AI数学建模万能提示词:零基础四阶段全流程实战指南
四阶段AI提示词体系助力零基础选手完成数学建模全流程
本文提出一套四阶段数学建模提示词体系,依次覆盖赛题分析、创新模型构建、数据获取预处理和模型求解四个环节,可解决90%以上数模题型。该体系通过限定算法改进、跨领域融合、多模型融合三种创新方向提升论文创新性,全程无需本地编程环境,零基础选手借助豆包等AI工具即可完成从分析到可视化的完整闭环。
引言
数学建模竞赛(如全国大学生数学建模竞赛CUMCM、美赛MCM/ICM)一直是理工科学生的重要赛事,要求参赛者在72至96小时内完成从问题分析到论文撰写的全流程,涵盖优化、预测、评价、仿真等多种题型。传统参赛路径需要选手具备微积分、线性代数、概率统计等数学基础,同时熟练掌握MATLAB、Python或R等编程工具,门槛极高。对于编程基础薄弱或建模经验不足的同学来说,从赛题分析到最终求解的全流程往往令人望而却步。
随着AI工具的成熟,提示词工程(Prompt Engineering)作为与大语言模型交互的核心技能,通过精心设计的指令结构,能够引导AI输出符合特定格式、逻辑和深度要求的内容,本质上是将领域专家的隐性知识显式化为可复用的指令模板。一套设计合理的提示词(Prompt)体系,已经能够覆盖数学建模90%以上的题型,实现从赛题分析、模型构建、代码求解到结果可视化的完整闭环。
本文将拆解一套"四阶段万能数模提示词"方法论,帮助零编程、零基础的同学也能借助AI高效完成数学建模全流程。
四阶段提示词体系总览
这套提示词体系将数学建模的完整流程拆分为四个阶段,每个阶段对应一组结构化的提示词,依次发送给AI即可逐步推进解题。
第一阶段:赛题深度分析
第一阶段的核心任务是理解题目。提示词会引导AI完成以下工作:
- 题目拆解:将赛题分解为多个子问题,明确每个子问题的直接目标和隐含目标
- 背景知识标注:识别题目涉及的领域知识、关键参数、约束条件
- 逻辑关系梳理:给出各子问题之间的逻辑递进关系,生成思维导图
这一步的价值在于,很多同学在比赛中失分并非模型不好,而是偏离了题目的核心要求。通过AI的结构化分析,可以快速锁定每个子问题的输出要求和核心要点,避免跑偏。
第二阶段:创新模型构建
第二阶段是整套体系的亮点——AI不会给出基础模型,而是限定三种创新方向来构建模型:
- 算法改进创新:在遗传算法、粒子群优化、模拟退火等经典算法基础上引入自适应参数、混合策略等改进,形成具有针对性的优化方案
- 跨领域交叉融合:借鉴物理学中的场论、生物学中的种群动力学或经济学中的博弈论等方法论,将不同学科的思路融合应用于当前问题
- 多模型融合创新:参考机器学习中成熟的Ensemble方法(如Stacking、Bagging、Boosting框架),组合多个模型形成新的解题框架,显著提升模型鲁棒性
对于每个子问题,AI会给出模型名称、原理说明、适配场景、创新点分析,以及与传统模型的对比优势。最终还会生成一张汇总表,清晰列出每个子问题对应的模型、解题思路和选模原因,并配合建模流程图。
这种设计直接解决了数模竞赛中"模型创新性不足"的痛点。数学建模竞赛的评分标准中,模型创新性通常占据重要权重,评委在阅卷时,一个有明确命名和理论依据的创新模型,往往比套用教材公式更能获得高分。这套提示词从源头上就引导AI往创新方向思考。
第三阶段:数据全自动获取与预处理
第三阶段处理数据问题,覆盖两种常见场景:
- 题目提供了数据:自动进行数据清洗,处理缺失值(均值/中位数填充、KNN插值、多重插补等)、异常值(IQR法则、Z-score或孤立森林算法检测)、量纲不一致(Min-Max归一化或Z-score标准化)等问题
- 题目未提供数据:自动从国家统计局、世界银行Open Data、UCI机器学习数据库、Kaggle等权威公开数据集中寻找合适的数据源,并明确数据来源
关键特性是不依赖本地数据上传和第三方工具。很多同学在使用AI建模时卡在本地路径设置、Python环境配置等技术细节上,这套提示词完全绕开了这些障碍。AI会直接生成完整的、可运行的数据处理代码(基于pandas、scikit-learn等主流库),并输出处理前后的对比图。
如果图片生成失败(这在AI工具中时有发生),只需要复制提示词中预设的提示语"图片生成失败请重新生成"发送给AI,即可重新获得结果图。
第四阶段:模型求解与结果分析
第四阶段是最终的求解环节,每个子问题的求解包含四个模块:
模块一:模型建立与公式推导
- 变量定义、假设条件说明
- 详细的公式推导过程(逐步展开)
- 建模流程图
模块二:模型求解
- 完整的求解步骤
- 可运行的源代码
- 竞赛级结果图(折线图、柱状图、热力图等,采用多巴胺配色方案)
模块三:模型检验
模型检验是数学建模论文中常被忽视但极为关键的环节。近年来国赛和美赛的评分细则均明确要求对模型的局限性和适用边界进行讨论,完整的检验体系是获得高分的必要条件:
- 有效性检验:采用交叉验证、留出法或与历史数据的拟合优度(R²、RMSE、MAE)对比
- 灵敏度分析:通过系统性改变模型参数,观察输出结果的变化幅度,评估模型对参数不确定性的鲁棒性,常用单因素分析、Morris筛选法和Sobol全局灵敏度分析等方法
- 对比度检验:将所建模型与基准模型(Baseline)进行横向比较,证明创新方案的优越性
模块四:结果分析
- 基于题目要求的数据分析
- 深度分析与拓展
- 能够直接回答问题的结论
使用时,每次只需将提示词中的子问题编号改为当前要解决的问题(如"问题一"改为"问题二"),即可逐个推进。
实战演示:不同题型的测试效果
在实际测试中,这套提示词分别在国赛C题和电工杯B题上进行了验证,涵盖了优化、预测、评价等不同题型。
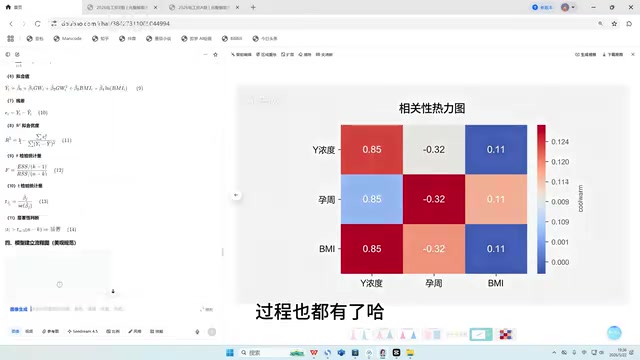
以国赛C题为例,AI在第二阶段为第一小问构建了"BMR运气双因子加权非线性相关模型(W2RN2)",模型名称本身就体现了较强的创新性。整个过程生成了完整的公式推导、可运行代码、热力图和相关性分析图,配色美观,符合竞赛论文的排版要求。
电工杯B题的测试同样顺利,AI针对需求预测类问题自动构建了多模型融合方案,数据预处理、可视化分析、模型检验等环节一气呵成。
使用建议与注意事项
推荐工具
全程使用豆包(基于云雀大模型)或DeepSeek(基于MoE架构)等国产AI工具即可,这两款工具在代码生成和数学推理方面已达到较高水准,能够支撑从公式推导到可视化代码的完整输出链路。无需借助MATLAB、Python本地环境或任何第三方平台,大大降低了使用门槛。
实操技巧
- 严格按阶段发送:四个阶段的提示词依次发送,不要跳步
- 图片生成失败时不要慌:直接要求AI重新生成即可
- 逐个子问题推进:第四阶段每次只处理一个子问题,完成后再改编号继续
- 配色可自定义:默认采用多巴胺配色,也可以在提示词中指定其他配色方案
局限性说明
虽然这套提示词覆盖面广,但仍需注意:
- AI生成的代码需要人工验证逻辑正确性
- 创新模型的理论严谨性需要自行把关
- 竞赛论文的写作润色仍需人工介入
- 对于极度复杂或前沿的赛题,可能需要额外的人工调整
总结
这套四阶段数模提示词体系,本质上是将数学建模的专家经验编码成了结构化的AI指令——这正是提示词工程中思维链提示(Chain-of-Thought, CoT)与角色扮演(Role Prompting)技术的综合应用,通过分阶段引导AI逐步推理,同时赋予AI"数学建模专家"的角色定位,使其输出更符合竞赛规范。它的核心价值不在于替代思考,而在于为零基础选手提供了一个完整的解题框架,让AI在每个环节都能输出高质量的中间结果。对于有经验的选手,它同样可以作为快速原型工具,大幅提升建模效率。
在AI工具日益普及的今天,掌握高质量的提示词工程能力,正在成为数学建模竞赛中新的核心竞争力——其地位已可与传统的编程能力和数学建模理论知识并列。
核心要点
- 四阶段提示词体系覆盖赛题分析、模型构建、数据处理、模型求解全流程,可解决90%以上数学建模题型
- 模型构建阶段限定三种创新方向(算法改进、跨领域融合、多模型融合),直接提升论文创新性评分
- 全程无需本地编程环境和第三方工具,零基础选手使用豆包等AI工具即可完成完整建模
- 第四阶段包含模型检验(灵敏度分析、对比度检验等),符合当前数模竞赛对模型验证的严格要求
- 图片生成失败时可通过预设提示语重新生成,输出结果采用多巴胺配色方案,达到竞赛级可视化标准
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。