态的、格式固定的,而真实世界的问题往往是动态的、模糊的、需要多步交互才能明确的。
这种"基准测试幻觉"容易误导投资者、决策者和普通用户对AI能力的判断,导致不切实际的期望或不当的资源配置。近年来,研究社区已经开始尝试更动态的评估方法,如对抗性测试(adversarial evaluation)、分布外泛化测试(out-of-distribution generalization),以及基于真实用户交互的评估平台(如Chatbot Arena),但这些方法尚未成为主流叙事的一部分。
理性评估AI进展的关键维度
能力边界的清晰认知
对AI进步的细致审视,首先要求我们明确区分不同类型的能力提升。语言模型在文本生成、代码编写、知识问答等方面确实取得了显著进步,但在因果推理、长期规划、可靠性保证等方面仍然存在根本性挑战。
这里有必要解释"因果推理"与"模式匹配"之间的本质区别。当前的大语言模型本质上是基于Transformer架构的统计模型,它们通过学习海量文本中的模式和关联来生成输出。这类似于认知科学家Daniel Kahneman所描述的"System 1"思维——快速、直觉式、基于模式识别的认知过程。然而,真正的因果推理需要"System 2"思维——缓慢、刻意、基于逻辑链条的推理过程。虽然近期的思维链(Chain-of-Thought)提示和推理模型(如OpenAI的o1系列)在模拟System 2推理方面取得了进展,但这种模拟是否等同于真正的因果理解,仍然是一个开放的科学问题。在长期规划方面,当前模型的自回归生成机制(逐token预测下一个词)使其天然缺乏全局规划能力——它们更擅长"局部连贯"而非"全局最优"。
将这些不同维度的能力混为一谈,会导致对AI整体水平的误判。一个更有建设性的做法是,针对每个具体应用场景,分别评估AI的实际表现和可靠性。
从"能做什么"到"能可靠地做什么"
这或许是当前AI能力评估中最关键的思维转变。演示(demo)中的惊艳表现和生产环境中的稳定运行之间,往往存在巨大差距。一个模型偶尔能完成某项复杂任务,与它能够持续、可靠地完成该任务,是完全不同的两回事。
从工程角度来看,这涉及AI系统的"长尾问题"(long-tail problem)。在大多数常见场景下,模型可能表现良好(比如95%的情况),但剩余5%的边缘案例(edge cases)可能导致灾难性失败。在自动驾驶、医疗诊断、金融交易等高风险领域,这5%的不可靠性是完全不可接受的。此外,当前大语言模型普遍存在"置信度校准"(calibration)不足的问题——它们无法准确判断自己何时可能出错,往往以同样自信的语气输出正确答案和错误答案(即所谓的"幻觉"现象)。这意味着用户无法仅凭模型的输出来判断其可靠性。
对于企业和开发者而言,关注AI的可靠性边界比关注其能力上限更为重要。这也是为什么在实际部署中,人机协作(human-in-the-loop)的模式仍然是最务实的选择。人机协作的具体实现方式多种多样:从简单的"AI生成、人类审核"流程,到更复杂的"AI标记低置信度输出、人类介入处理"的分层系统,再到"AI作为人类决策的辅助信息源"的顾问模式。选择哪种模式,取决于具体场景的风险容忍度和效率需求。
对行业和研究的实际启示
学术研究的透明度责任
Gasawa和Gonzalez教授的文章也隐含了对学术界的呼吁:研究者在发表成果时,应当更加透明地呈现模型的局限性,而不仅仅是突出最佳表现。这种学术诚实对于维护公众信任和引导合理预期至关重要。
这一呼吁的背景是AI研究领域日益严重的"可复现性危机"(reproducibility crisis)。多项调查显示,相当比例的AI论文结果难以被独立复现,原因包括:选择性报告(只展示最佳结果而隐藏失败实验)、超参数调优过度拟合测试集、缺乏完整的实验细节披露等。近年来,学术界已经开始采取措施应对这一问题——NeurIPS等顶级会议引入了"可复现性检查清单"(reproducibility checklist),要求作者明确声明计算资源、随机种子、数据预处理步骤等关键信息;部分期刊开始要求提交代码和数据;"Model Cards"和"Datasheets for Datasets"等文档标准也在推动更全面的模型能力与局限性披露。然而,在追求论文发表和融资的压力下,过度宣传(overclaiming)仍然是一个普遍现象。
企业AI决策的理性基础
对于正在考虑AI投入的企业决策者来说,这种细致的视角尤为重要。理解AI在特定场景下的真实能力水平,有助于做出更明智的技术选型和投资决策,避免因过度期望而导致的项目失败。
具体而言,企业在评估AI解决方案时,应当关注几个关键问题:该方案在与自身业务相似的场景中是否有经过验证的案例?供应商是否愿意透明地分享失败案例和已知局限?系统在遇到超出能力范围的输入时,是否有优雅的降级机制?这些问题的答案,往往比基准测试分数更能预测AI项目的实际成败。
结语:审慎乐观才是健康的AI态度
在AI技术快速发展的当下,保持理性和细致的判断力比以往任何时候都更加重要。Gasawa和Gonzalez教授的这篇文章提醒我们:真正的进步不是靠炒作来定义的,而是需要通过严谨的评估和诚实的讨论来确认。
对AI保持"审慎的乐观"——承认其巨大潜力的同时清醒认识其当前局限——或许才是推动这一领域健康发展的最佳态度。这种态度不仅适用于技术从业者,也适用于政策制定者、投资者和普通公众。在信息过载的时代,能够区分信号与噪音、实质与炒作的能力,本身就是一种稀缺而宝贵的素养。
相关推荐
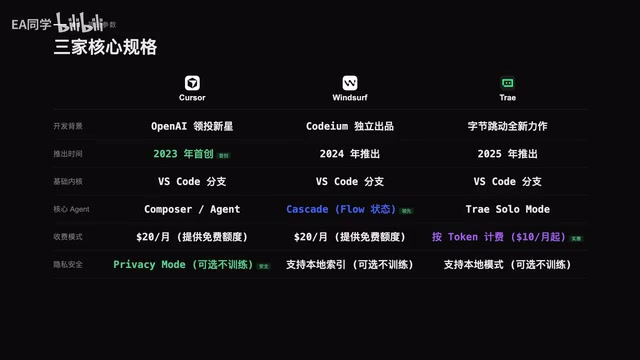
Cursor vs Windsurf vs Trae:三大AI IDE深度横评
从编程补全、Agent自主性、价格成本等五大维度全面对比Cursor、Windsurf、Trae三款主流AI IDE,附详细评分与选型建议,帮开发者找到最适合的AI编程工具。
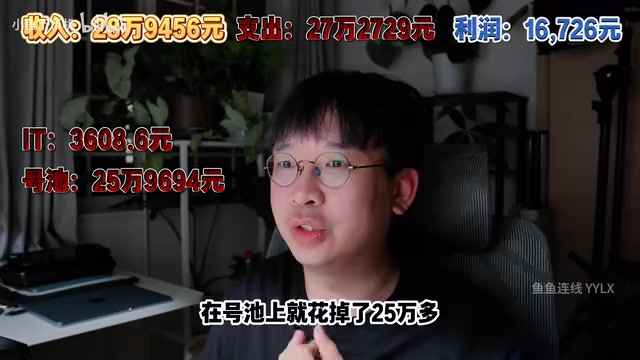
AI中转站创业首月公开账本:29万流水仅赚1.6万
三人团队运营AI中转站(API聚合转发)一个月,公开全部收支明细:总流水28.9万,API成本占95%,账面利润仅1.67万。深度拆解修正利润率、成本结构与竞争逻辑,为想入局的创业者提供真实参考。
Trae实战教程:3条提示词搞定全栈网站开发
详解如何用字节跳动AI编程工具Trae,通过3条提示词快速生成前端页面、后端API、管理后台,完成全栈网站搭建。含环境配置、操作步骤及商用可行性分析。