AI开发Chrome插件实战:从UI设计到调试的完整方法论
前言:为什么用AI开发Chrome插件
在日常工作中,我们经常会遇到一些重复性的痛点问题。比如使用豆包等AI工具生成图片时,下载的图片右下角总会带有水印。如果只是偶尔一两张还好,手动裁剪即可解决;但当你需要批量处理上百张封面素材时,这个问题就变得非常棘手了。
这时候,开发一个Chrome插件来自动化解决这类问题就成了最优解。而借助AI编程工具,即使你不是专业的前端开发者,也能快速实现一个功能完整的浏览器插件。本文将分享一套经过实践验证的AI开发Chrome插件方法论,帮助你从0到1完成插件开发。
Chrome插件架构基础
Chrome插件(Chrome Extension)是基于Web技术构建的浏览器扩展程序,采用Manifest V3架构。一个标准的Chrome插件通常由以下部分组成:manifest.json(配置清单,定义插件的权限、入口文件等)、popup.html(点击插件图标弹出的面板界面)、background.js(后台服务脚本,处理事件监听)、content scripts(注入到网页中执行的脚本)。理解这个基本结构对于后续让AI生成代码时给出准确指令非常重要。
值得注意的是,Manifest V3是Chrome在2020年推出的新一代插件架构标准,相比之前的V2版本有几个重大变化:后台脚本从持久运行的background page变为按需唤醒的Service Worker,这意味着插件不再常驻内存,而是在需要时才被激活,显著降低了资源占用;网络请求拦截API从webRequestBlocking改为declarativeNetRequest,采用声明式规则而非编程式拦截,提升了安全性和性能;远程代码执行被严格禁止,所有代码必须打包在插件内部。此外,Chrome插件运行在浏览器提供的安全沙箱中,每个组件(popup、content script、background)都有独立的执行环境和权限边界,它们之间通过Chrome提供的消息传递API(chrome.runtime.sendMessage)进行通信。这种隔离机制既保证了安全性,也是开发中需要特别注意的架构约束。
第一步:用AI生成插件UI面板设计
为什么要先设计面板而非直接写代码
很多人在使用AI开发插件时,上来就直接描述功能需求让AI生成代码。这种做法的问题在于:AI生成的界面往往非常粗糙,而且你自己对最终产品也没有清晰的预期,后续调整会非常低效。
正确的做法是先让AI帮你设计插件的UI面板,以平铺的方式展示每个页面的功能和布局。这样你就能清楚地知道:
- 插件有几个页面
- 每个页面承载什么功能
- 用户的操作流程是怎样的
AI辅助UI设计的技术原理
当我们让AI生成UI面板设计时,实际上是在利用多模态大语言模型的图像生成能力。像GPT-4o、Claude等模型可以根据文字描述生成界面线框图或高保真设计稿。这种方式的优势在于,它将传统需要Figma、Sketch等专业工具完成的设计工作,压缩到了自然语言对话中。生成的设计图虽然不如专业设计师精细,但作为开发参考已经足够明确。
从技术实现角度来看,多模态模型生成UI设计的过程涉及几个关键能力的协同:首先是语义理解——模型需要将"去除水印""上传图片"等自然语言需求映射为具体的UI组件(按钮、上传区域、进度条等);其次是布局推理——模型基于大量UI设计数据的训练,能够推断出合理的组件排列方式、间距比例和视觉层次;最后是图像合成——将这些抽象的布局决策渲染为可视化的设计图。相比传统设计流程中需要经历需求文档→原型图→视觉稿→设计评审的多个环节,AI辅助设计将这个过程压缩到了分钟级别。不过需要注意的是,AI生成的设计更适合作为快速原型验证工具,对于需要严格遵循品牌规范或复杂交互逻辑的场景,仍然建议与专业设计师协作。
具体的提词技巧
你可以这样描述需求:"我要设计一个去除图片水印的Chrome插件,请帮我设计插件界面,以平铺的面板形式展示所有页面。"AI会生成一个包含多个页面卡片的设计图,让你一目了然地看到整个插件的结构。
如果第一版不满意,可以继续和AI对话进行微调。关键是要多轮迭代,不要期望一次就得到完美结果。经过几轮调整后,你会得到一个满意的UI方案。
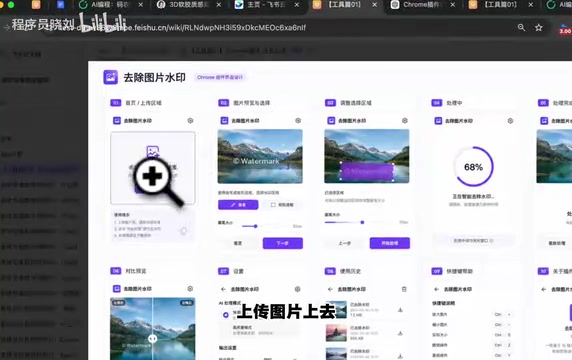
以去水印插件为例,最终确定的流程是:上传图片 → 去除水印 → 点击下一步 → 加载处理中 → 处理完成展示无水印版本。整个流程清晰流畅。
第二步:基于设计图生成完整插件代码
当UI设计确定后,下一步就是将设计图转化为可运行的代码。你可以将最终版的插件设计图直接提供给AI,让它生成完整的Chrome插件代码。
从设计到代码的转换原理
将设计图转化为代码这一步,本质上是利用了AI的视觉理解能力(Vision能力)。当你将UI设计图提供给支持图像输入的AI模型时,模型会识别图中的布局结构、颜色方案、组件类型等视觉元素,然后将其翻译为对应的HTML结构、CSS样式和JavaScript逻辑。这比纯文字描述的转换准确率高出很多,因为视觉信息消除了语言描述的模糊性。
Vision-to-Code(视觉转代码)技术的发展经历了几个重要阶段。早期的pix2code(2017年)等研究尝试用深度学习直接从截图生成代码,但效果有限且只能处理简单界面。随着Transformer架构和大规模多模态预训练的突破,现代模型(如GPT-4V、Claude 3.5 Sonnet)已经能够理解复杂的视觉层次关系:它们不仅能识别"这是一个按钮",还能推断出按钮的状态变化、点击后的逻辑流转、以及与其他组件的数据关联。准确率的提升主要来自两个方面:一是视觉编码器(如ViT)对UI元素的精确识别能力,二是语言模型对前端代码模式的深度记忆——模型在训练中见过海量的"设计-代码"配对数据,形成了强大的跨模态映射能力。实践中,提供设计图比纯文字描述能减少约60%-70%的后续修改轮次,因为视觉参考消除了"圆角按钮到底多圆""间距到底多大"这类文字难以精确表达的细节。
这一步的关键在于:有了明确的视觉参考,AI生成的代码质量会显著提高。因为它不再是凭空想象界面,而是有了具体的还原目标。
生成代码后,按照以下步骤安装插件进行测试:
- 打开Chrome浏览器,进入
chrome://extensions/ - 开启"开发者模式"
- 点击"加载已解压的扩展程序"
- 选择你的插件项目文件夹
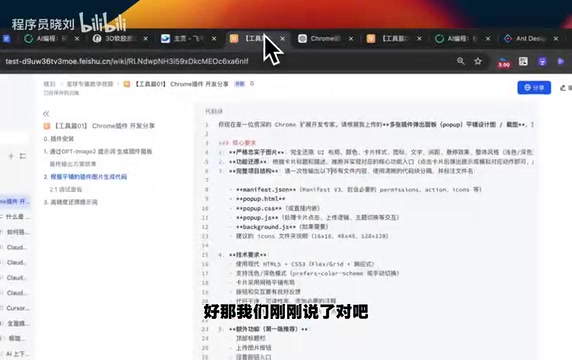
第三步:利用控制台高效调试插件
打开Chrome插件专属调试控制台
这是本文最核心的技巧之一。很多人不知道Chrome插件有自己独立的调试控制台。操作方法是:
- 点击打开你的插件面板
- 在插件面板上右键
- 选择"检查"(Inspect)
这时会弹出一个专属于该插件的开发者工具窗口,你可以在Console面板中看到所有的错误信息和日志输出。
Chrome DevTools调试机制详解
Chrome插件的调试控制台本质上是一个独立的DevTools实例。与普通网页调试不同,插件的popup页面运行在独立的上下文环境中,它有自己的DOM树、JavaScript执行环境和网络请求。这就是为什么你无法在普通网页的F12控制台中看到插件的日志信息,必须通过右键检查打开插件专属的调试窗口。此外,background service worker也有独立的调试入口,可以在chrome://extensions页面中点击"Service Worker"链接打开。
深入理解这种多上下文隔离机制对于高效调试至关重要。Chrome插件实际上运行在至少三个相互隔离的JavaScript执行环境中:Popup上下文——当用户点击插件图标时创建,关闭popup面板后即被销毁,这意味着popup中的变量和状态不会持久保存;Background Service Worker上下文——独立于任何网页和popup存在,负责处理事件监听、定时任务和跨组件通信,在Manifest V3中它是事件驱动的,空闲时会被浏览器回收;Content Script上下文——虽然注入到目标网页的DOM中,但它的JavaScript执行环境与网页本身的脚本是隔离的(称为"isolated world"),content script可以访问和修改页面DOM,但无法直接调用页面中定义的JavaScript函数,反之亦然。这三个上下文之间的通信必须通过chrome.runtime.sendMessage或chrome.tabs.sendMessage等API实现。调试时,每个上下文都需要打开对应的DevTools窗口,这也是新手最容易困惑的地方——在错误的控制台中查找日志自然什么都看不到。
将错误信息反馈给AI快速修复
当控制台出现报错时,直接复制错误信息交给AI进行修正。这种"运行→报错→修复"的循环是AI编程中最高效的调试方式。AI能够根据具体的错误堆栈信息,精准定位问题并给出修复方案。
迭代式AI编程的工作流范式
本文介绍的"运行→报错→修复"循环,在软件工程中被称为REPL驱动开发(Read-Eval-Print Loop)的AI增强版本。传统开发中,开发者需要自己理解错误信息、查阅文档、编写修复代码;而在AI辅助模式下,这个循环被大幅加速——AI既是错误的解读者,也是修复方案的生成者。这种模式特别适合Chrome插件这类API规范明确、错误信息标准化的开发场景。
REPL的概念最早源于Lisp语言社区(1960年代),后来被Ruby、Python等动态语言广泛采用,其核心理念是通过即时反馈缩短开发周期。AI增强版的REPL将这一理念推向了新的高度:传统REPL中,开发者需要具备解读错误信息的专业知识;而在AI辅助模式下,即使开发者不完全理解错误的技术细节,AI也能基于错误类型、堆栈追踪和代码上下文给出修复建议。Chrome插件开发特别适合这种模式,原因有三:第一,Chrome Extension API的错误信息高度标准化,如"Uncaught TypeError: chrome.tabs.query is not a function"这类错误,AI可以立即识别为权限配置缺失;第二,插件的代码量通常较小(几百到几千行),AI能够在有限的上下文窗口内理解完整的代码结构;第三,Chrome插件的功能边界清晰,不涉及复杂的后端架构或分布式系统问题,修复方案通常是确定性的。实践中,一个典型的调试循环大约需要3-5轮迭代即可解决大部分问题,整个过程可能只需要10-15分钟。
UI还原度不够的解决方案
如果发现某个页面和设计图差距较大,可以使用专门的提示词让AI重新还原。将设计图和当前实际效果一起提供给AI,明确指出哪些地方需要调整,AI就能进行针对性的修复。
实战案例:网页配色提取插件
除了去水印插件,这里还有另一个实用案例——网页配色提取插件。这个插件可以:
- 自动分析当前网页的颜色分布
- 提取主要配色方案
- 生成可复用的色彩提词
- 帮助你快速复刻相似风格的网页设计
从技术实现角度来看,网页配色提取插件主要依赖content script的注入机制来完成工作。当用户激活插件时,content script会被注入到当前浏览的网页中,然后通过DOM遍历API(如document.querySelectorAll('*'))获取页面上所有元素,并读取它们的计算样式(window.getComputedStyle)中的颜色相关属性,包括color、background-color、border-color等。收集到的颜色数据通常需要经过去重、归一化(将rgb、hex、hsl等不同格式统一)和聚类分析(找出出现频率最高的主色调)等处理步骤。更高级的实现可能会使用Canvas API对页面进行截图,然后通过像素级分析提取颜色分布,这种方式能捕获到CSS无法直接获取的渐变色和图片主色调。最终,提取结果通过chrome.runtime.sendMessage传递回popup界面进行展示。这个案例很好地展示了Chrome插件各组件协作的典型模式:popup负责用户交互,content script负责页面数据采集,background负责协调通信。
这个案例说明了一个重要观点:Chrome插件的开发思路是通用的。无论是去水印、提取配色还是其他功能,核心方法论都是一样的:先设计→再编码→最后调试。
总结:AI开发Chrome插件的三个关键原则
-
先视觉后代码:不要急于让AI写代码,先用AI生成清晰的UI设计方案,确保你对最终产品有明确预期。
-
多轮迭代优于一步到位:无论是UI设计还是代码生成,都不要期望一次完美。通过多轮对话逐步优化才是正确的工作流。
-
善用控制台调试:掌握插件右键检查的技巧,将报错信息直接反馈给AI,形成高效的开发闭环。
掌握这套方法论后,即使是编程新手也能在短时间内开发出功能完整、界面美观的Chrome插件。AI降低了编程的门槛,但清晰的开发思路和方法论仍然是决定最终产品质量的关键因素。
核心要点
核心要点
相关推荐

CodeGraph:5万星开源神器让AI编程省一半Token
CodeGraph是一款GitHub 5万星开源工具,通过构建代码知识图谱让AI编程助手直接查图定位代码,实测Token消耗减少47%、响应速度提升22%,百分百本地运行保障代码安全。

VibeCoding入门教程:零基础用自然语言开发软件完全指南
VibeCoding(氛围编程)让零基础用户通过自然语言与AI对话即可开发软件。本文详解VibeCoding的核心理念、学习路径与实践方法,帮你快速上手这种低门槛的软件开发新范式。
UU加速器加速Cursor教程:国内稳定使用AI编程工具的合规方案
详解如何使用网易UU加速器加速Cursor AI编程工具,包括节点选择、启动配置等完整操作步骤,帮助国内开发者合规解决Cursor网络连接慢、无法使用的问题。