本地部署DeepSeek+RAG知识库教程:Ollama+RAGFlow保姆级指南
本地部署DeepSeek并通过RAG技术搭建个性化知识库的完整教程
文章介绍了为何需要在本地部署大模型并搭建RAG知识库,指出网页版大模型存在数据隐私风险、文件上传限制和操作不灵活三大痛点。详细讲解了RAG(检索增强生成)技术原理和Embedding模型如何实现语义检索,并给出了通过Ollama部署DeepSeek、Docker部署RAGFlow、构建知识库的完整操作步骤。
为什么要在本地部署DeepSeek并搭建RAG知识库
网页版DeepSeek虽然好用,但在实际应用中存在明显的局限性。试想这样一个场景:你希望大模型根据企业规章制度回答员工问题,或者根据十几份往年期末试卷预测今年的考题。如果不提供这些资料,大模型只能根据自身训练数据"胡说八道"。
网页版大模型主要面临三个痛点:
- 数据隐私风险:所有对话和文件都会上传到云端服务器,敏感数据的安全性无法保证
- 文件上传限制多:网页版对上传文件的数量和大小有严格限制,解析文件还需要额外算力,通常需要付费
- 操作繁琐且不灵活:每次新建对话都要重新上传附件,新增或修改已有附件也非常麻烦
因此,我们需要解决两个核心需求:绝对的数据隐私保护和个性化知识库的构建。前者通过Ollama在本地部署DeepSeek模型来实现,后者通过RAG技术来实现。
RAG技术与Embedding模型原理详解
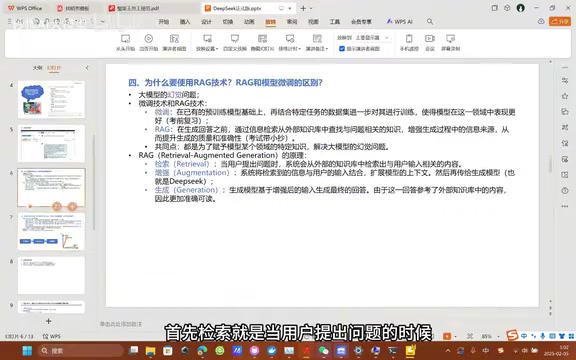
什么是RAG(检索增强生成)
RAG(Retrieval Augmented Generation,检索增强生成)是解决大模型"幻觉问题"的主流方案之一。所谓「幻觉问题」(Hallucination),是指模型在缺乏真实知识支撑时,会以极高的置信度生成看似合理但实际错误的内容。
这一问题根源于大模型的训练机制:以GPT、DeepSeek为代表的大语言模型本质上基于Transformer架构,通过在海量文本语料上预测「下一个token的概率分布」来学习语言规律。这种训练方式赋予了模型生成流畅、连贯文本的能力,却无法保证内容的事实准确性——模型学到的是「什么样的表达在统计上更合理」,而非「什么内容在现实中是真实的」。当模型遇到训练数据中未覆盖的知识盲区时,它不会说"我不知道",而是倾向于生成一个在语言层面"看起来正确"的答案,这便是幻觉的来源。RAG通过引入外部知识库作为实时参考,将模型的「记忆」与「检索」解耦,从根本上降低了幻觉发生的概率。
与模型微调不同,RAG不需要重新训练模型,而是在生成回答之前先从外部知识库中检索相关内容,用真实资料来增强回答的准确性。
打个比方:微调相当于考前复习,模型通过训练把知识"记在脑子里"再作答;RAG相当于开卷考试,模型看到问题后会先翻阅你提供的知识库,再组织答案。
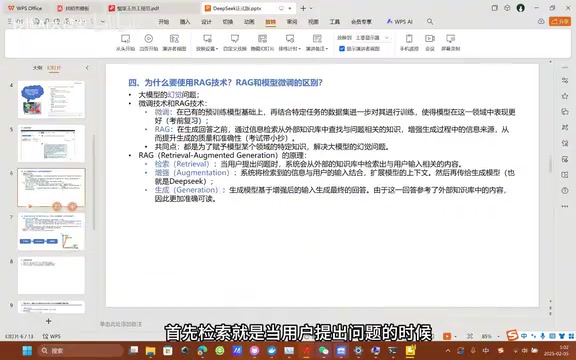
RAG的工作流程分为三步:
- Retrieval(检索):用户提问时,系统从外部知识库中检索与问题相关的内容片段
- Augmented(增强):将检索到的信息与用户的原始问题结合,扩展模型可参考的上下文
- Generation(生成):大模型基于增强后的输入,生成有据可依的最终回答
Embedding模型在RAG中的关键作用
Embedding(嵌入)技术将离散的文本符号映射到连续的高维向量空间,使得语义相近的词或句子在空间中距离更近。这一距离通常用余弦相似度(Cosine Similarity)来衡量——两个向量夹角越小,代表语义越接近。
现代Embedding模型(如BERT、text-embedding系列)通过在海量语料上预训练,能够捕捉词语的上下文语义,而非仅仅依赖字面匹配。这背后的关键突破在于「上下文感知」:同一个词在不同语境下会被映射到不同的向量位置,例如"苹果"在"吃苹果"和"苹果手机"两个语境中会对应不同的语义向量。这正是RAG能够实现「语义检索」而非「关键词检索」的核心原因——即便用户的提问措辞与知识库中的原文完全不同,只要语义相近,系统依然能够准确匹配到相关内容。
机器无法直接理解"谢宝王"和"比奇堡"这两个词之间的关联,但经过Embedding处理后,语义相近的词会被映射到向量空间中相近的位置,从而实现语义层面的匹配。
整个流程可以这样理解:上传知识库文件后,Embedding模型会为每个文段生成一个"语义指纹";用户提问时,问题同样会生成"语义指纹";RAG系统拿着用户的"指纹"去知识库中匹配最相似的内容,找到后传给DeepSeek生成回答。
这些"语义指纹"(即向量)被存储在专门的向量数据库(Vector Database)中。与传统关系型数据库(如MySQL)按字段精确匹配不同,向量数据库的核心能力是近似最近邻搜索(Approximate Nearest Neighbor,ANN)——它通过HNSW(层次化可导航小世界图)、IVF(倒排文件索引)等专用索引结构,能够在存储数百万甚至数十亿个高维向量的情况下,依然在毫秒级时间内找到与查询向量最相似的结果。常见的向量数据库包括Milvus、Qdrant、Weaviate等开源方案,以及Pinecone等云服务。RAGFlow在本地部署时默认集成了Elasticsearch作为向量存储后端,这也是为什么后续「解析」步骤是知识库生效的关键环节——只有完成解析,文档才会被切片、向量化并写入数据库,检索才能真正发生。
这也解释了为什么网页版大模型聊天免费,但上传文件往往要收费——因为文件解析、Embedding向量化处理、向量数据库存储都需要额外的算力和存储空间。
本地部署DeepSeek+RAG知识库完整步骤
整个部署过程分为三步:用Ollama部署DeepSeek、通过Docker部署RAGFlow、构建个人知识库并开始问答。
第一步:安装Ollama并部署DeepSeek模型
Ollama是一个专门用于在本地运行和管理大语言模型的开源工具,操作简单,支持多种模型。其底层基于llama.cpp实现了高效的CPU/GPU混合推理,并支持4-bit、8-bit等量化压缩技术——量化通过降低模型权重的数值精度(例如从32位浮点数压缩为4位整数)来大幅减少显存占用和计算量,使普通消费级硬件也能运行参数量较大的模型,代价是回答质量会有轻微下降。访问 ollama.com 下载安装后,最关键的一步是配置环境变量。
必须配置的环境变量:
OLLAMA_HOST:设置为0.0.0.0:11434,这样Docker容器中的RAGFlow才能访问到本机的Ollama服务OLLAMA_MODELS(建议配置):自定义模型文件的存放路径,因为大模型文件动辄几十GB,默认放C盘容易爆满
配置方法(Windows): 设置 → 系统 → 系统信息 → 高级系统设置 → 环境变量 → 新建系统变量
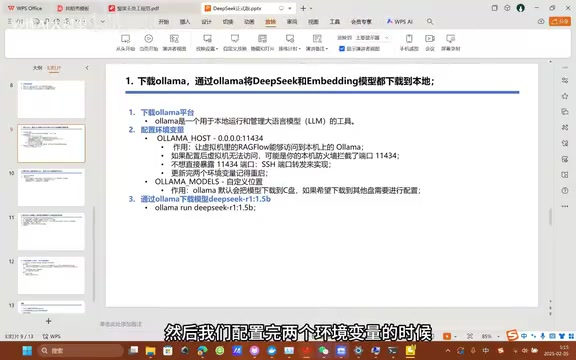
重要提醒:配置完环境变量后一定要重启电脑! 否则新配置不会生效,后续步骤会出错。
重启后,打开命令行(CMD或PowerShell)执行以下命令下载并运行DeepSeek:
ollama run deepseek-r1:1.5b
如果模型能正常响应你的消息,说明DeepSeek本地部署成功。
模型参数量(1.5B、14B、32B中的B代表Billion,即十亿)直接决定了模型能力和硬件需求。参数量本质上代表模型中可学习权重的数量——参数越多,模型能够编码的知识和推理模式越丰富,但所需的显存和计算资源也成比例增长。具体来说:1.5B模型约需2-3GB显存,普通集成显卡或CPU即可运行;14B模型约需10-12GB显存,需要中高端独立显卡(如RTX 3080/4070);32B模型约需20GB以上显存,通常需要专业级显卡或多卡并行。如果显存不足,Ollama会自动将部分层卸载到内存甚至硬盘运行,但速度会大幅下降。建议先从1.5B参数量的小模型开始测试,确认流程跑通后,有独立显卡的用户可以尝试14B或32B版本以获得更好的回答质量。
第二步:通过Docker部署RAGFlow
RAGFlow是一款开源的RAG引擎,提供了完整的知识库管理和智能问答功能。部署RAGFlow需要两样东西:RAGFlow源代码和Docker Desktop。
下载RAGFlow源代码: 访问GitHub搜索"RAGFlow
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。