AI总答偏?用代码把资料编译成任务上下文

将原始资料编译为结构化上下文,是提升AI输出质量的关键。
文章指出,直接将未经处理的原始资料丢给AI往往导致答案偏差,根本原因在于给的是散乱资料而非结构化上下文。通过"上下文编译"——扫描证据、抽取哨兵字段、分层标记可信度、登记冲突风险——可以将原始资料转化为高质量任务上下文,使AI输出从2分跃升至90分。这一方法弥补了RAG架构忽视信息可信度和矛盾检测的不足。
问题的本质:你给的是资料,不是上下文
你有没有遇到过这种情况——把一堆资料丢给AI,它看起来全都读了,但最后给出的答案还是偏了?
很多人的第一反应是"模型变笨了",但真正的原因往往更简单:你给的是原始资料,不是任务上下文。 资料是散乱的、未经筛选的信息堆;而上下文是经过结构化处理、带有可信度标记、能让AI可靠执行的任务指令包。这两者之间的差距,就是AI答偏与答准的关键。
理解这个问题需要先了解大语言模型处理输入的底层机制。模型并不像人类一样逐步阅读和筛选资料,而是通过**注意力机制(Attention Mechanism)**对上下文窗口内所有token同时计算相关性权重。这意味着一条过期旧笔记和一份权威日志,在物理上处于完全平等的竞争地位——谁的语义更接近问题,谁就可能获得更高权重。面对混杂了高噪声内容的输入时,模型很容易被误导性信息"拉偏",产生看似合理却缺乏真实依据的输出。
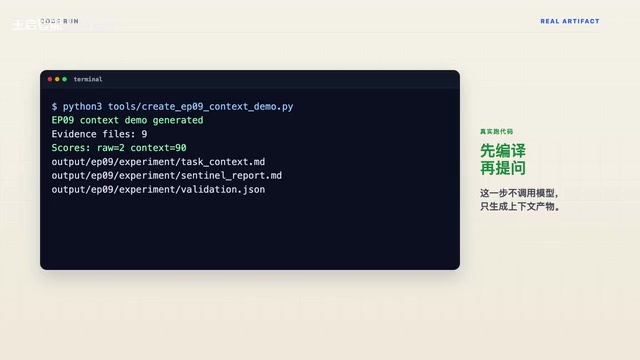
最近看到一位开发者分享了一段实战代码,演示了如何通过"上下文编译"脚本,将原始资料转化为高质量的任务上下文,效果差异非常显著。
一个真实案例:管理员登录失败的排查
案例场景很典型:一个客户反馈"管理员登录失败了",支持团队需要判断——这到底是客户密码问题,还是系统的OAuth Token问题?最终还要写一段可以发给客户的中文回复。
在深入案例之前,有必要了解OAuth Token的工作机制。**OAuth(开放授权)**是一种广泛使用的授权框架,允许第三方应用在不暴露用户密码的前提下获得有限访问权限。其核心机制是颁发短期有效的Access Token和用于续期的Refresh Token。当日志显示error_token_expired时,意味着Access Token已过期,系统尝试用Refresh Token换取新令牌——这是一个完全正常的自动化流程,与用户密码无关。后续日志中的token refresh recovered则证明系统已自动恢复。如果不理解这一机制,很容易将"登录失败"误判为用户凭证问题,从而给出错误的"重置密码"建议。

原始资料包括:
- 工单记录:客户的问题描述
- 应用日志:系统运行的真实记录
- 处理手册:标准操作流程
- 配置文件:系统参数
- 错误截图的OCR文本:从截图中提取的文字
- 一条过期旧笔记:写着"登录失败先让客户重置密码"
这里有一个关键陷阱:那条过期旧笔记。如果你把所有资料不加区分地塞给AI,这句"先让客户重置密码"就可能污染答案。AI会给出一个看似安全、实则没有证据支撑的建议——让客户先重置密码。
上下文编译:脚本做了什么?
这段脚本的核心思路不是调用大模型,而是在调用模型之前做一次上下文编译(Context Compilation)。整个流程分为四步:
- 扫描证据目录:遍历所有原始资料文件
- 生成证据清单:为每份资料建立索引和元数据
- 抽取哨兵字段:从日志和OCR中提取关键错误码、时间戳等硬事实
- 登记冲突风险:标记资料之间的矛盾和潜在误导信息
最终输出一个结构化的 task_context.md 文件。
值得注意的是,这一思路与当前主流的**RAG(检索增强生成,Retrieval-Augmented Generation)**架构形成了有趣的对比。大多数RAG实现只解决了"检索到什么"的问题,却忽视了"检索到的内容是否可信、是否互相矛盾"这一更深层的问题。上下文工程正是在RAG之上的进一步演进——它不仅关注信息的召回率,更关注注入上下文的结构质量、可信度层级和冲突标记。这也是为什么同样的模型、同样的检索结果,经过上下文编译后输出质量会有质的飞跃。

哨兵字段:区分"出现过"和"正在发生"
这里的**哨兵字段(Sentinel Fields)**概念非常重要。这一概念借鉴自软件工程中的"哨兵值"思想——用特定标记来区分正常数据和边界状态。在上下文工程中,哨兵字段特指那些从原始资料中提取的、具有唯一性和时间戳绑定的硬事实,例如错误码、会话ID、精确时间戳等。这类字段的价值在于它们是"不可模糊"的——error_token_expired就是error_token_expired,不存在语义漂移的空间。
脚本只从日志和OCR中抽取到一个真实错误码,虽然处理手册里提到了"password"相关内容,但那是手册中"禁止假设"的规则描述,不是当前事件的实际错误。将这些字段单独抽取并固定为上下文的"事实锚点",相当于给模型的推理过程设置了不可逾越的边界,防止模型在缺乏证据时进行自由联想式的填空。
这一步的本质是在告诉AI一个关键原则:资料里出现过某个词,不等于它就是这次事件的事实。
证据可信度三层分级
生成的上下文包会把证据分成三个可信度层级:
| 层级 | 包含内容 | 说明 |
|---|---|---|
| 高可信 | 工单、应用日志、处理手册、配置文件 | 直接来源,可直接引用 |
| 中可信 | 错误截图OCR文本 | 需要OCR抽样验证,可能存在识别误差 |
| 低可信 | 过期旧笔记 | 仅作为风险信号,不可作为决策依据 |
同时,上下文包会把关键事实固定下来:
- Workspace:acme-admin
- Region:ap-east
- 失败时间:09:42
- 错误码:error_token_expired
- 后续日志:token refresh recovered(已恢复)
输出对比:从2分到90分的差距
作者设计了一个脚本规则校验来量化输出质量,检查维度包括:错误码是否保留、恢复状态是否提到、回答是否引用来源、是否做了无依据假设。
这种基于规则的确定性评估框架与依赖另一个LLM打分的"LLM-as-Judge"方法形成对比。规则校验的优势在于可重复性和可解释性:每一条规则都是二元判断,不受评估模型本身偏差的影响。这种方法在AI应用的质量保障(QA)体系中越来越受到重视,尤其适用于有明确事实依据的任务场景——对于技术支持、文档分析等结构化任务,规则校验是目前最可靠的输出质量量化手段之一。
原始乱塞路线:校验分 2/100
直接把所有资料塞给AI的结果:
- ❌ 没有引用具体证据
- ❌ 没有保留原始错误码
- ❌ 给出了无依据的"重置密码"建议
- ❌ 受到过期旧笔记的污染
任务上下文路线:校验分 90/100
AI的回答变成了:
- ✅ 明确指出"这更像是OAuth Token Refresh短暂失败,不是客户密码问题
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。