Anthropic团队实战:16个Agent并行开发编译器的Claude Code使用经验

核心发现:Claude Code远不止写函数那么简单
Anthropic的工程博客和官方文档揭示了研发团队使用Claude Code的真实方式——不是简单地让AI帮写一个函数,而是16个Agent并行开发编译器、三角色架构做全栈应用、自动分类器处理审批流程。这些实践背后的架构思维,值得每位从事AI辅助编程的开发者深入学习。


16个并行Agent从零构建C编译器
Anthropic研究员Nicholas Carlini做了一个令人震撼的实验:用16个并行Claude Agent从零编写了一个能编译Linux内核的C编译器。这不是玩具项目,而是一个真正能编译Linux 6.9、FFmpeg、SQLite、PostgreSQL的编译器,GCC Torture测试通过率高达99%,甚至能编译并运行Doom。
多Agent协作的技术实现
整套系统的运行机制相当精巧:通过bash循环脚本让Claude在Docker容器里持续运行,每完成一个任务就自动领取下一个。多Agent之间通过Git分布式协作,每个Agent在独立目录下用文件锁认领任务,完成后拉代码、合并代码,冲突由Claude自己解决。
同时还做了专业化分工:有的Agent负责合并重复代码,有的做性能优化,有的写文档。最终产出数据:近2000个Claude Code会话,两周时间,输入20亿token,输出1.4亿token,总成本约2万美金,产出10万行代码。
三条关键经验
验证器必须靠谱。 Claude会自主解决任何给定问题——如果验证器有bug,它会修好验证器而不是修好代码。这意味着如果你给它一个有问题的测试用例,它可能会"聪明地"修改测试让其通过,但bug依然存在。正确做法是先确认测试用例本身没问题,再让Claude去修复。
站在Claude的角度想问题。 不要让日志输出几千字无用内容,那会污染上下文窗口,严重影响后续推理质量。精简输出信息是提升Agent效率的关键一步。
并行化要保持简单。 任务拆得越简单,并行效果越好。复杂任务的协调开销会吞噬并行带来的收益。
三Agent架构:解决上下文焦虑
单Agent长时间运行存在两个致命问题。第一是上下文焦虑现象:当上下文窗口被各种信息填满时,Claude会开始反复检查已完成的工作,不敢推进新任务,在窗口即将满时则会草率完成任务。第二是自我评估偏差:Agent在评价自己的工作时总是过于宽容和乐观——"挺好的,差不多了",实际上差得远。
Planner-Generator-Evaluator分工
Anthropic的解决方案是三角色架构:
- Planner(计划器):把简单提示扩展为完整产品规格,有意不过度指定技术细节
- Generator(生成器):按Sprint逐个功能实现,每个Sprint结束后自评
- Evaluator(评估器):用Playwright实际操作运行中的应用,像用户一样点击测试,发现真实bug后反馈给生成器
对比测试数据
同一个提示"制作复古游戏编辑器":单Agent花20分钟、9美金,结果界面粗糙、核心功能损坏;三Agent花6小时、200美金,结果功能丰富、实际可玩。成本贵了20倍,但结果从"不能用"变成了"能玩"。对于真实项目来说,这个投入产出比完全值得。
智能审批:解决93%盲目批准问题
用过Claude Code的开发者都知道,它每执行一步都要询问是否批准。据统计,用户93%的时候都选择批准,这导致严重的审批疲劳——点到第十次的时候你已经不看内容了,安全防线形同虚设。
双层防御机制
Anthropic的方案是Auto Mode:用模型分类器自动判断哪些操作安全、哪些危险,安全的直接通过,危险的才询问用户。
具体设计了双层防御:输入层扫描工具输出,发现可疑内容时注入警告;输出层分类器只看用户消息和工具调用,不看Agent的推理过程——这是为了防止Agent"说服"分类器放行。
测试数据显示:一万条真实内部流量,误报率仅0.4%,只拦错了40条。
Managed Agents:避免过度设计
这是最能体现架构思维的部分。Anthropic团队发现,Agent框架里编码了太多对模型局限的假设,但模型进步后这些假设就会过时。举个例子:你搭了一套完整的Agent框架,写了一堆最佳实践,结果模型一升级大半都废了——因为那些实践本质上是在补偿模型的缺陷,模型变强了补偿就不需要了。
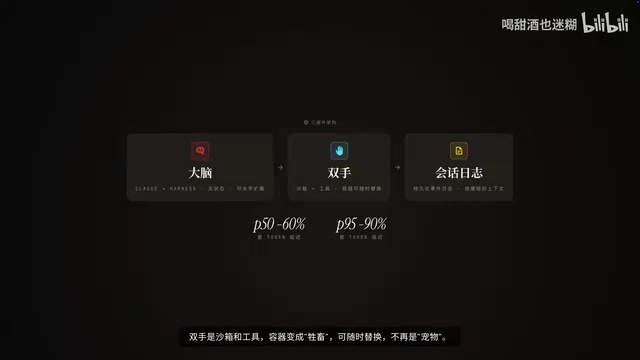
三组件拆分策略
他们的核心思路是把Agent系统拆成三个独立组件:
- 大脑:Claude + Harness,无状态可水平扩展
- 双手:沙箱和工具容器,变成"牲畜"可随时替换,不再是"宠物"
- 记忆:持久化的事件日志,Harness可按需组织上下文
效果数据:首token延迟P50下降约60%,P95下降超过90%。
官方最佳实践六条
1. CLAUDE.md配置先行
每次启动Claude Code都会读取CLAUDE.md文件,相当于项目的持久记忆。加载优先级从远到近叠加:用户级(所有项目生效)→ 项目级(团队共享)→ 子目录级(优先级最高)。
关键原则:写Claude猜不到的东西(构建命令、代码风格规则、常见坑),能通过读代码推断出来的就别写。CLAUDE.md太长会导致重要规则被淹没。
2. Plan Mode处理复杂任务
四步流程:探索阶段(Plan Mode下读文件、回答问题)→ 规划阶段(创建详细实现方案)→ 实现阶段(切出Plan Mode按方案编码)→ 提交阶段(写描述性Commit Message、开PR)。
适用场景:新功能开发、多文件重构、架构决策、需求不明确时。一句话能描述清楚的任务就别规划了。
3. Dynamic Workflows交叉验证
2.1.154版本新功能,核心思路是把计划变成脚本,可重复运行、并行执行、交叉验证。最实用的特性是N个独立"怀疑者"验证,多数反驳就排除——写代码的Claude不是审查自己代码的那个Claude。
4. 管理上下文窗口
这是所有策略的基础。不相关任务之间用Clear命令重置;用子Agent做调查避免污染主上下文;两次纠正无效就Clear重来。上下文管理做得好,Agent的输出质量会有质的提升。
5. 多Agent协作模式
Claude Code支持创建多种专用子Agent:Explore(快速扫描代码库)、Frontend Engineer、Backend Engineer、Code Reviewer、Test Engineer。关键参数:Isolation用Worktree给子Agent独立的Git分支避免文件冲突,Run Background后台运行完成时通知。
6. 给Claude提供验证手段
没有验证手段的自主运行是危险的。Agent自己觉得做完了,但可能没做完或做错了。必须提供客观的验证机制,比如测试套件、类型检查、lint工具等。
总结:一个核心原则
把这些实践串起来看,Anthropic其实在讲同一件事:把确定性的逻辑交给脚本,把需要判断的交给AI,然后给AI一个靠谱的验证手段。
落实到日常开发:配置先行写好CLAUDE.md,复杂任务用Plan Mode,并行化是趋势,分离生成和评估,管好上下文,不要过度设计。模型在快速进步,今天的最佳实践明天可能就是累赘——保持架构的灵活性,比追求当下的完美更重要。
相关推荐
Vibe Coding实战:大三学生用Cursor打造51个AI官员的三省六部制多智能体系统
大三学生用Cursor通过Vibe Coding搭建三省六部制AI多智能体协作系统,51个AI官员各司其职,实现任务分发、审批流转、监察考核的完整闭环。深度解析分权制衡、Token成本可视化、自动化决策等核心架构设计。
Codex接入DeepSeek模型教程:通过CC Switch自由切换
详细介绍如何通过CC Switch工具将OpenAI Codex接入DeepSeek模型,实现DeepSeek与GPT之间自由切换,附完整配置步骤、路由设置及常见问题解决方案。
AI Coding部署指南:从本地Demo到网站上线的完整实战流程
大多数AI Coding教程只教写本地Demo,却没人讲怎么部署上线。本文以Codex构建AI 3D手办网站为例,完整拆解从编码到服务器部署的8个关键步骤,帮你跨越从玩具到产品的最后一公里。