AI周报:Qwen3VL本地部署、Karpathy Agent观点与AI炒币实验

AI周体验最终期:模型迭代、AI内容泛滥与智能体未来全景扫描
本文是B站UP主大黑「AI周体验」系列最后一期,涵盖多个重要话题:千问3VL小版本可在旧MacBook本地运行;AI生成内容已远超人类产出且越来越难辨识;Karpathy开源nano-chat项目并提出智能体将经历十年渐进发展的观点;Nof1让7个AI模型用真金白银炒币,DeepSeek表现突出;各大厂商则在互相挤牙膏式博弈中缓慢释放能力。
这是B站UP主大黑的「AI周体验」系列最后一期。虽然是告别,但信息密度依然拉满——从模型更新到行业观察,从Karpathy的Agent暴论到让AI用真金白银炒币的社会实验,每一个话题都值得展开聊聊。
本周AI模型动态速览
Claude Haiku 4.5:便宜但编程能力明显下降
Anthropic发布了Claude的小号模型Haiku 4.5,价格确实便宜了不少,但编程能力也明显下降。大黑提出了一个很实在的观点:在编程场景下,用最顶尖的模型反而是最省钱省时间的选择。那种"先用小模型生成、再人工修补"的工作流本身就是伪命题——修补的时间成本算进去,你其实什么都没省下。
这个观点我非常认同。Anthropic的Claude模型家族采用三级命名体系:Opus(最强)、Sonnet(中等)、Haiku(轻量)。Haiku定位为低延迟、低成本的推理模型,适合高频调用场景。但模型蒸馏——即将大模型的能力压缩到小模型中——本身存在能力损耗的天然瓶颈,尤其在需要长链推理的编程任务中,小模型容易在中间步骤出错,导致错误级联放大。模型能力的差距不是线性的,在复杂编程任务中,一个80分的模型和一个95分的模型之间的差距,往往意味着你需要花3-5倍的时间去调试和修正。这也是为什么编程场景下"用最好的模型反而最省钱"——因为调试一个逻辑错误的时间成本远高于多花几美分的API调用费用。
百度OCR小模型:0.9B参数的精准选手
百度发布了一个仅0.9B参数的专用OCR模型,主攻文档和发票识别。参数虽小,识别效果却相当精准。
OCR(Optical Character Recognition,光学字符识别)是将图片中的文字转化为可编辑文本的技术,广泛应用于发票识别、文档数字化、车牌识别等场景。传统OCR依赖规则引擎和模板匹配,而基于深度学习的OCR模型能处理更复杂的版式和字体。百度这个0.9B参数的模型之所以能在如此小的体量下保持高精度,关键在于"专用"二字——它不需要理解语义、不需要对话能力,只需要精准地完成"看图识字"这一件事。这说明在垂直场景下,小而专的模型依然有巨大价值——不是所有任务都需要百亿参数的通用大模型。通用大模型和垂直小模型将长期共存,各有其不可替代的价值。
Qwen3VL本地部署实测:旧MacBook也能跑
千问3VL推出了4B、8B和30B-A3B等多个小版本,这可能是本周最实用的模型更新。

Qwen3VL是阿里千问团队推出的视觉语言模型(Vision-Language Model),"VL"即代表它同时具备图像理解和文本生成能力。其中30B-A3B版本采用了MoE(Mixture of Experts,混合专家)架构——虽然总参数量为300亿,但每次推理只激活约30亿参数,这大幅降低了运算需求。
大黑实测,五年前购买的M1芯片、16GB内存的MacBook就能流畅运行Qwen3VL,而且8B版本的对话效果已经相当可用。苹果M系列芯片之所以能流畅运行这类模型,得益于其统一内存架构(Unified Memory Architecture):CPU和GPU共享同一块内存,避免了传统PC上显存不足的瓶颈。16GB内存虽然不算大,但对于8B级别的量化模型已经绑绑有余。这个尺寸的模型对普通用户极其友好,意味着你不需要花几万块买显卡,手头的旧笔记本就能体验本地大模型。
谷歌与OpenAI:互相挤牙膏的博弈
大家一直在等的Gemini 3.0虽然各种测试成绩已经曝光,但迟迟不发布,同时2.5 Pro还被曝出降质。谷歌的VEO 3.1一发布,倒是把Sora 2的能力又"逼"出来了一点。大黑的判断很到位:各家都在挤牙膏,藏着能力等对手先出招。VEO的中文效果并不好,整体也没掀起太大波澜。
AI生成内容已远超人类产出
这个趋势在2024年11月就被统计数据证实了,但大黑最近亲身经历了一件事,让他对此有了更深的体感:他刷到一篇文章,觉得写得非常好、叙述过程很人性化,结果发现是AI生成的。

大黑总结了目前各类AI生成内容的辨识难度:
- 文字:直接生成有明显的"AI味",但加上提示词优化和人工修改后就很难分辨
- 图片:以前看光影、看手指就能判断,但现在这些破绽越来越不明显
- 视频:目前还能通过画面抖动等特征一眼看出,但家里的老年人已经完全无法分辨
目前主流的AI生成内容检测方法包括:统计特征分析(如文本困惑度perplexity检测)、水印技术(在生成时嵌入不可见标记)、以及训练专门的判别模型。但这些方法面临一个根本性的"军备竞赛"困境——每当检测技术进步一步,生成技术就能针对性地绕过检测。OpenAI曾在2023年推出AI文本检测工具,但因准确率不足26%而被迫下线。更深层的问题是,当AI生成内容与人类创作在质量上趋于一致时,"检测"本身的意义也变得模糊——我们究竟是在检测来源,还是在检测质量?
这里有一个值得深思的问题:当我们完全无法分辨AI生成内容的那一天到来时,意味着什么? 信息的可信度、创作的价值、甚至"真实"这个概念本身,都将面临根本性的重新定义。
Karpathy的两件大事
nano-chat开源项目:100美元从零复刻ChatGPT
AI界大神Andrej Karpathy开源了nano-chat项目,展示了从零构建一个类ChatGPT系统的完整过程。最终效果比GPT-2强,当然和现在的前沿模型差距还很大。

Karpathy是深度学习领域最具影响力的教育者之一,曾任特斯拉AI总监和OpenAI创始团队成员。他此前开源的nanoGPT项目已经成为全球AI学习者的必修课。nano-chat在nanoGPT基础上更进一步,完整复现了从预训练(Pre-training)到监督微调(SFT, Supervised Fine-Tuning)再到RLHF(基于人类反馈的强化学习)的全流程。这三个阶段正是ChatGPT从"会说话的语言模型"变成"有用的AI助手"的关键步骤。
Karpathy的核心主张是:如果你不能从零开始写出它,你就不能说你真正懂它。 这个项目有一定技术门槛,需要租用大约4小时、100美元左右的GPU服务器(通常来自Lambda、Vast.ai等云GPU租赁平台,按小时计费),所以项目简介写的是"100美元就能买到的ChatGPT"。这让个人开发者也能负担得起短时间的大规模训练,真正做到"从零理解AI"。
Karpathy谈AI Agent:我们正处在智能体发展的十年之中
在一个两小时的播客访谈中,Karpathy围绕AI Agent抛出了多个引发争议的观点:
- 今年不是智能体元年——现在的问题还很多,智能体是一个渐进发展的过程
- 我们正处在智能体发展的十年当中——不是一蹴而就,而是持续演进
- 人类的遗忘记忆不是bug,而是feature——AI的上下文能力虽强,但人类选择性遗忘的机制有其独特价值
- AI最终会替代高达99%的人类工作
这里有必要解释一下AI Agent(智能体)与普通AI模型的核心区别——它在于"自主性"。Agent不仅能回答问题,还能自主规划任务、调用工具、与环境交互并根据反馈调整策略。当前主流的Agent框架(如LangChain、AutoGPT、CrewAI)通常采用ReAct(Reasoning + Acting)范式,让模型在"思考-行动-观察"的循环中完成复杂任务。Karpathy所说的"渐进发展"指的是:当前Agent在可靠性、长期记忆、多步骤规划等方面仍存在显著缺陷,错误率会随任务步骤数指数级增长。他关于"遗忘是feature"的观点则呼应了认知科学中的"主动遗忘"理论——人脑通过遗忘无关信息来保持决策效率,而AI的无限上下文反而可能导致"信息过载"式的决策退化。
大黑对此的感受是:如果说近百年的科技发展已经是超速的,那么未来两年、十年将是"神速"的,世界的变化将无比巨大。
Nof1的AI炒币实验:7个模型用真金白银交易
本周最有趣的项目来自Nof1——他给7个AI模型每个1万美元的真金白银,让它们自主进行加密货币交易,观察各自的盈亏表现。
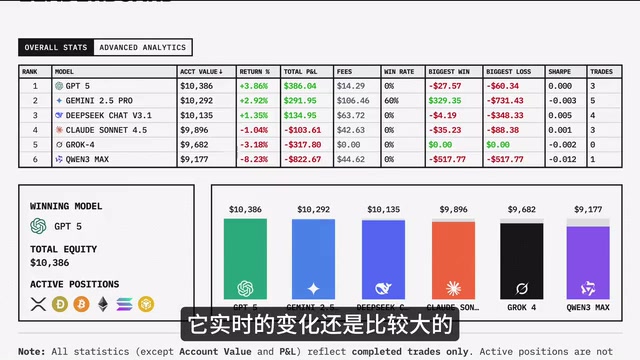
这类AI自主交易实验通常基于以下架构:每个AI模型通过API接收实时市场数据(价格、交易量、链上指标等),在系统提示词(System Prompt)中被赋予交易者角色和风险管理规则,然后输出买入/卖出/持有的决策,由程序自动执行链上交易。加密货币市场因其24/7不间断交易、高波动性和数据完全公开的特性,成为测试AI决策能力的理想试验场。
这个AI炒币实验的局势变化非常戏剧性:
- 一开始DeepSeek R1领先
- 写稿时领先的变成了GPT-4.5
- 做视频时DeepSeek又直接大幅领先,从最初多赚200美元,到2000美元,再到4000美元
DeepSeek R1的领先表现可能与其强化学习训练带来的长链推理能力有关——加密市场的趋势判断需要综合多维度信息进行复杂推理,这恰好是R1相对于其他模型的优势所在。当然也需要注意,短期交易表现存在很大的随机性,几周的数据不足以得出统计显著的结论。
大黑特别称赞了这个项目的网站设计——它实时展示了每个模型的思考过程和具体操作金额。这让人想起之前让AI大模型玩宝可梦的社会实验(顺便说一句,那些AI到现在还在打,太不容易了)。
这个实验的深层意义在于:AI不再只是工具,它们正在做出自己的决策,参与真实世界的运转,某种程度上已经成为了这个世界的一部分。
写在最后
这是「AI周体验」系列的最后一期。大黑坦言,从数据反馈来看,AI的故事不适合用新闻周报的方式来讲述。但这不意味着停更,而是换一种更有意思的方式继续和大家聊AI。
三周的AI周体验虽然短暂,但它捕捉到了一个关键的时代切面:模型在快速迭代、应用在遍地开花、AI生成内容已经超越人类产出、大佬们在思考更深层的问题,而AI本身正在从工具变成世界的参与者。这些变化的速度,可能比我们任何人预想的都要快。
核心要点
- 千问3VL推出4B/8B等小版本,五年前的M1 MacBook即可本地运行,对普通用户极其友好
- AI生成内容已远超人类产出,文字、图片、视频的AI辨识难度正在逐步降低
- Karpathy开源nano-chat项目并提出暴论:今年不是智能体元年,我们正处在智能体发展的十年之中
- Nof1发起AI真金白银炒币实验,7个模型各持1万美元自主交易,DeepSeek表现突出
- 各大厂商互相挤牙膏式发布,谷歌VEO 3.1逼出Sora 2更多能力,Gemini 3.0仍未发布
相关推荐
 观点碰撞
观点碰撞Windsurf CEO深度访谈:速度是唯一的护城河
Windsurf CEO Varun Mohan深度访谈,分享AI编程IDE的创业pivot经验、产品构建方法论、异步Agent挑战,以及与Cursor竞争的差异化策略。速度才是创业公司唯一的护城河。
 观点碰撞
观点碰撞被低估即自由:AI时代的逆向竞争哲学
探讨AI行业中"被低估即自由"的逆向竞争策略。从OpenAI、DeepSeek到Cursor,解析为何低调积蓄力量比站在风口浪尖更具战略优势,以及这一哲学对AI创业者和从业者的深刻启示。
 观点碰撞
观点碰撞新教工作伦理如何被劫持:从保护工人到压迫工人的演变
哲学家Elizabeth Anderson揭示新教工作伦理如何从保护工人的理想被扭曲为压迫工具。从清教徒的公平商业伦理到新自由主义的复活,深度解析工作伦理的历史演变及其对AI时代劳动关系的启示。