本地部署大模型怎么判断显存爆了?一文看懂显存监控方法

通过观察GPU共享内存占用判断本地大模型是否爆显存及应对方法
判断本地大模型是否爆显存的核心方法是看GPU总内存使用量是否超过物理显存容量——关键指标不是专用显存,而是共享GPU内存是否被大量占用。爆显存后因内存带宽远低于显存带宽(约10倍差距),推理速度会断崖式下降。可通过根据显存选择合适模型规格、使用Q4_K_M等量化模型、缩短上下文长度等方式有效避免。
引言
越来越多开发者和AI爱好者开始在本地部署大模型,但显存管理始终是绕不开的核心问题。显存不足——也就是常说的"爆显存"——会让模型推理速度断崖式下降,严重影响使用体验。那么,怎么准确判断自己的显卡是不是已经爆显存了?这篇文章结合实际操作界面,手把手讲清楚判断方法和注意事项。
专用显存与共享GPU内存:先搞清这两个概念
在Windows任务管理器或GPU监控工具中,你会看到两个跟显存相关的指标:专用GPU内存(Dedicated GPU Memory) 和 共享GPU内存(Shared GPU Memory)。很多人搞混了这两个概念,导致误判。
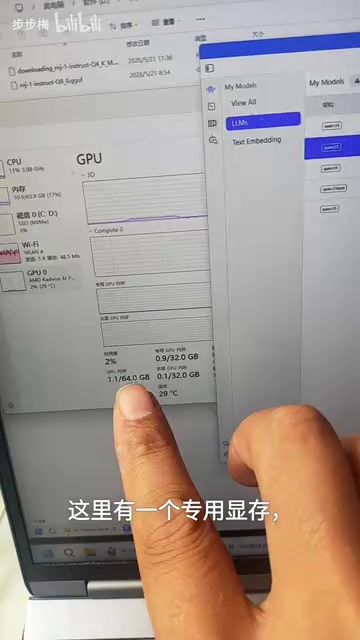
专用GPU内存
专用GPU内存就是显卡上实际搭载的物理显存(VRAM)。比如你的显卡标称32GB显存,那专用GPU内存的上限就是32GB。这个数值不会超过显卡的物理显存容量,也不可能变成负数,更不会被打满到超出上限。
值得了解的是,VRAM是直接焊接在GPU PCB板上的高速存储芯片,与GPU计算核心之间通过极宽的内存总线直接相连(例如NVIDIA高端卡的总线位宽可达5120-bit),延迟极低、带宽极高。这种紧密的物理连接是GPU能够高速处理大规模矩阵运算的硬件基础。
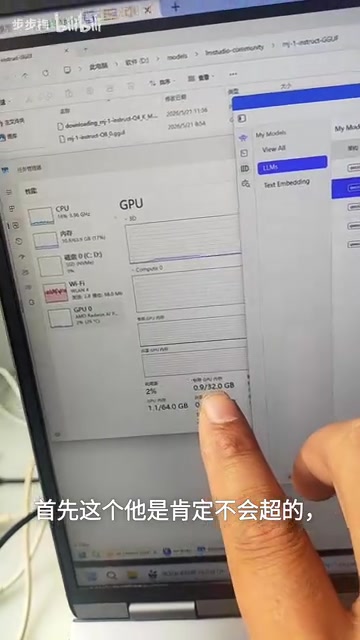
共享GPU内存(判断爆显存的关键)
共享GPU内存是系统从内存(RAM)中划拨出来给GPU使用的部分。当专用显存不够用时,系统会自动把部分数据转移到共享GPU内存中——这就是所谓的"显存溢出",也就是爆显存。
系统RAM通过PCIe总线与GPU通信,PCIe 4.0 x16的理论带宽约为32GB/s,与VRAM动辄数百GB/s的带宽相比差距悬殊。这种物理架构上的差异,决定了一旦数据溢出到共享内存,性能损耗是结构性的,无法通过软件优化完全弥补。
划重点:判断是否爆显存,核心不是看专用显存的数值,而是看共享GPU内存是否被大量占用。
三步判断显存是否爆了
以32GB显存的显卡为例,打开任务管理器的"性能"选项卡,找到GPU部分:
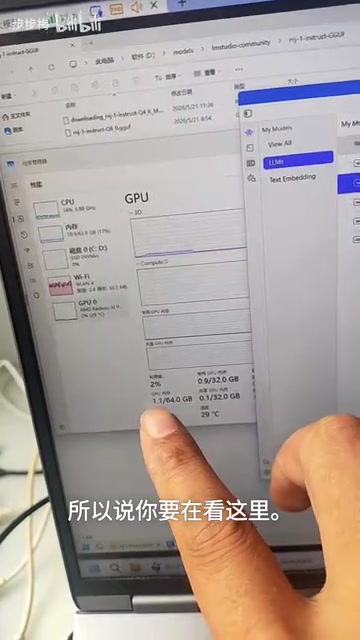
第一步:看专用GPU内存使用量。 如果已经接近或达到32GB,说明显存快用完了,处于危险区域。
第二步:看共享GPU内存使用量。 如果这个数值明显不为零且在持续增长,说明已经开始爆显存了。
第三步:看总GPU内存使用量。 如果总使用量超过了你的物理显存容量(比如超过32GB),那就可以确认——显存确实爆了。
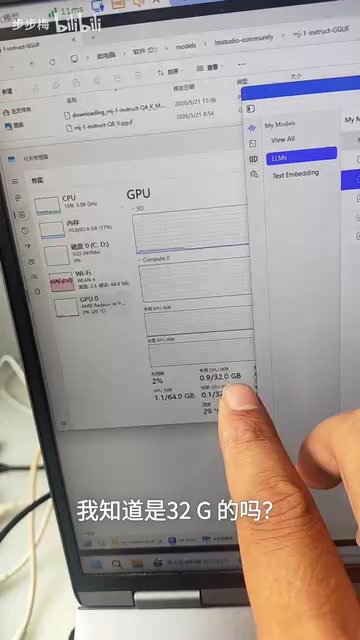
进阶监控技巧: Windows任务管理器显示的是操作系统层面的内存分配视图,存在一定局限性。对于NVIDIA显卡用户,更精确的方式是使用
nvidia-smi命令行工具——它直接读取驱动层数据,能显示每个进程的精确显存占用(单位MB)、GPU利用率、显存带宽利用率等细粒度指标。运行nvidia-smi dmon可以实时刷新监控数据,在多进程共享GPU的场景下尤为可靠。
爆显存后速度为什么断崖式下降
爆显存后最直观的感受就是推理速度骤降。原因很简单:内存(RAM)的带宽和显存(VRAM)的带宽完全不在一个量级。
| 存储类型 | 典型带宽 |
|---|---|
| GDDR6X显存 | 500GB/s ~ 1TB/s |
| DDR5内存 | 50 ~ 80GB/s |
两者相差大约10倍。一旦数据频繁在内存和显存之间来回搬运,推理速度可能从每秒数十个token直接掉到每秒几个token,体验非常糟糕。
这种性能损耗的本质是内存墙(Memory Wall)问题:大模型推理是典型的内存带宽密集型任务,GPU计算核心的算力往往处于等待数据的状态,带宽瓶颈直接决定了推理吞吐量的上限。
避免爆显存的实用建议
根据显存容量选模型
不同显存容量适合跑的模型规格差异很大,选错了就是白白浪费时间:
| 显存容量 | 建议模型规格 |
|---|---|
| 8GB | 7B模型(Q4量化) |
| 16GB | 7B ~ 14B模型(Q4 ~ Q8量化) |
| 24GB | 14B ~ 32B模型(Q4 ~ Q6量化) |
| 32GB | 32B ~ 70B模型(Q4量化) |
优先使用量化模型
量化是降低显存占用最直接有效的手段。其核心原理是将模型权重从高精度浮点数(如FP32、BF16,每个参数占16~32位)压缩为低位整数表示。以Q4量化为例,每个权重参数从16位压缩到4位,理论上可将模型体积缩小约75%。
GGUF格式中常见的Q4_K_M采用了**分组量化(Group Quantization)**策略:将权重分成若干小组,每组独立计算缩放因子(scale)和零点(zero point),在压缩率和精度损失之间取得更好的平衡。实际测试中,Q4_K_M相比FP16的困惑度(Perplexity)损失通常在1%~3%以内,对大多数日常任务几乎无感知差异。常见的量化格式有Q4_K_M、Q5_K_M、Q8_0等,数字越小精度越低,但显存占用也越少。对于显存吃紧的用户,Q4_K_M是精度和显存占用之间比较好的平衡点。
适当缩短上下文长度
上下文长度(Context Length)同样是显存消耗的大户,其背后的机制与Transformer架构的KV Cache密切相关。
KV Cache是用于加速自回归推理的核心机制——它将每一层注意力计算中的Key和Value矩阵缓存起来,避免对历史token的重复计算。但这个缓存的大小与上下文长度成正比:上下文从4K扩展到8K,KV Cache占用的显存会近乎翻倍。对于一个70B参数的模型,8K上下文的KV Cache可能额外占用数GB显存。
因此,如果你不需要处理超长文本,把上下文长度从默认的8K甚至更高降到4K或2K,就能明显减少显存占用。在显存紧张时,这个调整往往比换用更小的量化等级更能立竿见影地释放显存压力。
总结
判断本地大模型是否爆显存,核心方法就一句话:看GPU内存总使用量有没有超过显卡的物理显存容量。 一旦超出,系统会自动用共享内存来补位,但代价是推理速度大幅下降。
建议在部署模型之前,根据自己的显存容量合理选择模型大小和量化等级,尽量把显存使用控制在物理显存的90%以内。这样才能获得流畅的本地大模型推理体验。
核心要点
- 判断爆显存的关键是看GPU总内存使用量是否超过物理显存容量,而非仅看专用显存
- 专用GPU内存不会超过物理上限,但共享GPU内存被大量占用则意味着显存溢出
- 爆显存后推理速度会断崖式下降,因为内存带宽远低于显存带宽(约10倍差距)
- 量化技术通过降低权重精度大幅压缩显存占用,Q4_K_M是精度与压缩率的优选平衡点
- KV Cache机制使上下文长度与显存占用近似成正比,缩短上下文是快速释放显存的有效手段
- 可通过选择合适模型规格、使用量化模型、控制上下文长度等方式避免爆显存
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。