AI自动审查成为默认机制:97%准确率的子代理分类器如何工作
核心动态:自动审查机制全面上线
AI工具领域迎来一项重要的安全机制更新——自动审查(Auto-review)现已成为所有新用户的默认设置。这意味着用户在使用AI代理执行操作时,系统会自动对每个动作进行安全评估,无需手动开启。
这项功能的核心是一个分类器子代理(classifier subagent),它在上下文中审查AI代理的每一个操作,然后做出三种决策之一:允许执行、阻止执行、或请求用户批准。分类器子代理是一种嵌套式AI架构,其核心思想是在主AI代理的执行链路中插入一个独立的、专门负责安全评估的AI模型。这种架构借鉴了操作系统中"特权分离(privilege separation)"的设计理念——执行操作的代理和审查操作的代理各自独立运行,避免单一模型既当运动员又当裁判员。在技术实现上,分类器子代理通常会接收主代理当前的完整上下文窗口(包括用户指令、对话历史、待执行的具体操作),然后基于安全策略进行推理判断。与传统的静态规则引擎(如正则表达式匹配或黑白名单过滤)相比,基于大语言模型的分类器能够理解自然语言的语义和意图,从而在面对措辞变化、隐含指令等复杂情况时表现出更强的鲁棒性。
技术实现:上下文感知的三级决策
分类器子代理的工作原理
与简单的规则过滤不同,这个分类器子代理具备上下文理解能力。它不是机械地匹配关键词或预设规则,而是在理解当前操作的完整语境后做出判断。这种设计使其能够区分看似相似但意图完全不同的操作。
上下文感知是区分现代AI安全机制与传统安全过滤器的关键特征。传统的内容过滤系统通常采用无状态(stateless)的方式工作——它们逐条检查输入或输出,不考虑前后文关系。例如,一个简单的关键词过滤器可能会将包含"删除所有文件"的指令一律拦截,但在上下文中这可能是用户明确要求清理临时缓存的合理操作。上下文感知的分类器则会综合考虑用户的历史指令、当前工作目录、操作对象的敏感程度等多维信息,做出更精准的判断。这种能力在AI代理场景中尤为重要,因为代理往往需要执行多步骤的复合任务,单独审视某一步操作可能完全无法判断其安全性,只有放在完整的任务链条中才能做出合理评估。
三级决策机制的设计颇具巧思:
- 允许(Allow):明确安全的操作直接放行,不打断用户工作流
- 阻止(Block):明确危险的操作直接拦截,防止潜在风险
- 请求批准(Ask for approval):处于灰色地带的操作交由用户判断
这种分层处理既保证了安全性,又最大限度地减少了对用户体验的干扰。
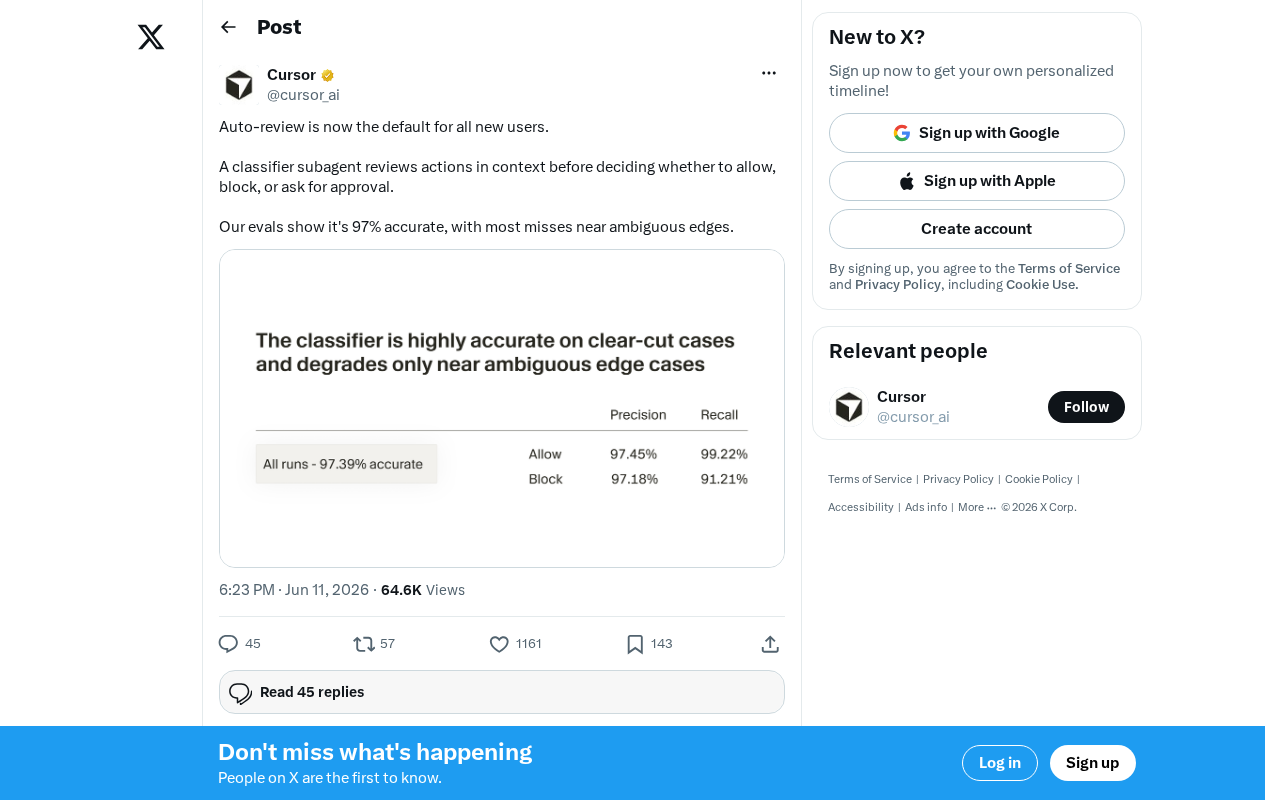
97%准确率与模糊边界分析
根据官方评估数据,该分类器的准确率达到97%。官方也坦诚指出,大多数误判发生在"模糊边界(ambiguous edges)"附近——即那些本身就难以明确归类为安全或危险的操作。
在机器学习分类任务中,97%的准确率需要结合具体场景来评估其实际意义。对于安全分类器而言,更关键的指标往往是精确率(Precision)和召回率(Recall)的平衡——即误报率(将安全操作判为危险)和漏报率(将危险操作判为安全)各占多少。在安全领域,漏报的代价通常远高于误报。作为参考,主流邮件系统的垃圾邮件过滤器准确率通常在99%以上,但其面对的分类任务相对单一。AI代理的操作审查面临的语义空间远比垃圾邮件分类复杂,因此97%的准确率在当前技术水平下已属较高水准。值得注意的是,官方特别提到误判集中在"模糊边界",这暗示分类器在明确安全和明确危险的操作上表现可能远超97%,而不确定区域的准确率则显著低于这一数字。
97%的准确率意味着每100次判断中大约有3次可能出现偏差。对于高频使用场景,这个误差率是否可接受,取决于具体的使用场景和风险容忍度。
行业意义:AI代理安全的新范式
从被动防御到主动审查
这一机制的推出反映了AI代理安全领域的一个重要趋势:安全机制正在从用户主动配置转向系统默认启用。将自动审查设为默认选项,体现了"安全优先(security by default)"的设计哲学。
"安全优先"并非AI领域的新概念,它在软件工程和网络安全领域有着深厚的历史根基。这一理念最早可追溯到Saltzer和Schroeder在1975年提出的"故障安全默认值(fail-safe defaults)"原则——系统的默认状态应该是拒绝访问,而非允许访问。在实践中,微软在2002年发起的"可信计算(Trustworthy Computing)"倡议是这一理念的标志性事件,此后Windows系统默认开启防火墙、浏览器默认启用安全沙箱等做法逐渐成为行业标准。在AI代理领域采用这一原则意味着,安全机制不再依赖用户的主动配置意识,而是将保护内置为产品的出厂状态,这对于降低因用户疏忽导致的安全事故具有重要意义。
子代理监督模式的兴起
用一个AI来监督另一个AI的行为,这种"子代理监督"模式正在成为AI安全领域的重要方向。相比传统的规则引擎,基于AI的审查系统具有更强的泛化能力和上下文理解力,能够应对更复杂的场景。
这一思路与AI对齐(AI Alignment)研究中的多个前沿方向密切相关。OpenAI提出的"可扩展监督(Scalable Oversight)"框架认为,随着AI系统能力的增强,人类直接监督每一个AI决策将变得不可行,因此需要借助AI辅助来实现监督的规模化。Anthropic则提出了"宪法AI(Constitutional AI)"方法,通过让一个AI模型根据预设原则来评估和修正另一个AI模型的输出。此外,"辩论(Debate)"机制让两个AI模型相互质疑对方的推理过程,以暴露潜在的错误或风险。自动审查中的分类器子代理可以视为这些理论框架在工程实践中的一种落地形式——它将抽象的对齐目标转化为具体的、可部署的安全审查流程。
自动审查面临的潜在挑战
这种方法也面临一些值得关注的问题:
- 性能开销:每次操作都需要经过分类器审查,可能增加响应延迟
- 误报疲劳:3%的误差在高频场景下可能导致用户频繁被打断
- 对抗性攻击:分类器本身是否可能被精心构造的输入绕过或欺骗
- 决策透明度:用户是否能清晰理解某个操作被阻止的具体原因
其中,对抗性攻击(Adversarial Attack)的威胁尤其值得深入关注。在AI安全分类器的场景中,这类攻击可能表现为多种形式:提示注入(Prompt Injection)通过在用户输入中嵌入特殊指令来操纵分类器的判断;间接提示注入(Indirect Prompt Injection)则通过外部数据源(如网页内容、文档)向AI代理注入恶意指令,而分类器可能因为这些指令看似来自合法数据源而未能识别。此外,还存在"渐进式越狱(Gradual Jailbreaking)"的风险——攻击者通过一系列看似无害的小步骤逐步引导AI代理执行危险操作,每一步都可能通过分类器的审查,但组合起来却构成安全威胁。这些挑战使得AI安全审查成为一个持续的攻防博弈过程,而非一劳永逸的解决方案。
总结:安全护栏与用户体验的平衡
自动审查机制的默认化是AI代理走向成熟的标志之一。97%的准确率虽然不完美,但在"模糊边界"处的坦诚态度值得肯定。随着AI代理能力的不断增强,这类安全护栏的重要性只会越来越高。未来的关键在于如何在安全性和用户体验之间找到最佳平衡点——这不仅是一个技术问题,更是一个需要在产品设计、用户教育和行业标准制定等多个层面协同推进的系统性工程。
核心要点
相关推荐

Python零基础全套教程568集:课程结构深度解析与学习建议
深度分析B站568集Python零基础全套教程的课程结构,涵盖基础篇、进阶篇、实战篇三大模块,客观评价课程优劣势并提供高效学习建议,帮助初学者判断这套系统课程是否值得跟学。
腾讯云ADP4.0实测:企业级智能体开发平台如何破解Agent商业化难题
实测腾讯云ADP 4.0企业级智能体开发平台,从快速创建Agent、企业系统连接、自动化评测到Skill安全治理,全面验证其全生命周期管理能力能否解决智能体商业化落地的核心痛点。
Claude Code图形界面:CC Park一键告别命令行
Claude Code命令行界面劝退不少用户?CC Park为Claude Code提供精美Web图形界面,一条命令即可在浏览器中操作,降低使用门槛的同时保留完整编码能力。