AI项目评测体系:5大层级30项指标实战指南

AI大模型产品落地的五层三十项评测指标体系
本文提出一套系统化的AI产品评测框架,涵盖模型质量层、用户体验层、系统效率层、业务价值层和数据闭环层五个层级共30项指标。框架回答了AI够不够聪明、够不够便宜、能不能赚钱并持续进化三大核心问题,强调量化是优化的前提,迭代速度才是AI时代的真正壁垒。
当企业真正把大模型Agent项目推向落地,一个绕不开的核心问题浮出水面:如何科学评估AI产品的表现? 无论你是产品负责人、架构师还是产品经理,都需要一套系统化的评测框架来量化产出、驱动优化。
本文基于实战经验,梳理出一套从技术到商业的完整评测体系——5大层级、30项指标,帮你全面把控AI项目的质量与价值。
量化是优化的前提:AI评测的底层逻辑
评测的第一要务是量化。只有将AI产品的表现转化为可衡量的数值,才能找到优化方向。没有量化,就没有优化。
一个成功的AI项目需要跨越三大挑战:
- 准确度挑战:AI产品本身要靠谱,能为用户提供真正有价值的帮助
- 成本挑战:AI的边际成本远高于传统互联网产品,Token消耗是实实在在的开支
- 生存挑战:产品需要持续迭代优化,敏捷开发能力至关重要
这三点构成了AI项目评测的底层逻辑。与互联网产品几乎为零的边际成本不同,AI产品每一次调用都在消耗算力资源,这决定了我们必须同时关注质量和效率。
五层评测框架总览
整个评测体系分为五个层级,分别对应不同的能力维度:
| 层级 | 核心能力 | 中级目标 |
|---|---|---|
| 模型质量层 | 算法能力 | 让AI足够聪明 |
| 用户体验层 | 产品能力 | 让AI好用易用 |
| 系统效率层 | 工程能力 | 让AI便宜且快速 |
| 业务价值层 | 商业能力 | 让AI能够赚钱 |
| 数据闭环层 | 迭代能力 | 让AI自我进化 |
接下来逐层拆解每个层级的核心指标。
第一层:模型质量层——地基决定高度
模型质量是产品的地基。算法能力不够,后面的一切都是空中楼阁。
解决率
AI独立解决用户问题的比例。客服场景的经验数值为60%-80%,复杂业务场景约30%-50%。不要对AI抱有不切实际的期望——95%的解决率在当前技术条件下并不现实。
幻觉率与空答率
这是一对典型的"跷跷板"指标:
- 幻觉率:AI虚构答案的比例。通用对话场景不超过15%,垂直领域(如报价、合同等)不能超过1%
- 空答率:AI回答"不知道"的比例。偏保守策略,拿不准就不答
两者本质上都源于模型缺乏相关知识。通过RAG加载外部知识库,可以同时降低这两个指标。但在外部知识固定的情况下,它们呈此消彼长的关系——降低幻觉率往往意味着空答率上升,反之亦然。
意图识别准确率
在智能体架构中,用户输入需要被路由到正确的子系统(如查快递、退款、查天气等)。意图识别准确率一般在85%-95%之间。它是整个链路的起点——如果这一步错了,后面全部白搭。
RAG系统的两个关键指标
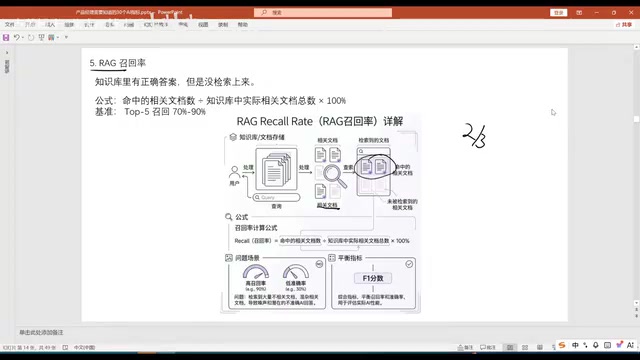
RAG(检索增强生成)系统有两个核心指标需要重点关注:
- 召回率:知识库中相关文档被检索出来的比例。召回率必须优先保证,因为没召回的知识在后续环节无法弥补
- 事实一致性:正确文档被召回后,模型能否基于文档给出正确答案。要求85%以上,否则需要考虑更换更强的基座模型
实战中有一条重要原则:发现回答不对时,不要盲目换模型。先分析是召回没做好,还是召回了但模型理解不了,再有针对性地优化。
第二层:用户体验层——用户感知的好与坏
如果说模型质量是藏在地下的地基,用户体验就是房子的外观——用户直接感知到的部分。
首轮满意度
一轮回答就解决问题的比例。优秀产品要大于65%,及格线为45%。反复交互不仅伤害用户体验,还会大幅增加Token成本。
转人工率
用户咨询转给人工客服的比例,15%-30%属于可接受范围。
这里有一个常见陷阱:不要为了降低转人工率而隐藏转人工入口。表面上数据好看了,实际上用户可能直接流失。转人工率不是负面指标——在AI起步阶段,回答不了的问题不要硬答,更不要误导用户。
任务完成率与代码采纳率
- 任务完成率:智能体发起的主动任务(如填表、报销等)最终完成的比例,一般要大于40%
- 代码采纳率:AI生成代码被程序员接受的比例,目前行业水平约30%。你可能没注意到,采纳率异常高未必是好事,可能是开发者不加甄别地全盘接受
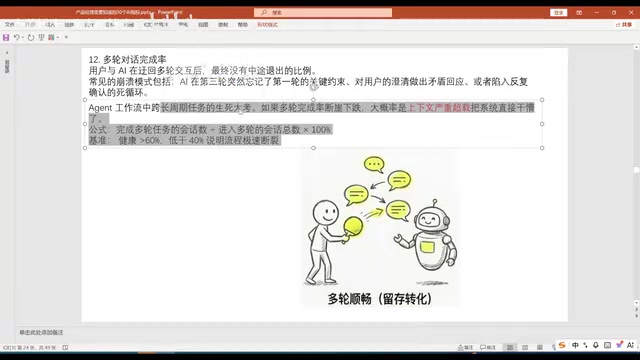
多轮对话完成率
单轮未解决时进入多轮对话,最大挑战是上下文窗口截断。随着对话轮次增加,上下文变长,意图容易发生漂移。一般要求大于60%。
第三层:系统效率层——Token花在刀刃上
这一层决定了你解决每个问题的成本有多高,也是AI产品与传统互联网产品最本质的区别。
Token成本控制的四种手段
- 精简提示词:不要写太长的系统提示词(这也是Cursor等产品烧钱的重要原因)
- KV Cache缓存:固定的头部提示词可以缓存复用,避免重复计算
- 模型分级调用:小模型够用就不上大模型,简单问题不必动用最强算力
- 上下文管理:压缩不必要的历史对话,减少冗余Token
响应速度指标
- TTFT(Time to First Token):生成第一个Token的时间,直接影响用户的等待体验
- 端到端延迟:从第一个Token到最后一个Token的总耗时。在智能体场景中,工具调用可能显著增加延迟,可通过并行调用来优化
Token使用效率
一个容易被忽视的指标。如果用户问题只有50个Token,答案200个Token,但大量Token消耗在冗余的提示词和不精准的RAG召回上,实际有效Token占比就很低。优化方向很明确:精简提示词 + 提高RAG检索准确率。
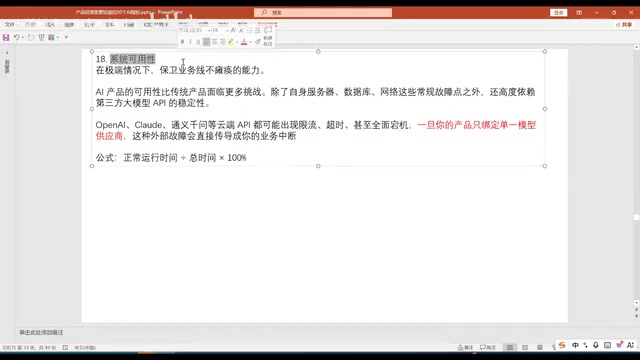
系统可用性与多供应商策略
不要只绑定一个模型供应商。外部API可能出现超时、降级甚至宕机。产品架构应支持多供应商切换,避免被单一供应商"卡脖子"。同时,尽量让系统具备通用性,不要在某个模型上过度精调导致迁移困难。
第四层:业务价值层——能赚钱才是硬道理
技术指标再漂亮,最终还是要回到商业价值上。
AI功能采纳率
关键看重复使用率——首次使用后7天内再次使用的比例。很多用户只是好奇点一下就再也不用了,这种"尝鲜"不算真正的采纳。
单位解决成本
解决一个问题的AI成本 vs 人工成本。这里有一个生动的类比:印度至今很多人用手洗衣服,因为人工成本极低,买洗衣机反而不划算。AI在中国和美国发展迅速,很大原因是人力成本持续走高,AI替代的经济账算得过来。
LTV/CAC比值
与互联网产品不同,AI产品计算用户生命周期价值(LTV)时必须扣除算力成本。这也解释了为什么一些AI产品会克制用户增长——用户越多,未必越赚钱。
模型ROI
分子是AI带来的所有可量化收益(营收增长、人力降本、效率提升),分母是全口径投入(模型训练、API调用、基础设施、数据标注等)。ROI低于100%意味着做一单亏一单,商业模式不可持续。
第五层:数据闭环层——持续进化的引擎
这一层决定了产品的长期生命力,核心是迭代速度。
反馈回流率
用户差评和反馈中,能够被修正的比例。产品必须建立完整的闭环:反馈收集 → 数据清洗 → 问题归因 → 修复上线。
Bug归因能力
AI系统链路较长,出错后必须精准定位问题出在哪里:是提示词写得有问题?是RAG检索出了偏差?还是模型本身的能力不足?归因准确才能有效改进。
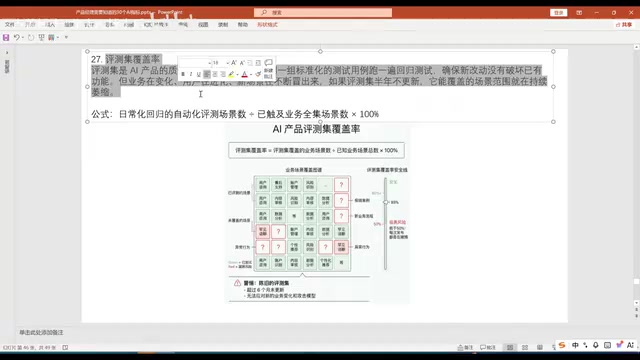
评测集覆盖度
评测集必须覆盖极端案例和罕见场景,否则容易出现"评测时指标很高,一上线就崩"的尴尬局面。
模型漂移监控
一个容易被忽视的问题:产品什么都没动,效果却越来越差。原因可能是:
- 客观知识在更新,但RAG知识库数据没有同步
- 供应商默默更新了模型版本,甚至出于成本考虑进行了模型降智
必须建立持续监控机制,发现指标缓慢下滑时及时排查根因。
置信度校准
大模型普遍存在过度自信的问题——只要会一点就不谦虚,"吹牛"是发自内心的。必须通过提示词工程和校准策略,让模型对自身能力有准确评估,不确定的就明确告知用户,而不是编造答案。
总结:迭代速度才是AI时代的真正壁垒
这套5层30指标的评测体系,本质上回答了三个问题:
- AI够不够聪明?(模型质量层 + 用户体验层)
- AI够不够便宜?(系统效率层)
- AI能不能赚钱并持续进化?(业务价值层 + 数据闭环层)
在AI时代,真正的壁垒可能不是技术壁垒,也不是产品壁垒,而是迭代速度。如果你的团队转一圈要三个月,三个月后竞品的新版本可能已经上线了。所有的技术都有保质期,而在AI领域,这个保质期只会更短。
建议每个AI团队根据自身业务阶段,从这30项指标中选择最关键的10-15项作为核心看板,定期review,用数据驱动每一次迭代决策。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。