AI全栈开发入门:从机器学习到大模型的知识体系梳理

从机器学习到大模型的学习路径梳理与方法论指导
本文基于一套AI全栈开发课程的前置篇,系统梳理了人工智能、机器学习、深度学习和大模型之间的递进关系,阐述了从大数据到Transformer架构的技术演进脉络。文章强调学习应以概念理解为先、实战与理论交替推进的螺旋式方法,帮助不同基础的开发者找到高效的AI入门路径。
对于想要入门AI大模型领域的开发者来说,一个常见的困惑是:我需要学多少机器学习?深度学习要掌握到什么程度?这些概念之间到底是什么关系?本文基于一套AI全栈开发课程的前置篇导读,系统梳理从机器学习到大模型的知识脉络,帮助不同基础的读者找到适合自己的学习路径。
课程定位:零基础科普与项目实战并重
这套课程的设计思路很明确:前置篇负责概念科普,后续篇章以技术门类为核心展开实战。整体结构包括前置篇(理论基础)、DeepSeek篇、Dify篇、MCP篇、FastGPT篇、企业级应用篇,以及模型篇和训练篇。
对于零基础学习者,前置篇的目标是让你理解概念而非动手实现。比如你需要知道机器学习分为监督学习、非监督学习和半监督学习三大类,需要理解深度学习与神经网络的关系,但不需要去手写机器学习算法。
背景知识:三类学习范式的本质区别 监督学习是指用带有标签的数据训练模型,例如图像分类(每张图片都标注了类别);非监督学习则从无标签数据中自动发现结构,如聚类算法;半监督学习介于两者之间,利用少量标签数据和大量无标签数据共同训练。值得注意的是,大语言模型的预训练阶段本质上属于自监督学习——一种特殊的非监督学习,模型通过预测下一个词来从海量文本中自动学习语言规律,无需人工标注。这也是大模型能够利用互联网级别数据规模的关键原因。
对于已经在AI行业工作的从业者(如AI运维、应用开发),这部分可以快速浏览,重点放在后续的实战篇章。
课程主要基于DeepSeek大模型进行应用开发,涵盖Agent技术、MCP协议快速上手、Dify工作流编排、微信/钉钉等IM生态集成(NandBot),以及DeepSeek蒸馏技术的理论与实战。
人工智能技术版图:一张韦恩图理清概念关系
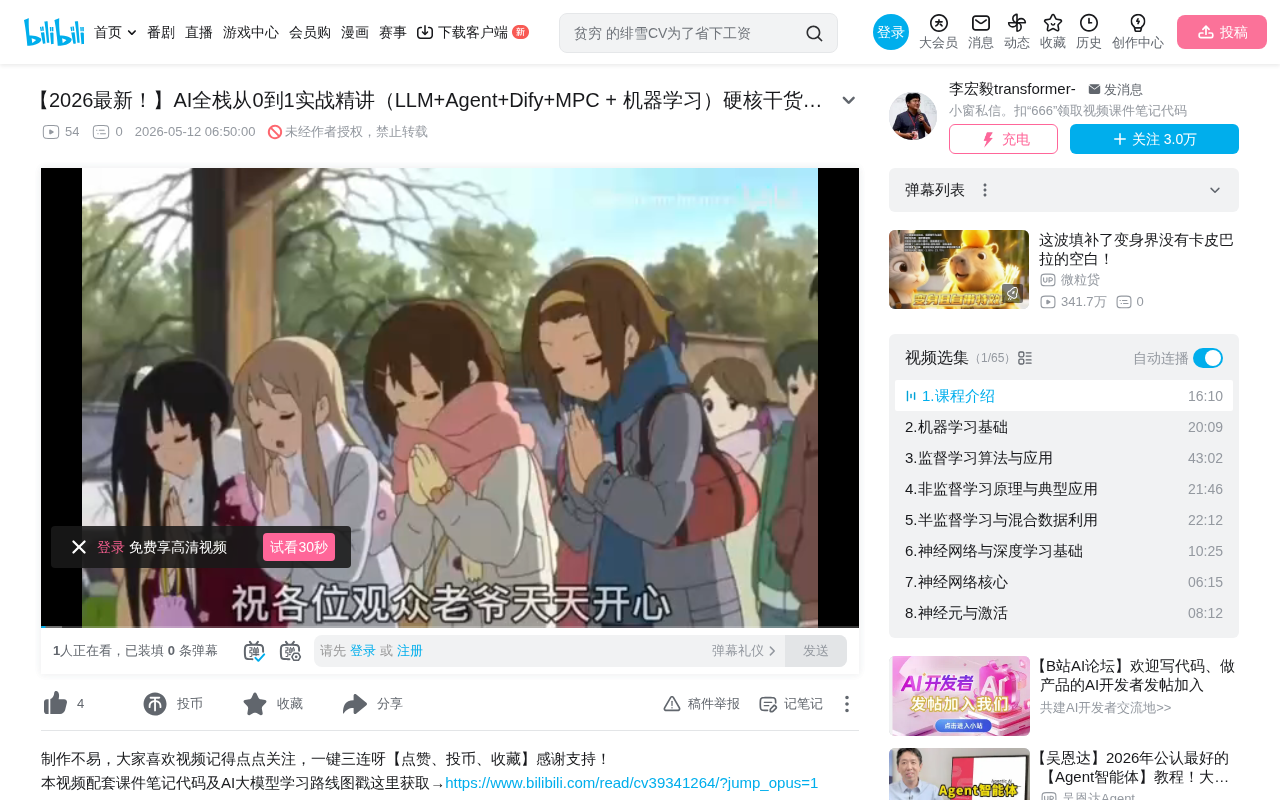
理解AI领域各概念之间的关系,是建立正确学习路径的前提。课程中展示了一张非常有价值的人工智能技术韦恩图。
从这张图可以看到几个关键关系:
- 人工智能是最大的概念范畴
- 神经网络的概念范围很大,深度学习是其中的一部分
- 深度学习与模式识别和机器学习存在交叉和覆盖
- 大数据、数据科学等领域与AI有关联但各有侧重
这种递进关系可以简化为:人工智能 > 机器学习 > 深度学习。从算法原理上讲,机器学习本质是一种从数据中自动学习规律的方法,深度学习是通过神经网络这种特定算法形态来实现学习,而大语言模型本质上也是一个深度神经网络——但从今天的发展来看,大模型的影响力已经远远超出了"深度学习"这个标签。
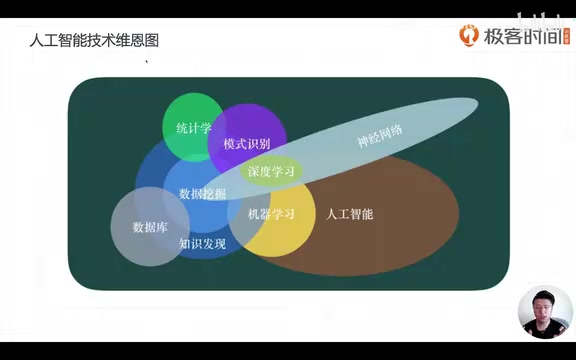
数据科学的三角交叉:数学、计算机与领域知识
课程中还展示了另一个重要的学科交叉视角,将相关领域分为三大支柱:
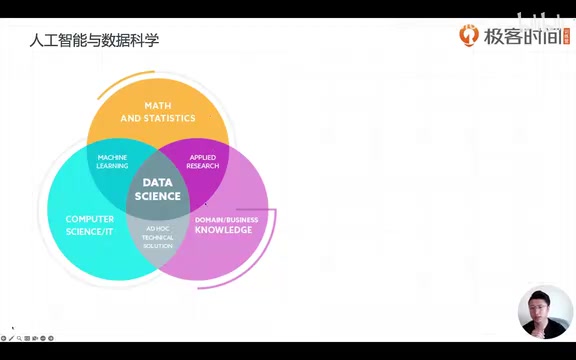
- 数学与统计——统计学能通过样本发现规律,是机器学习的数学基础
- 计算机科学/信息技术——提供算法实现和工程化能力
- 领域知识/商业知识——决定技术如何落地应用
机器学习恰好位于数学统计与计算机科学的交叉地带。这解释了为什么学习机器学习需要一定的数学基础(如求解优化问题),但又不完全等同于纯数学研究。
一个有趣的演进路径是:很多技术最初是作为ad hoc(临时性)的解决方案出现的——针对某个具体业务问题用计算机方式解决。当这些方案被发现可以横向扩展到其他场景时,就会逐步产品化,从解决方案变成产品,甚至发展为一个研究方向或学科。
技术名词的兴衰:从大数据到大模型
课程中提出了一个非常有洞察力的观点:技术名词的热度变化反映了技术发展的阶段。
2015年前后,"大数据"是最热门的词汇,由Google推动的Hadoop、MapReduce、Spark等技术让人们能够存储和处理互联网海量数据,催生了淘宝推荐算法等应用。
背景知识:大数据技术的历史脉络 Hadoop是Apache基金会开发的开源分布式计算框架,其核心思想来源于Google在2003-2004年发表的GFS和MapReduce论文。MapReduce将大规模数据处理分解为Map(映射)和Reduce(归约)两个阶段,使普通商用服务器集群也能处理PB级数据。后来Spark以内存计算替代磁盘I/O,将处理速度提升了数十倍。这一技术浪潮催生了数据工程师、数据分析师等职业,也为后来机器学习所需的大规模训练数据基础设施铺平了道路。如今这些技术已沉淀为数据仓库、数据湖等成熟的工程基础设施,不再是焦点,但其价值从未消失。
同样的规律也发生在深度学习领域。几年前TensorFlow、PyTorch是最火的框架,而现在焦点已经转移到基于它们之上的Hugging Face Transformers——因为后者直接面向大语言模型这个更新的技术层次。
背景知识:Hugging Face生态的崛起 Hugging Face是一家成立于2016年的AI公司,其开源库Transformers已成为NLP和大模型领域事实上的标准工具包。它提供了统一的API接口,封装了BERT、GPT、LLaMA、DeepSeek等数百种预训练模型,开发者无需从头实现复杂的Transformer架构,只需几行代码即可加载并使用最先进的模型。Hugging Face Hub作为模型托管平台,目前已有超过50万个公开模型,极大降低了大模型应用开发的门槛,也是当前AI全栈开发者必须熟悉的核心生态之一。
旧的技术名词不再被提及,但其内涵依然丰富,新技术中也能看到它们的影子。新技术就像能力雷达图,某个维度突破了,大家就以新名字来称呼它,而它所属的更大范畴因为不够精准就不再被强调。
这个观察对学习者的启示是:不必纠结于追逐每一个热门词汇,而要理解技术演进的内在逻辑。
前置篇的两节核心课程
第一课:机器学习与深度学习理论基础
重点内容包括:
- 机器学习三大类:监督学习、非监督学习、半监督学习
- 神经网络作为深度学习的原型
- 深度学习的演进:层数增加、优化算法改进、算力和数据的迭代
- 神经元与激活函数等核心概念
第二课:大模型发展全景与关键技术
聚焦Transformer架构:
- 从CNN、RNN等经典深度学习架构到Transformer的演进
- 注意力机制 → 自注意力机制 → 多头注意力机制
- 位置编码的引入
- 从2017年至今的技术迭代与突破
- DeepSeek的鲶鱼效应对研究方向的影响
背景知识:Transformer架构为何是革命性的 Transformer是2017年Google团队在论文《Attention Is All You Need》中提出的革命性架构。在此之前,序列建模任务主要依赖RNN(循环神经网络)和LSTM(长短期记忆网络),这些架构存在梯度消失和无法并行计算的固有缺陷。Transformer完全抛弃了循环结构,仅依靠注意力机制处理序列关系,不仅解决了长距离依赖问题,还极大提升了训练并行效率,为后续GPT、BERT、DeepSeek等大语言模型奠定了统一的架构基础。
注意力机制的核心原理:注意力机制最初用于解决机器翻译中的对齐问题——传统模型将整个输入句子压缩为固定长度的向量,导致长句信息丢失。注意力机制允许模型在生成每个输出词时,动态地"关注"输入序列中不同位置的词,赋予不同权重。自注意力(Self-Attention)进一步让序列内部的每个词都能与其他所有词计算关联度,捕捉句子内部的语义依赖。多头注意力(Multi-Head Attention)则并行运行多组注意力计算,从不同子空间捕捉多种语义关系,是Transformer性能强大的核心原因之一。
背景知识:DeepSeek的鲶鱼效应 DeepSeek是深度求索公司(总部位于杭州)于2023年底开始发布的系列大语言模型。2025年初,DeepSeek-R1以极低的训练成本(据报道约600万美元)达到了与OpenAI o1相当的推理能力,在全球AI社区引发强烈震动。其核心技术创新包括:混合专家架构(MoE)大幅降低推理计算量、强化学习驱动的推理链训练(GRPO算法),以及激进的模型蒸馏策略。DeepSeek的出现打破了"大模型必须依赖千亿美元算力投入"的认知,重新激活了学术界和开源社区对高效训练方法的研究热情,被称为对美国AI垄断格局的"鲶鱼效应"。

学习建议:概念优先,深度适度
课程反复强调的一个核心理念是:了解概念、知道它是什么、有什么用、为什么存在——这就够了。不需要在前置阶段就把机器学习和深度学习的所有理论推导一遍。
这种"螺旋式学习"的方法论值得借鉴:先建立概念框架,然后在实战中逐步深化理论理解——一部分实战、一部分理论,交替推进。对于想要转型AI全栈开发的工程师来说,这可能是最高效的学习路径:把有限的精力投入到理解核心概念和动手实践中,而不是在数学推导中消耗过多时间。
核心要点
- AI全栈开发学习路径:前置篇负责概念科普(机器学习、深度学习、Transformer),后续篇章以DeepSeek、Dify、MCP等技术门类展开实战
- 人工智能核心概念的递进关系:人工智能 > 机器学习 > 深度学习,大语言模型本质是深度神经网络但影响力已超越传统分类
- 技术名词的兴衰反映发展阶段:大数据、深度学习框架等热词逐渐被更上层的概念(如大语言模型、Transformers)所取代
- 学习方法论:采用螺旋式学习,概念理解优先于数学推导,实战与理论交替推进是最高效的转型路径
- Transformer架构是理解大模型的关键:从注意力机制到自注意力、多头注意力和位置编码,构成了现代大模型的技术基石
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。