编程Agent反馈循环:失败如何变成修正的养分

被低估的Agent核心能力
如果让你评价一个AI编程工具,你的标准是什么?大多数人会看它第一次能不能把代码写对。但这个标准其实问错了问题。
真正分高下的,不是第一次写对的概率,而是写错之后能不能自己看到错、找到错、修掉错。这一件事直接决定了你手里的工具到底是个代码生成器,还是一个真正的编程Agent。


打破误解:失败不是事故,是营养
一击必杀的幻觉
我们总觉得好的AI应该一次就写对。但回想真实的开发场景——哪怕是资深工程师,也是改了又改、跑了又跑才搞定的。一个死板的代码生成器追求一击必杀,对它来说失败就是产品事故:吐给你一段错的代码,你拿到手一看不对,扭头就走了,没有第二次机会。
但真实的开发从来不是一击必杀的游戏。
报错是来给你指路的
真实的开发现场长什么样?遍地都是报错:测试不通过、类型检查飘红、Lint报错、编译失败、运行时异常、接口字段对不上、页面白屏、依赖版本冲突……这些东西每天都在发生。
对人类工程师来说这是日常,关键在于:每一条失败信息其实都在告诉你——你刚才那一步的认知和环境的真实状态之间有偏差,而且偏差具体就在这里。
换句话说,报错不是来骂你的,它是来给你指路的。问题只是你的Agent听不听得懂这句话。
两种视角的根本差异
同样一条报错:
- 在代码生成器眼里是垃圾——一次性交付失败了,这是个产品bug,要扔掉的
- 在编程Agent眼里是养分——任务还没完成,失败只是中间状态,是判断下一步该往哪走的宝贵信号
这个视角的不同,就是一切的起点。
反馈循环的结构:观察→行动→再观察
反馈循环的核心结构可以用三个字概括:观察→行动→再观察。
展开来说是五步:感知→决策→行动→反馈→再感知,然后转成一个圈。这对应通用Agent理论里的ReAct模式(也叫Observe-Reflect),名字不重要,核心永远是同一件事:每做一步都要把这一步的反馈拉回来,当作下一步的输入。
ReAct(Reasoning + Acting)是2022年由普林斯顿大学和Google Brain联合提出的Agent推理范式。它的核心突破在于让大语言模型交替进行"思考"和"行动"两个步骤:先用自然语言推理当前状态和下一步计划(Thought),再执行具体操作(Action),然后观察操作结果(Observation),形成完整的闭环。在此之前,主流的Chain-of-Thought方法只关注推理链条本身,缺乏与外部环境的交互能力,容易产生"幻觉"式的推理偏差。ReAct通过引入外部反馈,让模型不再是一次性输出最终答案,而是像人类一样边做边想、边想边调整,有效缓解了纯推理的漂移问题。
不是闷头一路往前冲,而是走一步看一眼再决定下一步。这个"看一眼"就是整个反馈循环的灵魂。
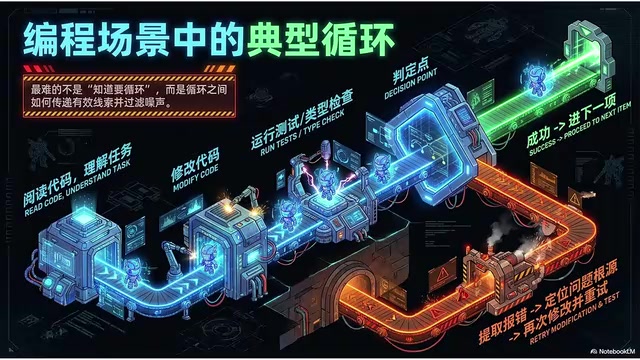
落到编程场景的具体流程
- 读相关代码,理解任务
- 改一处代码
- 跑测试或类型检查
- 判定点:看输出——通过就进下一项,失败就看报错
- 顺着报错回到代码,定位问题
- 再改一次
- 再跑一次
就这么循环,直到通过或者达到上限主动放弃。失败不是终点,而是一条回流的轨道,把它送回去重来。
四道大关:反馈循环的真正难点
反馈循环绝不是写个while循环套一层"失败就再来一次"那么简单。它是一个高度工程化的子系统,前面有四道大关挡着,每一道都能让一个看似聪明的Agent当场翻车。
第一关:上下文爆炸
跑一次测试,输出可能是几千几万行日志。如果Agent把这一大坨原封不动塞回模型,上下文瞬间就爆了——token花光了,重点也淹没了。
这里涉及大语言模型的一个核心限制:上下文窗口(Context Window)。它是指模型单次推理能处理的最大文本长度,以Token为单位衡量——GPT-4 Turbo为128K tokens,Claude 3.5为200K tokens。但上下文窗口并非越大越好。一方面,Token消耗直接关联API调用成本,每次将大量日志塞入上下文意味着真金白银的支出;另一方面,研究表明模型在处理超长上下文时存在"中间遗忘"(Lost in the Middle)现象——位于输入中段的信息往往被模型忽略。这意味着即使上下文窗口装得下全部日志,关键的报错信息也可能被淹没在中间位置而被模型"视而不见"。
所以它必须会做一件事:从日志洪流里精准捞出关键的那几条。到底是哪一个测试用例失败了?报错栈顶是哪个文件哪一行?关键的变量值是多少?把这几条留下,剩下的噪声果断丢掉。
会摘重点的Agent和把日志一股脑全塞回去的Agent,差的不是一点半点。
第二关:真假病因
这一关最考验功力。报错堆栈给你指的那个位置,很多时候只是症状,不是病根。
打个比方:错误抛在某个工具函数里,红光闪在那,可真正的bug其实是上游的调用方传错了参数。一个差的Agent会盯着亮红光的地方一通乱改,结果改的是症状,病根还在,越改越乱。而一个好的Agent懂得顺着报错堆栈往回追溯,一层一层traceback,找到那个真正该动手的地方。
这种能力在软件工程中对应一套成熟的方法论——根因分析(Root Cause Analysis, RCA)。经典的RCA方法包括"五个为什么"(5 Whys):对每一个表面原因追问"为什么会这样",连续追问五层,通常就能触及真正的根因。在调试场景中,错误堆栈(Stack Trace)是最重要的线索来源:堆栈顶部显示的是异常抛出的位置,但真正的bug往往隐藏在堆栈的中下层——即调用链的上游。对于AI Agent而言,这要求模型不仅能读懂单个文件的代码,还要具备跨文件、跨模块的调用链追踪能力,理解数据流在整个系统中的流转路径,才能从"看到症状"升级为"找到病根"。
会区分症状和根因,是从"会改代码"到"会修bug"的分水岭。
第三关:打破死循环
这是反馈循环里最典型的翻车现场:改一处过了,又弄坏另一处;再改回来,结果破坏了第三处。来来回回就像拆东墙补西墙,永远停不下来。这种状态叫抖动。
"抖动"(Oscillation)现象在控制论(Cybernetics)中有着深厚的理论基础。经典的PID控制器设计中,如果反馈增益设置不当,系统就会在目标值附近来回震荡,永远无法收敛到稳态。类似地,在强化学习领域,Agent在相似状态间反复切换策略的现象被称为"策略震荡"(Policy Oscillation)。编程Agent的抖动本质上是同一类问题:每次局部修复都改变了系统状态,导致之前的修复失效,形成循环依赖。理解这一点很重要——抖动不是Agent"笨",而是它缺乏对全局状态变化的感知能力,只看到了局部的因果关系。
一个差的Agent会一直困在里面出不来,烧钱烧到你心疼。而一个好的Agent得有自我觉察的能力——意识到"我好像在原地反复打转了",然后主动跳出这个循环,回到上一层的规划,重新审视是不是对问题的整个理解从一开始就错了。这种"元认知"机制要求Agent不仅关注当前的报错,还要维护一个修改历史的记忆,检测自己是否在重复相同的修改模式。
能跳出来,比埋头硬修重要得多。
第四关:知止——知道什么时候该停
一个有反馈循环的Agent,如果一根筋地认为"只要不停重试总能修好",那就危险了。它可能在你不知情的情况下跑了几十次shell、改了几十遍代码,钱哗哗地烧,问题还没解决。
所以它必须有刹车:循环次数、消耗上限、花多长时间——三条预算只要任何一条到顶就停下来,老老实实向人类求助。
真正成熟的Agent不是永不放弃,而是知道在什么时候把方向盘交回给你。会停,也是一种能力。
真实案例:好坏循环的对比
假设任务是修复一个一直失败的测试 test_login_redirect。
差的反馈循环
跑测试失败→模型一拍脑袋"可能是redirect URL错了"→改一行→再跑还失败→"那可能是token没传"→又改一行→几轮下来每改一次引入一个新问题→最后甩给你一句"我试了几个方案都没成,你自己看吧"。
这是典型的猜→试→再猜→再试。
好的反馈循环
跑测试失败→不急着改,先把报错栈顶定位到具体文件和行号→读懂那段代码是被谁调用的→再看测试到底期望什么→发现期望跳转是/dashboard,实际却跳到了/home→去搜redirect配置在哪→找到一个最近被改过的常量→改掉它→再跑→通过→最后顺手把相关测试也跑一遍,确认没碰坏别的场景。
一个是"猜",一个是读→定位→理解→修改→验证→连带验证。差距一目了然。
工程延伸:两个实践建议
反馈质量决定循环质量
反馈循环的质量强依赖工具反馈本身的质量。如果你项目的报错信息很烂、日志写得乱七八糟、错误码什么都不说明,那Agent的反馈循环再聪明也救不了——它根本读不到有用的线索。
所以反过来,想让编程Agent表现更好,一个特别实在的办法是提升项目自身的可观测性:更清楚的报错、更有信息量的日志、更规范的失败输出。这件事对人对Agent都是好事。
可观测性(Observability)是近年来从分布式系统运维领域兴起的核心概念,由三大支柱构成:日志(Logs)、指标(Metrics)和链路追踪(Traces)。Google的SRE实践和CNCF的OpenTelemetry项目都在推动可观测性的标准化。对于编程Agent而言,项目的可观测性水平直接决定了反馈循环的天花板。具体来说:结构化日志(如JSON格式)比自由文本日志更容易被Agent解析和提取关键信息;明确的错误码体系(如HTTP状态码那样有清晰语义的编码)比模糊的"Something went wrong"提供更多诊断信息;完善的测试覆盖率意味着更多的自动化验证点,Agent每改一处代码都能立刻获得反馈。这也解释了为什么编程Agent在成熟的开源项目上表现通常优于内部遗留系统——前者往往有更好的工程规范和更丰富的反馈信号。
反馈循环必须跟权限边界绑死
一个能自动重试的Agent,万一觉得"再跑几次就好了",可能在你不知情时疯狂跑shell、反复改代码。所以它得有边界:循环次数、消耗上限、关键操作必须人来确认。自动化的能力越强,安全边界就越重要。
总结:从一击必杀到慢慢磨
反馈循环的结构很简单——观察、行动、再观察。它的难点很现实——上下文管理、错误定位、避免抖动、知道何时停下。但它的价值极大:它让Agent第一次能在不确定的真实环境里推进任务,而不只是赌那一次输出。
说白了,反馈循环就是把编程Agent从"只能一击必杀"升级成了"可以慢慢磨"。能磨,它能处理的问题就一下子变大了:
- 简单任务:一次搞定
- 中等任务:几轮反馈完成
- 复杂任务:多轮试错、多次回退,但仍然能磨到一个可交付的状态
这才是真正的编程Agent与代码生成器之间的本质区别。
相关推荐
Mistral Le Chat图像生成功能评测:能否替代Fable?
Mistral AI为Le Chat聊天助手推出图像生成功能,社区称其为Le Chaton Fat(胖小猫)。本文分析Le Chat图像生成能力、与Fable的竞争对比,以及AI聊天平台集成图像生成的行业趋势。
实测DeepSeek安全机制:多种越狱手段均被成功拦截
海外安全博主对DeepSeek进行系统性越狱测试,通过直接请求、变换措辞、不同提示策略等多种手段尝试突破安全防线。测试结果显示DeepSeek安全机制具备意图识别、一致性拦截和上下文感知能力,在防护与可用性之间取得良好平衡。
零基础初中生用AI做出剧情游戏:创造力不再被技术绑架
一位编程零基础的初中生借助AI工具生成了一款互动剧情游戏,包含分支选择和荒诞外星冒险。本文拆解这款游戏的内容设计,探讨AI降低创作门槛的意义、当前局限性以及AI辅助游戏创作的未来趋势。