Anima二次元大模型:6G显存本地部署与工作流配置教程

Anima二次元AI绘图模型仅需6G显存即可本地部署运行
Anima是一款专注二次元动漫风格的AI绘图大模型,通过模型蒸馏和量化压缩技术将显存需求降至6G,让中低端显卡用户也能体验AI绘图。基于ComfyUI节点图架构,工作流分为文生图和高清放大两个模块,单张生成约1分钟。强烈建议本地部署以获得更自由的创作空间,但需自行承担内容合规责任。
概述
最近社区里有一款叫 Anima 的二次元动漫AI绘图大模型火了起来。它最大的卖点就是对硬件要求特别友好——只要 6G显存 就能在本地跑起来,而且内容生成方面限制比较少,算是给二次元爱好者和AI绘图玩家提供了一个门槛很低的本地部署方案。
这篇文章根据B站UP主的实测分享,整理了Anima模型的工作流配置、实际性能表现,以及本地部署时需要注意的一些细节。
Anima模型有哪些核心特点
6G显存就能跑的超低门槛
Anima模型最让人惊喜的地方就是硬件要求真的很低。要理解这有多难得,需要先了解一点背景:当前主流AI绘图模型大多基于Stable Diffusion架构,该架构在推理时需要将模型权重、激活值、KV缓存等数据同时加载到GPU显存中。SD 1.5系列模型约需4-6G显存,而SDXL系列则通常需要8-12G,这使得大量中低端显卡用户被拒之门外。Anima通过模型蒸馏、量化压缩等技术手段,在保持画质的前提下将显存需求压缩至6G,这在二次元专项模型中属于较为激进的优化策略。
换句话说,哪怕你用的是 GTX 1660、RTX 2060 这类中低端显卡,也完全能跑得动。实测在6G显存条件下,不开高清放大的话,单张图片大概 1分钟左右 就能生成,日常创作完全够用。
专为二次元风格打造
Anima是一款专门针对动漫二次元风格做过优化的大模型,在角色立绘、场景插画这些方面表现力相当不错。跟那些通用型模型比起来,Anima在画风一致性和细节刻画上明显更有优势。
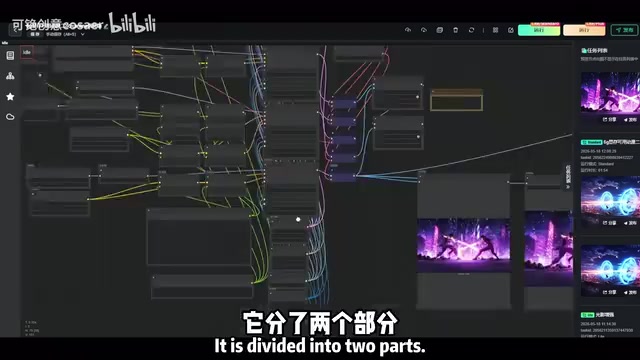
Anima工作流配置详解
Anima的工作流基于 ComfyUI 构建并分发。ComfyUI是目前AI绘图社区最主流的本地部署前端之一,采用节点图(Node Graph)架构,将整个图像生成流程拆解为若干可视化节点,每个节点负责一个独立的计算步骤(如加载模型、编码提示词、采样去噪、解码图像等),节点之间通过连线传递张量数据。这种设计让用户可以灵活组合和复用工作流,相比WebUI的线性流程更易于调试和扩展,也是Anima选择以ComfyUI工作流形式分发的主要原因。
整体工作流分成两个核心模块,逻辑很清晰,用户可以根据自己的需求灵活调整。
文生图模块配置
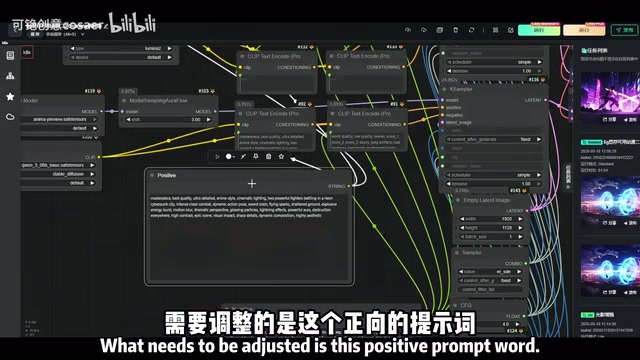
第一个模块是 文生图(Text-to-Image),也是整个工作流的基础部分。你只需要输入正向提示词(Prompt)来描述想要的画面,模型就会据此生成对应的二次元图像。
这里有几个关键参数需要调整:
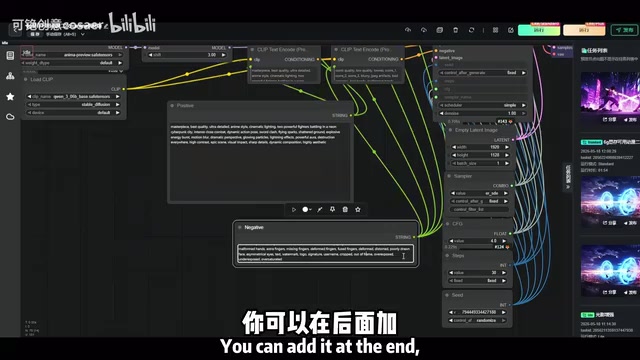
- 正向提示词(Positive Prompt):写清楚你想要的画面内容,比如角色外貌、场景氛围、画风偏好等
- 反向提示词(Negative Prompt):可填可不填,主要用来排除不想出现的元素。实测下来,反向提示词后面追加也行,留空也不影响出图
- 出图尺寸:需要手动设置宽高,根据实际用途选择合适的分辨率
- 生成批次:可以设定一次出多少张图
高清放大模块设置
第二个模块是 高清放大(Upscale)。文生图出来的图片分辨率通常不算高,通过这个模块可以把图像拉到更高的分辨率,同时让细节更加精细。
AI绘图中的高清放大并非简单的插值缩放,而是借助专用的超分辨率模型(如Real-ESRGAN、4x-UltraSharp等)对图像进行语义级别的细节重建。在ComfyUI工作流中,Upscale节点通常会先将低分辨率图像放大2-4倍,再可选地进行一轮img2img重绘以修复放大后的模糊和伪影,这个二次推理过程会额外消耗约1-2G显存。因此,如果你的显存刚好卡在6G的线上,建议平时预览的时候先关掉放大功能,等构图确认满意了再开启,这样既省时间又能拿到高质量的最终成品。
本地部署Anima的具体建议
为什么强烈推荐本地部署
在线AI绘图平台(如Midjourney、NovelAI在线版等)通常部署了基于NSFW分类器的内容审核系统,会在生成前后对提示词和图像进行过滤。本地部署则将推理计算完全转移至用户自己的硬件,平台层面的审核机制不再介入。对于Anima这种内容限制相对宽松的模型,本地部署几乎是最优解。理由很简单:
- 隐私安全有保障:所有生成的内容都存在自己电脑上,不用担心数据外泄
- 不受平台审核限制:在线平台的内容审核通常比较严格,很多创作想法在平台上根本实现不了
- 规避合规风险:部分敏感内容在公共平台上生成可能存在合规问题,放在本地就没有这个顾虑
需要特别强调的是,本地部署并不意味着法律层面的豁免——生成、传播违法内容在任何情况下都受到相关法律约束,用户需自行承担内容合规责任。
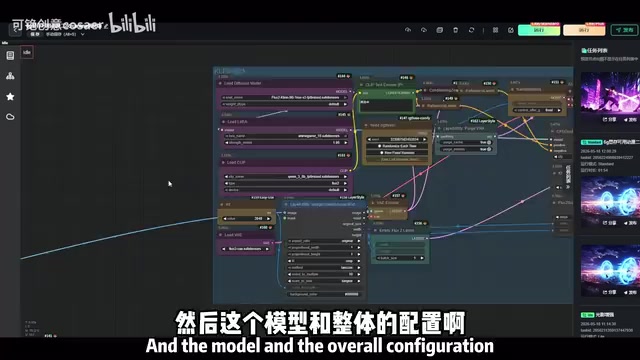
部署所需资源清单
根据UP主的分享,完整部署需要准备以下资源:
- Anima模型文件:核心的大模型权重文件
- ComfyUI工作流配置:预设好的工作流JSON文件
- 自定义节点插件:工作流中依赖的各类节点
这些资源已经打包好了,导入ComfyUI后基本可以直接用,省去了从零配置的麻烦。
6G显存用户的性能优化技巧
显存只有6G的话,下面这几个优化技巧能帮你获得更流畅的体验:
- 关掉吃显存的后台程序:Chrome浏览器、视频播放器这些都会偷偷占用显存,跑图的时候最好全部关掉
- 先预览再放大:用较低分辨率快速看效果,满意了再开高清放大,避免反复重跑浪费时间
- 控制单次生成数量:6G显存建议一次只生成1到2张图,批次太多容易显存溢出直接报错
- 开启FP16半精度推理:深度学习模型默认使用FP32(32位浮点数)存储权重,而FP16(16位浮点数)半精度模式将每个参数的存储空间减半,理论上可将显存占用降低约40-50%。需要注意的是,GTX 10系显卡对FP16的硬件加速支持有限,实际速度收益可能低于预期,但显存压缩效果仍然有效。如果工作流支持的话,切换到半精度模式可以进一步压缩显存占用。
总结
Anima作为一款专注二次元领域的AI绘图大模型,6G显存就能跑的特性确实让不少中低端显卡用户看到了希望。基于ComfyUI节点图架构的工作流设计也比较合理,文生图加高清放大的双模块架构兼顾了效率和画质。
如果你是二次元爱好者,又一直苦于显卡不够好而无法体验AI绘图,Anima确实值得一试。当然,最后还是要提醒一句:不管用什么AI工具,都请遵守相关法律法规,合理合法地进行创作。
核心要点
- Anima是专注二次元动漫风格的AI绘图大模型,通过量化压缩等技术仅需6G显存即可本地运行
- 工作流基于ComfyUI节点图架构,分为文生图和高清放大两个模块,6G显存下单张生成约1分钟
- 关键参数包括正向提示词、出图尺寸和生成批次,反向提示词可选填写
- 强烈建议本地部署使用,但本地部署不等于法律豁免,需自行承担内容合规责任
- 完整部署资源包含模型文件、工作流配置和节点插件,可一键导入使用;FP16半精度推理可进一步压缩显存占用
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。