AI逆向实战:一键破解魔改SHA-1与2万行混淆代码
AI工具大幅提升JS逆向工程效率,快速破解混淆加密算法
本文以爱搜网登录接口为案例,展示AI逆向工程如何替代传统手动分析方法。面对2万多行混淆JS代码和魔改SHA-1算法生成的加密参数(he、san、seclet),传统逆向需要数小时甚至数天的断点追踪和代码分析,而借助大语言模型的代码理解和模式匹配能力,可在几十分钟内完成算法还原并输出可运行的Python代码。
AI逆向正在改变爬虫逆向工程的效率
传统的JS逆向工程需要开发者手动分析混淆代码、追踪加密逻辑,往往耗费数小时甚至数天。而如今,借助AI工具(如OpenAI Codex配合浏览器调试),同样的工作可以在几十分钟内完成。
本文以爱搜网(ISO官网)为实战案例,详细拆解如何利用AI一键搞定魔改SHA-1算法和2万多行混淆代码的逆向分析。传统逆向和AI逆向之间的差距,不在于技术能力,而在于方法论的选择。
JS逆向工程与代码混淆:为什么这么难?
JS逆向工程是指通过分析已编译或混淆的JavaScript代码,还原其原始逻辑的过程。现代Web应用为保护核心业务逻辑,普遍采用多种混淆技术:变量名替换(将有意义的变量名替换为单字母或随机字符串)、控制流平坦化(将正常的if/else、循环结构打散为状态机形式)、字符串加密(将明文字符串编码为十六进制或Base64)以及代码压缩(删除空白和注释)。工业级混淆工具如obfuscator.io、javascript-obfuscator可以将数百行清晰代码转化为数万行几乎不可读的混淆代码,使人工分析的时间成本呈指数级增长。这正是本文案例中2万多行混淆文件令传统逆向工程师望而生畏的根本原因。
目标分析:登录接口的加密参数
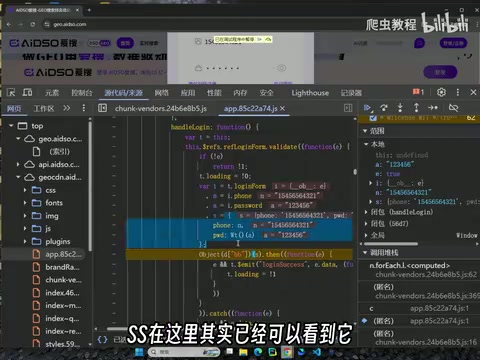
打开爱搜网的登录页面,使用开发者工具抓包,输入手机号和密码(如123456)后点击登录,可以捕获到一个 login 请求。观察请求参数,会发现以下几个关键加密字段:
- pwd:密码加密后的密文,如
110adcf883e...,输入123456后得到的值,明显是标准MD5 - he:一个经过魔改SHA-1算法生成的哈希值
- san:另一个基于魔改SHA-1的加密参数
- ts:时间戳
- seclet:安全校验参数
其中pwd是标准MD5,相对简单。真正的难点在于 he、san 和 seclet 这三个参数——它们来自一个2万多行的混淆JS文件,使用了魔改的SHA-1算法。
SHA-1算法背景:SHA-1(Secure Hash Algorithm 1)是由美国国家安全局设计的密码散列函数,输入任意长度数据,输出固定160位(40个十六进制字符)的哈希值,其核心特性是单向性——无法从哈希值反推原始输入。网站开发者常在标准SHA-1基础上进行"魔改"以增加破解难度,常见手法包括:多轮迭代(对同一数据执行多次哈希运算)、截取部分结果(只取哈希值的某几位)、拼接固定盐值(在输入或输出中加入特定字符串)、修改初始化向量(改变SHA-1内部的初始常量值)。这些魔改操作使得即便逆向工程师识别出SHA-1的基本结构,也无法直接用标准库复现结果,必须精确还原每一处修改。
传统逆向:断点追踪的痛苦过程
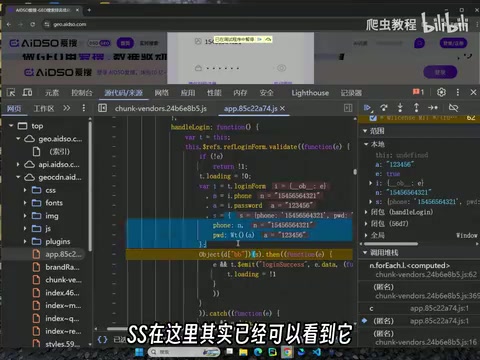
跟栈定位加密入口
按照传统的JS逆向方法,需要在开发者工具中逐层跟栈。从 L.request 开始,跳过Promise异步回调和export导出等无关代码,逐步定位到参数生成的位置。
具体步骤包括:
- 在请求拦截处下断点,找到参数
R的传入位置 - 逐层向上追溯,找到密码加密(MD5)的调用点
- 继续追踪
he和san的生成逻辑,定位到混淆文件中的SH函数 - 发现这些函数都指向同一个巨大的混淆JS文件
这个过程中,你会遇到大量的代码混淆:变量名被替换为无意义的单字母、控制流被打乱、字符串被编码。手动分析2万多行这样的混淆代码,效率极低。
搜索参数名的困境
更棘手的是,直接在代码中搜索参数名(如 seclet)根本找不到正确位置。搜索结果要么是链接中的字符串,要么是无关的赋值语句(比如赋值的是一个表情符号),因为参数名本身也经过了混淆处理。这正是代码混淆给传统逆向带来的最大障碍——不仅逻辑被打乱,连"入口"本身也被隐藏了。
AI逆向实战:三个加密参数的破解过程
AI逆向的技术基础:大语言模型的代码理解能力
在进入实战之前,有必要理解AI为何能胜任这项工作。OpenAI Codex及其后继的GPT-4等模型,基于数百亿行开源代码进行预训练,使其能够理解代码语义、识别常见算法模式,并在不同编程语言之间进行转换。在逆向工程场景中,大语言模型的优势在于**"模式匹配"而非"逐行执行"**——它能从混淆代码的结构特征(如特定的位运算序列、循环展开模式)中识别出底层算法,类似于人类专家的直觉判断,但速度快数十倍。当前主流模型支持超过10万Token的上下文窗口,足以容纳数万行代码进行整体分析,这是AI逆向工程实用化的关键技术前提。
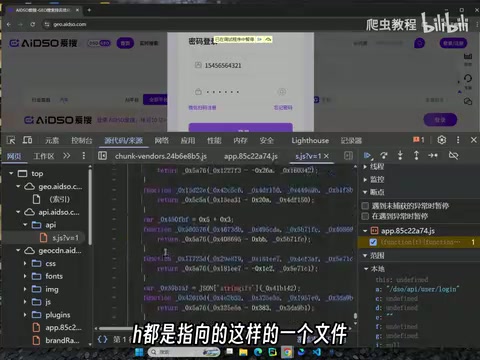
第一步:破解 san 和 he(魔改SHA-1还原)
将整个2万多行的混淆文件下载到本地,交给AI进行分析。提示词需要包含关键上下文信息:
"这是一个JS文件,调用该文件里面的SH函数,传入了[具体参数],得到了[具体结果值],帮我分析并还原算法。"
AI的分析过程非常系统:
- 识别混淆包规模:确认这是一个大型混淆文件
- 定位关键函数:找到H函数的定义位置
- 还原算法逻辑:发现它是SHA-1跑了两次,中间截取8位,再拼接固定的盐值
- 补充缺失信息:需要域名作为运算参数,补充后重新计算
AI最终输出了还原后的Python代码,运行即可得到正确的 san 值。同样的方法处理 he 参数——它使用了内嵌方法,传入固定参数 dt 字符串,AI同样成功定位并还原了其中涉及的 se、host、key 等逻辑。
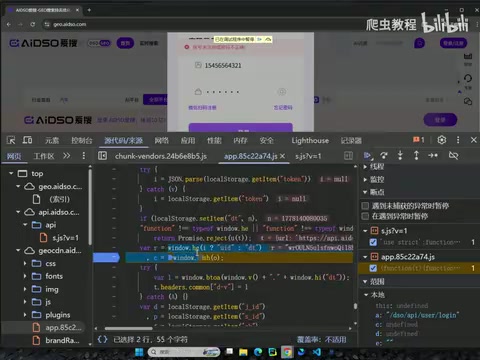
第二步:破解 seclet(AI全自动分析)
对于 seclet 参数,采用了更激进的策略——只给AI一个页面链接,不提供任何额外提示,让它自主完成全部逆向分析。
提示词极其简洁:
"帮我分析这个登录接口中参数的生成逻辑。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。