Anthropic最新研究:AI递归自我改进能力正逼近人类
核心议题:AI递归自我改进意味着什么
Anthropic近期发布了一篇重磅研究报告,聚焦AI系统的递归自我改进(Recursive Self-Improvement)——即AI系统逐步具备设计和训练下一代AI的能力,对人类介入的依赖越来越少。
长期以来,业界流传着一个令人安心的说法:AI无法取代人类的"品味"(taste),也就是判断哪些问题值得解决、哪些结果可信、何时该放弃死胡同的能力。然而,Anthropic的内部实验数据显示,这条看似稳固的边界正在被悄然侵蚀。
自我优化系统的质变:从进化算法到生成式AI
自我优化系统的概念并不新鲜。进化算法几十年来一直在做类似的事情:提出一批变体方案,用适应度函数打分,保留最优解,循环往复。芯片设计、软件优化等领域早已广泛应用这一思路。
但生成式AI时代带来了质的飞跃:
- DeepMind的AlphaEvolve打破了自1969年以来的标量乘法记录
- Sakana的Darwin Godel Machine将自身在SWE-bench上的得分从20%提升到50%
- Andrej Karpathy的Auto Research系统能够自主运行实验并优化目标函数
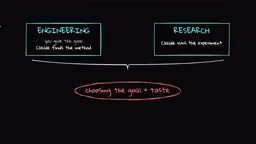
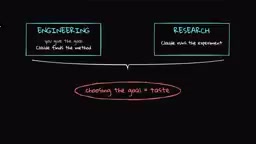
你可能没注意到,上述所有系统中,人类仍然负责定义目标函数和评估标准。Anthropic将自身工作分为两个维度:工程(编写代码和基础设施)和研究(选择实验方向并解读结果)。在工程层面,Claude已经能够接受一个模糊的问题并自行找到解决方法;在研究层面,它已经能匹配人类执行明确定义实验的能力。剩下的缺口是选择目标本身的判断力。
任务能力的指数级增长:METR基准测试数据
METR(一个独立评测实验室)的任务地平线基准测试提供了直观的量化视角。该基准衡量的是模型能以50%成功率独立完成的任务,以人类完成该任务所需的时间来计量。需要特别说明的是,这里的时间不是模型的运行时间,而是等效的人类工作时长。
数据显示,这个数字大约每四个月翻一番:
- 2023年3月的Opus 4:约4分钟级别的任务
- 2025年2月的Opus 4.6:约12小时
- 最新预览版本:约17小时,已接近METR当前能测量的上限
这种增长速度意味着,AI独立处理复杂任务的能力正在以远超多数人预期的速度提升。
Anthropic内部数据:工程与研究的双重突破
工程效率的飞跃
截至2025年5月,Anthropic合并的代码中超过80%由Claude编写。而在Claude Code发布之前的2024年初,这个数字还是个位数。典型工程师现在每天合并的代码量是2024年的8倍。

在一项反复进行的内部测试中,研究团队让Claude优化训练代码的速度。一年前最好的模型实现了约3倍加速,而今年4月已经达到了52倍加速。作为对比,一位优秀的人类研究员需要4到8小时才能达到4倍加速。此外,Claude在一个月内修复了超过100个问题,将一类API错误减少了1000倍——据估计,工程师完成类似工作需要约4年。
"品味"测试的突破
更引人注目的是关于研究判断力的实验。Anthropic提取真实的研究会话记录,找到人类做出下一步决策的关键节点,然后让模型判断是否有更好的选择——由已知最终结果的评审者来裁定。
| 模型版本 | 优于人类决策的比例 |
|---|---|
| Claude Opus 4.5(去年11月) | 51% |
| 预览版本(今年4月) | 64% |
| 理论天花板 | 约90% |
这意味着在特定决策点上,模型已经开始展现出优于人类的判断力。
不可忽视的局限性与Goodhart定律

尽管数据看起来很亮眼,有几个重要的理由让我们必须保持审慎:
8倍代码量是个容易误导的指标
代码行数奖励的是数量而非质量。Anthropic自己也承认,真实的生产力提升"几乎肯定低于这个数字"。社区讨论中有人指出,代码的反复编写和回退会虚增提交量。员工自报的4倍生产力提升同样值得怀疑——METR的独立研究表明,开发者倾向于高估AI对自己的帮助程度。
品味测试存在重要脚注
当只看人类做出深思熟虑的强决策的时刻,模型仅领先20%。换言之,模型擅长的是"挽救弱决策",而非"超越好决策"。这个区别至关重要。
Goodhart定律的幽灵挥之不去
任何针对既定目标进行优化的系统,最终都会学会"钻空子"。当一个度量标准变成目标时,它就不再是好的度量标准。代码行数恰恰是这种容易被博弈的目标。
真正的问题不是循环是否在加速——它显然在加速——而是它是否在优化我们真正关心的东西,还是仅仅在优化容易计数的东西。
最令人瞩目的实验:AI智能体独立完成安全研究
尽管有上述保留意见,有一个实验确实令人瞩目。Anthropic选取了一个AI安全领域的开放问题——弱模型能否可靠地监督强模型——交给Claude驱动的智能体,然后基本放手不管。
实验结果对比:
- 两位人类研究员花了大约一周时间,缩小了约25%的差距
- AI智能体将差距缩小到了97%,累计工作超过800小时,消耗约18,000美元的算力
关键在于,智能体自行设计了每一个实验。虽然人类仍然选择了问题本身并编写了评分标准,但在这个边界内,智能体不是在辅助研究员——它们就是研究员。
此外,在Project Glasswing中提供给部分企业的模型,已经在主流操作系统中发现了超过10,000个高危和关键安全漏洞。瓶颈已经从"发现漏洞"转移到了"修补漏洞的速度跟不上"。
冷静思考:从业者该如何应对AI自我改进趋势
Anthropic在报告中提出了一个发人深省的观点:如果"研究品味"只是另一种能力,那么模型可能会像学会解释笑话或通过心智理论测试一样,悄然掌握它。人类始终留在判断环节的叙事,可能有一个倒计时。
但也需要正视几点现实:
- 能力曲线通常是S型而非指数型,计算资源和人类审查的瓶颈可能会减缓进展
- 当前AI的智能仍然是"锯齿状"的——在某些点上表现出色,在其他领域仍然糟糕
- 距离真正的递归自我改进还有相当距离,因为系统尚不能自主设定目标
对于今天使用这些模型的从业者,最实际的启示是:你的核心竞争力正在从"亲手完成工作"转向"精确定义工作并验证结果"。 这本身就是一项值得深耕的技能。
有人指出Anthropic即将IPO,发布这类报告可能存在商业动机。但客观来说,Anthropic此前已经发布过多篇高质量技术报告,这种研究透明度是其一贯风格。无论动机如何,报告中呈现的趋势——AI在特定任务上的能力正在快速逼近甚至超越人类——是值得每一位技术从业者认真对待的事实。
相关推荐
Codex编程智能体全解析:和ChatGPT到底有什么区别?
深入解析OpenAI Codex编程智能体的核心能力,对比Codex与ChatGPT在编程场景中的本质区别,帮助开发者理解AI编程智能体如何改变软件开发模式。

Databricks开源Omni:统一管理所有AI Agent的元框架
Databricks以Apache 2.0协议开源Omni项目,通过元框架统一管理Claude Code、Codex等多个AI Agent。支持统一会话、跨供应商交叉审查、安全策略强制执行和实时协作,彻底解决多Agent协同与供应商锁定问题。
一句话提示词生成10款网页游戏:Claude Code实战体验
资深开发者用Claude Code命令行工具,仅凭一句话自然语言提示词,在一小时内生成2048、五子棋、俄罗斯方块等10款可玩网页游戏并部署上线。深度解析AI编程的真实能力与局限。