AI全栈开发技术架构:从原型到上线的三层递进路径
为什么AI全栈开发成为面试必考题?
在当前的前端和全栈开发面试中,一个问题出现的频率越来越高:"你有没有用AI开发过产品?" 无论是初中级还是高级岗位,AI相关的项目经验已经从加分项变成了必答题。
很多开发者面对这个问题时哑口无言——不是因为技术能力不够,而是从未系统性地思考过如何将AI融入自己的开发工作流。本文将基于Node.js全栈开发的视角,从环境搭建、工程架构到AI应用引擎设计,梳理一套完整的AI全栈开发落地路径。
AI全栈开发的三层技术架构
整个AI全栈开发的技术体系,可以按照三个层次递进理解:基础工程层、部署交付层、AI应用层。
第一层:Node.js + TypeScript + Monorepo 工程架构
对于有Node.js开发经验的同学来说,现阶段必须掌握的是 Node.js + TypeScript + Monorepo 这套组合拳。这不仅是技术选型的问题,更是工程化思维的体现。
-
TypeScript 提供了类型安全,在AI应用中尤其重要——当你处理各种模型的输入输出、Prompt模板、RAG检索结果时,类型系统能帮你避免大量运行时错误。TypeScript的类型系统在AI全栈开发中扮演着比传统Web开发更关键的角色。AI应用涉及大量非结构化数据的处理——大模型API返回的JSON结构可能因模型版本不同而变化,RAG检索结果包含相似度分数、文档元数据等复杂嵌套结构,Prompt模板中的变量插值需要严格的类型约束。没有类型系统的保护,这些数据在多层传递过程中极易产生难以追踪的运行时错误。TypeScript的泛型、联合类型和类型守卫等特性,能够在编译阶段就捕获这些潜在问题,大幅降低AI应用的调试成本。
-
Monorepo 架构则解决了AI全栈项目中常见的代码复用问题。前端界面、后端API、AI服务编排、共享类型定义,这些模块在Monorepo下可以高效协作,避免多仓库带来的版本同步噩梦。Monorepo(单一代码仓库)是将多个相关项目放在同一个版本控制仓库中管理的策略,Google、Meta等公司早已大规模采用。在AI全栈项目中,前端调用AI接口时需要的类型定义、后端处理Prompt时的工具函数、AI服务编排的配置schema,这些跨模块共享的代码在Monorepo下可以通过workspace直接引用,无需发布npm包。主流的Monorepo工具如Turborepo、Nx、pnpm workspace等提供了增量构建、任务编排、依赖图分析等能力,确保即使项目规模增长,构建效率也不会显著下降。
第二层:基于Docker的CI/CD编排与部署
从原型到正式上线,中间隔着的不只是代码,还有完整的交付流程。基于Docker的CI/CD编排是将AI应用从开发环境推向生产环境的关键桥梁。
容器化部署对AI应用尤为重要:模型服务、向量数据库、API网关、前端应用,每个组件都可以独立容器化,通过编排工具统一管理。这种架构不仅便于水平扩展,也让团队协作和环境一致性得到保障。
AI应用的部署复杂度远超传统Web应用。一个典型的AI全栈项目可能包含:运行LLM推理的模型服务(如vLLM、Ollama)、存储向量嵌入的向量数据库(如Milvus、Qdrant、Weaviate)、处理文档解析的预处理服务、提供API的后端服务、以及前端应用。这些组件对运行环境的要求各不相同——模型服务可能需要GPU驱动,向量数据库需要特定的内存配置。Docker通过容器化将每个组件的运行环境完全隔离和标准化,Docker Compose或Kubernetes则提供了声明式的编排能力,让开发者用一个配置文件就能定义整个系统的拓扑结构、网络通信和资源限制。
第三层:AI应用引擎架构设计
这是整个技术架构中最核心的部分,涵盖三个关键模块:
-
提示词工程(Prompt Engineering):如何设计、管理和优化Prompt模板。提示词工程远不止是"写好一段提示词"这么简单,它已经发展为一套系统化的工程实践。核心技术包括:Few-shot Learning(通过示例引导模型输出格式)、Chain-of-Thought(引导模型逐步推理)、角色设定(System Prompt定义模型行为边界)、输出格式约束(JSON Mode、Function Calling)。在工程化层面,Prompt需要版本管理、A/B测试、效果评估(通过自动化评测框架如Promptfoo)。企业级应用中,Prompt通常以模板形式存储,支持变量注入和条件渲染,类似于前端的模板引擎。Prompt的管理和优化直接影响AI应用的输出质量和成本控制。
-
RAG检索增强生成:如何构建知识库并与大模型结合,实现基于私有数据的智能问答。RAG(Retrieval-Augmented Generation)是解决大模型"幻觉"问题和私有知识问答的核心技术范式。其工作流程分为两个阶段:离线索引阶段,将企业文档通过文本分块(Chunking)、向量嵌入(Embedding)处理后存入向量数据库;在线检索阶段,用户提问时先将问题向量化,在向量数据库中检索最相关的文档片段,然后将这些片段作为上下文注入Prompt,再交给大模型生成回答。RAG的关键技术挑战包括:分块策略的选择(固定长度vs语义分块)、嵌入模型的选型、检索算法的优化(混合检索、重排序)、以及上下文窗口的有效利用。相比微调模型,RAG的优势在于数据更新实时、成本更低、可解释性更强。
-
AI应用引擎的编排架构:如何设计一套可扩展的引擎,支持多步骤、多模型的任务编排。编排引擎是Coze、Dify、LangFlow等AI应用开发平台的核心组件,其本质是一个有向无环图(DAG)执行引擎。每个节点(Node)代表一个原子操作——可以是LLM调用、知识库检索、代码执行、HTTP请求或条件判断;连线(Edge)定义了数据流向和执行顺序。引擎需要实现拓扑排序确定执行顺序、支持并行分支提升效率、处理条件路由实现动态流程、管理节点间的数据传递(通常通过共享上下文或消息总线)。高级特性还包括:流式输出支持(SSE/WebSocket)、执行状态持久化(支持断点续跑)、超时和重试机制、以及运行时的可观测性(日志、链路追踪)。
很多面试者在被问到"AI应用引擎是如何实现的"时,无法说清楚编排引擎的执行细节。这恰恰是区分普通开发者和架构级开发者的分水岭。
三个层级的面试问题拆解
这套技术架构对应着不同级别的面试考察点,理解这些问题的递进关系,有助于明确自己的学习方向。
初中级面试:全栈开发的工程化落地
典型问题:"你之前在项目里做过全栈开发,具体是怎么做的?"
这个层级考察的是你对现代全栈工程化的理解。仅仅会写Node.js是不够的,面试官期望听到的是你如何用TypeScript保证代码质量,如何用Monorepo管理多模块项目,如何设计合理的项目结构。
中高级面试:业务场景中的AI智能化落地
典型问题:"如果让你主导公司某个产品的智能化改造,你会怎么做?"
这里有一个非常重要的认知转变:不要小看你正在做的产品。 很多同学觉得自己在做后台管理系统,感觉"没什么亮点"。但事实是,只要产品还在运作、还在为公司创造价值,就一定存在可以用AI优化的业务环节。
关键在于你能否在业务流程中 挖掘出具体的AI落地点:
- 表单填写环节能否用AI辅助自动填充?
- 数据审核环节能否用AI做初筛?
- 客服工单能否用RAG实现智能回复?
- 报表分析能否用大模型生成自然语言摘要?
把这些具体的智能化落地作为你的业务重难点来讲述,远比说"虚拟列表"、"大文件上传"这些烂大街的技术点更有说服力。面试的核心技巧是贴合业务、贴合时事、贴合当下主流技术栈。
专家级面试:AI应用开发平台的架构设计
典型问题:"如果让你设计一套类似Coze/Dify的AI应用开发平台,你会怎么做?"
这个问题考察的是架构师级别的系统设计能力。Coze是字节跳动推出的AI应用开发平台,Dify则是开源社区中最活跃的LLM应用开发框架之一,它们都提供了可视化的工作流编排、知识库管理、模型接入等能力,让非技术人员也能构建AI应用。理解这类平台的架构设计,意味着你需要能够说清楚:
- 编排引擎的设计:如何定义节点(Node)、连线(Edge)、执行流(Flow),支持条件分支、循环、并行等控制逻辑。这套设计与工作流引擎(如Temporal、Airflow)有相似之处,但针对AI场景需要支持流式输出、Token计费、模型降级等特殊需求。
- 引擎执行的细节过程:从用户输入到最终输出,数据如何在各节点间流转,异常如何处理,状态如何管理。需要考虑长时间运行的LLM调用如何不阻塞整体流程,以及如何实现执行过程的可观测性。
- 可扩展性设计:如何支持自定义节点、插件机制、多模型接入。好的架构应该遵循开闭原则,通过抽象接口和注册机制,让新能力的接入不需要修改核心引擎代码。
这不仅需要对AI应用有深入理解,更需要扎实的软件架构功底。
给开发者的AI全栈实践建议
突破代码层面,培养架构思维
这是一个被反复强调但很多人仍然忽视的观点:如果你自始至终只关注代码,架构思维和设计思维就很难提升,薪资也很难有大的跨越。
代码能力是基础,但在AI时代,更重要的是:
- 架构思维:能否设计出可扩展、可维护的系统
- 业务洞察:能否在业务中发现AI的应用机会
- 技术选型能力:能否在众多AI工具和框架中做出合理选择。当前AI开发生态中,框架选择极为丰富——LangChain、LlamaIndex用于LLM应用编排,Vercel AI SDK专注于前端AI集成,Semantic Kernel面向企业级场景。向量数据库有Pinecone(云托管)、Milvus(开源分布式)、Chroma(轻量级)等不同定位的选择。能否根据项目规模、团队能力、性能需求做出合理判断,是技术选型能力的核心体现。
从当前项目切入AI实践
不需要从零开始一个全新的AI项目。回到你当前正在做的产品,认真审视每一个业务流程,找到那个最适合引入AI的切入点,把它做深做透。这比任何demo项目都更有说服力。
实践中,最容易切入的AI场景通常包括:基于现有文档构建RAG问答系统(技术门槛适中,业务价值明显)、利用大模型API实现文本生成/摘要/分类(调用成本低,见效快)、以及在现有表单或搜索功能中集成AI辅助(用户体验提升显著)。选择切入点时,建议优先考虑数据已经就绪、效果容易量化、且不涉及核心业务风险的场景。
构建从原型到上线的完整技术闭环
从环境搭建到工程架构,从Docker部署到AI应用引擎,确保你能跑通从原型到上线的完整链路。面试官最看重的不是你用了多少新技术,而是你能否把一个想法变成一个真正运行的产品。
完整的技术闭环意味着你需要关注AI应用上线后的持续运营:模型调用的成本监控(Token消耗追踪)、输出质量的持续评估(建立评测数据集和自动化评测流水线)、用户反馈的闭环收集(用于优化Prompt和知识库)、以及系统的可观测性建设(延迟监控、错误率告警、调用链追踪)。这些生产级的工程实践,是区分"能写Demo"和"能交付产品"的关键差异。
总结
AI全栈开发不是一个遥不可及的概念,它的核心是将传统的全栈开发能力与AI应用能力相结合。Node.js + TypeScript + Monorepo提供工程基础,Docker + CI/CD保障交付流程,Prompt工程 + RAG + 编排引擎构成AI应用核心。掌握这套完整的技术架构,无论是应对面试还是实际项目落地,都能让你在AI时代占据主动。
核心要点
相关推荐
Gemini核心团队罕见同框:Noam Shazeer等关键人物公开对话解析
Google Gemini项目核心负责人Oriol Vinyals、Noam Shazeer、Koray Kavukcuoglu罕见同框对话,解析团队阵容背景、协作意义及释放的行业竞争信号。
Two Minute Papers:两分钟读懂前沿AI论文的科普标杆
深度解析Two Minute Papers频道如何用两分钟讲透AI前沿论文,涵盖创始人Károly的方法论、频道覆盖领域、AI科普传播价值及中文科普生态的借鉴启示。
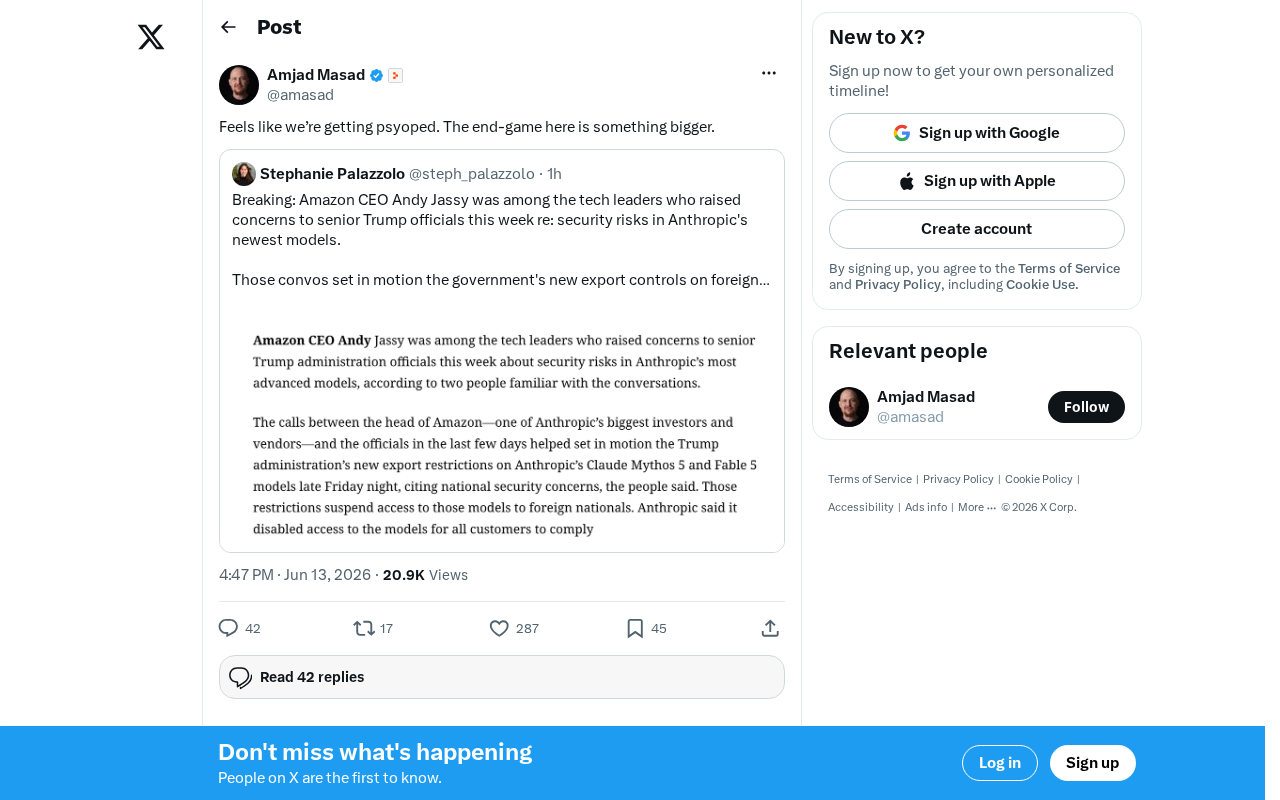
AI行业心理战:叙事操控、生态锁定与终局博弈
AI行业频繁的产品发布和叙事构建背后,隐藏着数据垄断、生态锁定和预期管理的深层博弈。本文解析科技圈热议的Psyop现象,揭示AI竞赛的真正终局,并为开发者和用户提供应对策略。