Ollama本地部署大模型教程:安装配置到API调用全流程
使用Ollama在本地部署和运行开源大模型的完整指南
本文介绍了本地部署大模型的核心价值(数据隐私、降本、低延迟、消除外部依赖),重点讲解了Ollama这一最简便的本地大模型运行框架。内容涵盖Ollama的安装方法、常用命令、模型选择与量化策略(推荐Q4量化作为最佳平衡点),以及如何通过Python代码调用本地模型API,实现本地与云端模型的灵活切换。
为什么要在本地部署大模型?
在前面的系列课程中,我们已经系统学习了Python调用大模型API、流式响应、提示词工程、RAG知识库、Function Calling、Agent以及MCP协议等核心概念。但之前所有的示例都依赖于外部大模型服务(如DeepSeek等),今天我们要解决一个关键问题——如何用Ollama在本地运行开源大模型。
本地部署大模型主要有以下几个核心场景:
- 数据隐私保护:医院、律师事务所、企业内部文档等涉及机密数据,不能发送到第三方API,否则存在数据泄露风险
- 批量处理降本:大量简单任务调用外部API成本极高,本地跑一晚上只需要电费,效果却差不多
- 降低推理延迟:省去与外部大模型之间的网络往返延迟,本地GPU推理响应非常快
- 消除外部依赖:不再受限于厂商的限速、服务不可用、涨价等问题
- 深入理解模型原理:对模型参数、量化、内存占用等有直观认识,是学习AI的绝佳方式
Ollama是什么?最简单的本地大模型运行框架
为什么选择Ollama
Ollama之于本地大模型,就像Docker之于容器化部署——上手极其简单。这个类比不只是风格上的相似:Ollama借鉴了容器化部署的核心理念,将模型运行环境、依赖库和推理引擎打包为统一的可分发单元。其底层基于 llama.cpp 推理引擎,支持CPU的AVX2/AVX512指令集加速,以及NVIDIA CUDA、Apple Metal、AMD ROCm等多种GPU后端,实现了跨硬件平台的统一调用接口——这正是它能做到"一条命令跑模型"的技术基础。Ollama支持跨平台运行(macOS、Linux、Windows),安装和使用都非常方便,是目前最流行的本地大模型运行工具之一。
Ollama安装方法
不同操作系统的安装方式如下:
- macOS:直接执行
brew install ollama - Windows/Linux:到 Ollama官网 下载对应安装包
安装完成后,Ollama会作为后台服务启动,默认监听地址为 localhost:11434。
局域网共享提示:如果你想把本地模型服务分享给局域网内的同事使用,可以将监听地址改为
0.0.0.0,否则只能在本机访问。
Ollama常用命令速查表
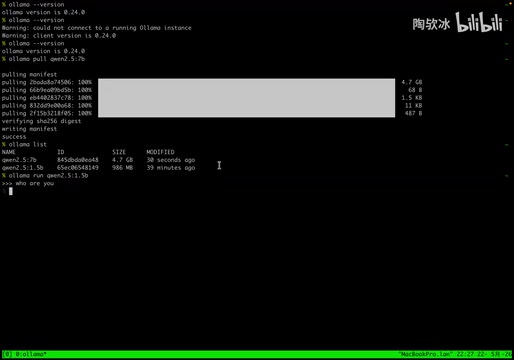
# 查看版本
ollama --version
# 手动启动服务
ollama serve
# 拉取模型
ollama pull qwen2.5:7b
# 运行模型(如未下载会自动拉取)
ollama run qwen2.5:1.5b
# 列出已下载的模型
ollama list
# 删除模型
ollama rm 模型名称
模型文件默认存储在用户目录下的 ~/.ollama/models 路径中。Ollama使用的模型格式为 GGUF(GPT-Generated Unified Format),这是由 llama.cpp 项目发展而来的主流量化格式,支持CPU与GPU混合推理,已成为本地部署生态的事实标准。
启动Ollama服务并验证
如果Ollama没有自动以服务形式启动,可以手动执行 ollama serve。启动后可以通过以下方式验证服务是否正常运行:
# 方式一:curl请求
curl http://localhost:11434
# 方式二:查看版本(会连接运行中的实例)
ollama --version
如果服务未启动,执行 --version 会提示"不能连接到正在运行的Ollama实例"。注意:如果是手动启动的服务,终端窗口不要关闭。
模型选择与量化策略详解
根据硬件配置选择合适的模型
选择模型时必须考虑你的电脑配置,以下是4比特量化后的参考建议:
| 内存 | 推荐模型规模 | 示例 |
|---|---|---|
| 16GB | 7B及以下 | Qwen2.5:7B |
| 32GB(M系列Mac) | 13B | Llama3:13B |
| 128GB+(Ultra系列) | 72B | Qwen2.5:72B |
即使没有独立GPU也没关系,Ollama可以在纯CPU上运行,Token输出速度大约每秒5-10个词,虽然不快但完全可用。
理解模型量化:用精度换空间
量化的本质是将模型权重从16比特浮点数降低到4比特或8比特整数,以精度损失换取内存占用的大幅降低。这一技术起源于深度学习模型压缩领域:现代大语言模型动辄数十亿参数,以FP16精度存储一个7B参数模型需要约14GB内存,这对消费级硬件极不友好。量化通过将连续的浮点数值映射到有限的整数区间,将每个参数的存储空间压缩数倍,使得在普通笔记本上运行高质量模型成为可能。不同量化方案在压缩率和精度损失之间存在明确的权衡关系。
以Qwen2.5:7B模型为例,不同量化级别的对比:
| 量化级别 | 说明 | 文件大小 | 特点 |
|---|---|---|---|
| Q2 | 2比特量化 | ~2.3GB | 极致压缩,智力下降严重 |
| Q3 | 3比特量化 | ~3GB | 可接受的最低质量 |
| Q4 | 4比特量化 | ~4GB | 质量与体积的最佳平衡点 |
| Q8 | 8比特量化 | ~7GB | 接近原始精度 |
| FP16 | 原始精度 | ~14GB | 无损,占用最大 |
指定量化级别的方式是在模型名后添加标签,例如:
ollama pull qwen2.5:7b-q8_0
对于大多数开发者来说,Q4量化是性价比最高的选择,在保持较好推理质量的同时大幅降低了内存需求。
Python代码调用Ollama本地模型API
部署好Ollama后,可以直接在Python代码中通过API调用本地模型,方式与调用外部大模型API几乎一致——只需将API地址指向 localhost:11434。
一个实用的技巧是通过环境变量来灵活切换本地模型和云端模型:
import os
# 通过环境变量切换本地/远程模型
if os.getenv("USE_LOCAL_MODEL"):
base_url = "http://localhost:11434"
model = "qwen2.5:7b"
else:
base_url = "https://api.deepseek.com"
model = "deepseek-chat\
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。