AI图片变清晰实测:一键提升照片分辨率效果惊艳

AI图片变清晰技术让模糊照片一键恢复清晰,操作简单效果显著。
AI图片变清晰功能基于超分辨率重建技术,通过深度学习模型智能补充模糊图片中缺失的细节。用户只需导入照片、选择高清或超清档位、点击生成即可完成处理。实测显示,随手拍的模糊照片经处理后清晰度显著提升,细节还原效果明显。该功能适用于生活随拍、老照片修复、网络低质图片增强等场景,是普通用户无需专业技能即可使用的实用图片补救工具。
模糊照片的救星:AI图片变清晰功能
随手拍的照片因为光线不足、手抖或设备限制,画面模糊、细节丢失——这种情况几乎人人都遇到过。过去想提升这类照片的清晰度,往往需要Photoshop等专业软件和不少修图经验。而现在,AI图片变清晰技术让这件事变得异常简单:导入照片、点击按钮,模糊照片就能焕然一新。
本文通过一张实拍照片的处理全过程,带你了解AI变清晰功能的操作方法和真实效果。
AI变清晰功能详解
功能定位与适用场景
AI变清晰是图片处理工具中的核心功能之一,与抠图、批量水印、AI清除等功能并列,专门用于提升图片的清晰度和分辨率。它的目标非常明确——通过AI算法将模糊图片处理得更加清晰锐利。
这项功能最常见的使用场景包括:
- 随手拍的生活照片:聚会、吃饭时匆忙拍下的照片,画质往往不太理想
- 老照片修复:早期手机或相机拍摄的低分辨率照片,想要重新焕发生机
- 网络低质量图片增强:从社交媒体或网页保存的压缩图片,细节损失严重
- 小尺寸素材放大:原图尺寸太小,放大后像素模糊的图片
关于网络图片为何画质普遍较差,这里值得多说几句。JPEG格式采用有损压缩,通过离散余弦变换(DCT)将图像分成8×8像素块进行压缩,压缩率越高,块效应和色彩失真越明显。社交媒体平台(如微信、微博)在用户上传图片时还会进行二次压缩,一张原始5MB的照片可能被压缩到几百KB,大量细节在这个过程中被永久丢弃。此外,早期智能手机的CMOS传感器尺寸小、像素密度低,在弱光环境下信噪比极低,拍出的照片本身就缺乏细节。AI变清晰技术正是针对这些不同来源的画质损失,尝试从退化图像中恢复出尽可能接近原始场景的视觉信息。
操作流程:三步搞定
整个操作过程非常简洁,完全不需要修图基础:
- 进入功能:在图片处理模块中,点击"AI变清晰"选项
- 导入图片:选择需要处理的图片文件,支持JPG、PNG等常见格式
- 选择清晰度等级:系统提供"变高清"和"变超清"两个档位,按需选择
- 点击生成:确认后点击生成按钮,等待AI处理完成
- 查看对比效果:处理完成后可直接查看前后对比
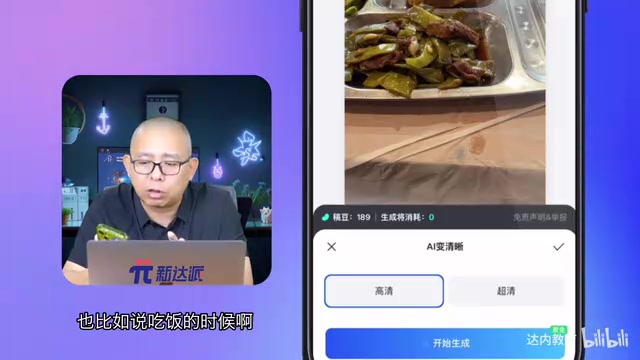
实测效果:模糊照片到底能变多清晰?
处理前后对比
这次测试用的是一张吃饭时随手拍的照片——这类照片最能代表日常"画质不够理想"的情况。经过AI变清晰处理后,提升效果肉眼可见:
- 整体画面:清晰度显著提升,分辨率明显变高
- 细节表现:放大查看后,原本模糊虚化的部分变得清晰锐利,食物纹理和餐具细节得到了很好的还原
- 视觉观感:从"比较虚"到"特别清晰",画质有明显的跃升感
高清与超清怎么选?
工具提供了"变高清"和"变超清"两个档位,实际使用中可以这样选择:
- 变高清:适合朋友圈分享、聊天发送等日常场景,处理速度较快,画质提升已经足够
- 变超清:适合打印输出、大屏展示或对画质要求较高的场景,分辨率提升幅度更大,但处理时间相应更长
从技术层面来看,这两个档位的差异不仅仅是"清晰一点"和"更清晰一点"。"变高清"一般对应2倍超分辨率(例如将1080×720提升至2160×1440),使用较轻量的模型,推理速度快。"变超清"则可能对应4倍甚至更高的放大倍率,使用参数量更大、层数更深的模型,能够恢复更精细的纹理和边缘信息,但计算量也成倍增加。值得注意的是,放大倍率越高,AI需要"推测"的信息就越多,生成的细节中也可能包含更多模型"想象"出来的内容(即所谓的"幻觉现象"),因此并非倍率越高越好,需要根据实际用途权衡。
建议根据实际用途选择档位,日常分享选高清就够用,需要高质量输出再上超清。
AI变清晰背后的技术原理
AI变清晰功能的核心技术是超分辨率重建(Super-Resolution)。这项技术通过深度学习模型,在海量高清与低清图片对中学习映射关系,从而在低分辨率图片的基础上智能"推测"并补充缺失的细节。
超分辨率重建是计算机视觉领域的经典问题之一,最早可追溯到上世纪60年代的信号处理研究。早期方法依赖双线性插值、双三次插值等数学算法,只能机械地填充像素,无法真正恢复丢失的高频细节。2014年,香港中文大学的研究团队提出了SRCNN(Super-Resolution Convolutional Neural Network),首次将深度学习引入超分辨率领域,开启了AI驱动图像增强的新时代。此后,ESRGAN、Real-ESRGAN、SwinIR等模型不断迭代,处理效果从实验室走向了消费级应用。现代超分辨率模型通常采用生成对抗网络(GAN)架构,其中生成器负责从低分辨率图像推测高分辨率细节,判别器则负责评判生成结果是否足够逼真,两者在对抗训练中不断提升效果。
与传统的图片放大方式(简单插值算法)相比,AI超分辨率技术的优势在于:不仅增加像素数量,还能智能还原边缘轮廓、纹理信息,甚至在一定程度上去除噪点和运动模糊,让处理后的图片看起来自然且清晰,而不是简单地"放大了但还是糊"。
要理解这种本质差异,可以这样类比:传统插值算法相当于把一幅马赛克画放大——每个色块变大了,但画面并没有变清晰。而AI超分辨率方法则不同,模型在训练阶段已经从数百万张图片中学习了"低分辨率特征→高分辨率细节"的映射规律。例如,模型见过大量清晰的毛发、文字、建筑纹理后,当遇到模糊的类似区域时,能够基于学到的先验知识"脑补"出合理的高频细节。这就是为什么AI处理后的图片不仅尺寸更大,而且看起来确实更清晰、更自然。
总结:值得一试的图片补救工具
AI图片变清晰功能为普通用户提供了一个极其便捷的照片增强方案。不需要学Photoshop,不需要懂修图技巧,选好照片、点击生成,就能获得明显的画质提升。
对于手机里那些"凑合能看"的随手拍、年代久远的老照片、或者从网上保存的低质量图片,这项功能都是一个实用的补救手段。随着AI图像处理技术的持续进步,这类工具的效果和处理速度还会进一步提升,值得持续关注。
核心要点
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。