Browser-Use WebUI安装配置教程:AI浏览器自动化实战

Browser-Use WebUI:用自然语言驱动AI自动操控浏览器的开源工具
Browser-Use WebUI是基于开源项目Browser-Use打造的可视化浏览器自动化工具,通过LLM与Playwright引擎结合,用户只需用自然语言描述任务,AI即可自动完成表单填写、内容总结、数据采集等网页操作。它支持Gemini、DeepSeek等多种模型,上手门槛低,应用场景广泛,是2025年AI Agent生态中的关键工具。
前言
2025年AI Agent赛道持续火热,浏览器自动化已经成为Agent生态中绕不开的关键能力。不管是自动填表单、抓取数据,还是执行一连串复杂的网页操作,AI驱动的浏览器自动化工具正在重新定义我们和互联网打交道的方式。
AI Agent(智能体)是指能够感知环境、自主决策并执行动作以达成目标的AI系统。与传统的对话式AI不同,Agent具备"行动力"——它不仅能生成文本回答,还能调用工具、操作软件、与外部系统交互。2025年,OpenAI、Google、Anthropic等头部公司纷纷将Agent能力作为核心战略方向,Agent框架(如LangChain、AutoGPT、CrewAI)的生态也在快速成熟。浏览器自动化是Agent能力中最具实用价值的方向之一,因为互联网上承载了绝大多数人类的工作流程——从信息检索、数据录入到在线交易,几乎所有业务都可以通过浏览器完成。
本文要聊的 Browser-Use WebUI,是基于GitHub上热门开源项目 Browser-Use 打造的可视化界面版本。它把原本需要写代码才能搞定的浏览器自动化,变成了"打字聊天"一样简单的事——用自然语言描述你想做什么,AI就能在浏览器里帮你自动完成。
Browser-Use WebUI 是什么
Browser-Use 是一个在GitHub上获得大量Star的开源项目,核心能力是让AI模型直接操控浏览器执行各类任务。官方仓库里展示了不少亮眼的用例:
- 自动求职:读取简历内容,搜索机器学习相关岗位,保存结果并自动投递申请
- 航班查询:在旅行网站上自动搜索飞往目标城市的航班信息
- 数据采集:在HuggingFace上按许可证类型筛选模型,按热度排序后保存前五名
从技术架构来看,Browser-Use的核心建立在大语言模型(LLM)与Playwright浏览器自动化引擎的结合之上。其工作原理可以概括为一个"感知-决策-执行"的循环:首先,系统通过Playwright获取当前网页的DOM结构和可交互元素,并将这些信息(有时还包括页面截图)作为上下文传递给LLM;然后,LLM根据用户的自然语言指令和当前页面状态,决定下一步应该执行什么操作(如点击某个按钮、在输入框中填入文字、滚动页面等);最后,系统将LLM的决策转化为Playwright的具体API调用,在浏览器中执行对应操作。这个循环会持续进行,直到任务完成或达到最大步数限制。
Browser-Use WebUI 在此基础上封装了一套简洁的图形界面,支持接入多种AI模型——包括 Gemini(免费且支持视觉能力)和 DeepSeek(性价比高)等,把使用门槛拉到了很低的水平。
四个实战场景演示
场景一:自动填写网页表单
第一个任务是让AI自动打开一个 Waitlist 注册页面并填写用户信息。这个页面通过 Rapidata Agent 搭建,后台已有两条测试数据。
实际操作非常顺畅:点击「Run Agent」后,浏览器自动打开目标页面,AI在页面上用不同颜色的框标注出所有可交互元素,然后依次填入姓名、邮箱等字段,最后自动点击「加入Waitlist」按钮。回到后台刷新,新提交的数据已经成功入库。
这里值得展开说明的是AI标注可交互元素的技术细节。系统会对当前页面进行DOM解析,提取所有可交互的HTML元素(如按钮、链接、输入框、下拉菜单等),为每个元素分配一个唯一编号,并在页面上用彩色边框进行可视化标注。这些标注信息会被整理成结构化的文本描述(例如"[1] 输入框: 姓名, [2] 输入框: 邮箱, [3] 按钮: 提交"),连同页面截图一起发送给LLM。LLM只需要回复类似"点击元素[3]"或"在元素[1]中输入'张三'"这样的指令,系统就能精确定位并操作对应的页面元素。这种设计巧妙地将复杂的网页操作转化为了LLM擅长处理的文本推理问题。
这个场景充分展示了Browser-Use在表单自动化方面的实力,批量注册、数据录入等重复性工作用它来处理再合适不过。
场景二:网页内容自动总结
第二个任务是让AI打开 Sam Altman 的博客,总结最新文章的核心要点。
AI准确定位到了当天Sam发布的最新博文,并对文章各部分做了颜色区分标注。终端日志显示AI抓取了完整的博文内容(篇幅相当长),最终输出了一份结构清晰的要点总结。

这个场景体现了Browser-Use在信息提取和内容理解上的价值,日常的资讯监控、快速阅读场景都能派上用场。
场景三:视频搜索与播放
第三个测试是让AI在B站搜索指定用户ID,点击搜索结果中的第一个视频并播放。AI顺利完成了搜索和定位,成功找到目标视频并点击了第一条结果。不过由于当前浏览器环境不支持H5播放器,视频没能成功播放——这也暴露了自动化工具在特定运行环境下的局限性。
这种局限性与底层的Playwright引擎有关。Playwright是由微软开发并开源的现代浏览器自动化框架,支持Chromium、Firefox和WebKit三大浏览器内核。相比早期的Selenium,Playwright在速度、稳定性和现代Web特性支持方面有显著优势——它原生支持自动等待机制(无需手动设置sleep)、支持多标签页和iframe操作、能拦截和模拟网络请求,还内置了截图和录屏功能。然而,Playwright启动的浏览器实例通常运行在无头(headless)或受限模式下,某些依赖特定浏览器插件或硬件加速的功能(如视频的H5播放器)可能无法正常工作。
场景四:电商数据采集(不同模型对比)
最后一个任务难度更高:打开亚马逊,搜索蓝牙耳机,抓取搜索结果前五个商品的标题和价格。
这里出现了值得关注的模型表现差异:
- DeepSeek 模型:执行该任务时报错失败
- Gemini 模型:能够持续推进操作,在浏览器中可以看到它不断交互的过程
这种差异背后有深层的技术原因。Gemini是Google推出的多模态大语言模型系列,其核心优势在于原生的视觉理解能力——它不仅能处理文本,还能直接"看懂"网页截图,这对于浏览器自动化场景尤为重要,因为有些页面元素的语义仅从DOM结构难以准确判断,而视觉信息能提供关键补充。DeepSeek则是国内深度求索公司推出的高性价比模型,其API价格远低于GPT-4等商业模型,在推理能力上表现出色,但在多模态(尤其是视觉)能力上相对Gemini有所不足。亚马逊的商品搜索结果页面布局复杂,包含大量广告位、推荐卡片和动态加载内容,视觉能力在理解商品卡片、价格标签等视觉密集型元素时提供了额外的信息维度,这也解释了为什么Gemini在此任务中表现更优。
这说明不同AI模型处理复杂网页交互任务的能力确实有差距。根据任务特点选对模型,直接影响自动化的成功率。
模型与参数配置详解
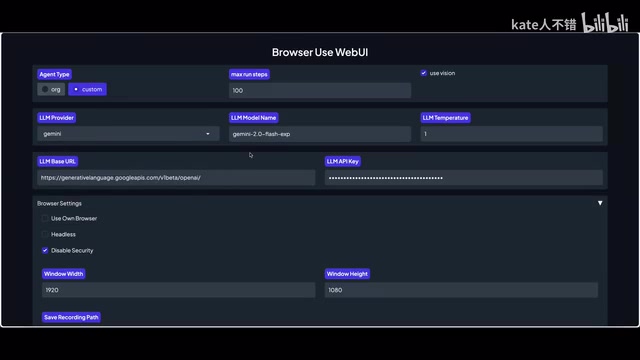
Gemini 模型配置
Browser-Use WebUI 支持多种 Agent Type。有一点需要注意:如果选择「Original」类型,可能会提示某个 JSON 文件缺失(和Google认证机制有关)。碰到这种情况,建议把 Agent Type 切换为**自定义(Custom)**即可解决。
还有一个常见坑:在 Edge 浏览器中使用时,如果勾选了「使用自己的浏览器」选项,可能会出错。解决办法很简单——取消勾选该选项,让工具使用自带的浏览器实例。
DeepSeek 模型配置
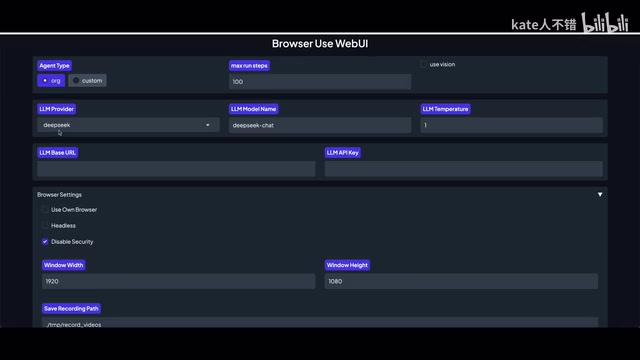
DeepSeek 的配置步骤比较简单:
- Agent Type 选择「Original」
- 模型选择 DeepSeek
- Base URL 保持默认的 Endpoint 地址
- API Key 需要在项目根目录的
.env文件中填写
关于 .env 文件:项目自带一个 .env.example 示例文件,把文件名里的 .example 去掉,填入你自己的 API Key 就行。.env 文件是一种在软件开发中广泛使用的环境变量配置方式,它将敏感信息(如API密钥、数据库密码等)与代码分离,避免将密钥硬编码在源代码中或意外提交到版本控制系统。
安装部署完整步骤
下面是基于 Conda 环境安装 Browser-Use WebUI 的完整流程:
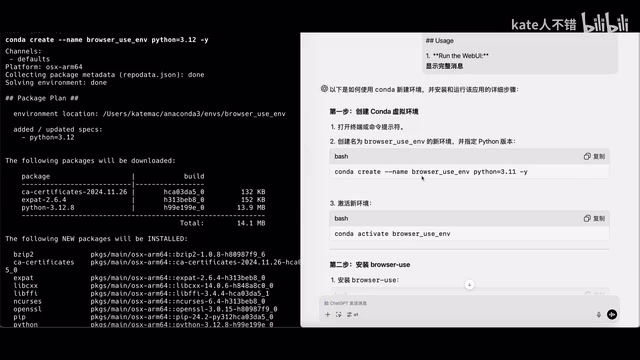
第一步:创建Python虚拟环境
conda create -n browser-use python=3.12
conda activate browser-use
官方文档推荐 Python 3.11,但实测 3.12 同样可以正常运行。Conda是一个开源的包管理和环境管理系统,最初为Python开发,现已支持多种语言。使用Conda创建虚拟环境的好处是可以为每个项目隔离独立的Python版本和依赖包,避免不同项目之间的依赖冲突。
第二步:克隆仓库并安装依赖
git clone <仓库地址>
cd browser-use-webui
pip install -r requirements.txt
第三步:安装 Playwright 浏览器驱动
playwright install
这一步千万别漏掉! 很多人跳过这步直接启动WebUI,结果遇到报错。Playwright 是底层的浏览器自动化引擎,必须单独安装对应的浏览器驱动才能正常工作。执行 playwright install 命令后,系统会自动下载Chromium、Firefox和WebKit三个浏览器的二进制文件(总计约数百MB),这些是Playwright在后台启动和控制浏览器所必需的运行时组件,与你电脑上已安装的Chrome或Firefox浏览器是相互独立的。
第四步:配置API Key环境变量
cp .env.example .env
# 用编辑器打开 .env 文件,填入你的 API Key
第五步:启动 WebUI 服务
完成以上步骤后启动 WebUI,在浏览器中访问对应地址即可开始使用。
总结与展望
Browser-Use WebUI 是一款相当实用的AI浏览器自动化工具,核心优势体现在三个方面:
- 上手门槛低:图形化界面让不会写代码的用户也能轻松驾驭
- 模型选择灵活:支持 Gemini、DeepSeek 等多种模型,可以根据任务复杂度和预算自由搭配
- 应用场景广泛:从表单填写、内容总结到电商数据采集,覆盖了大量日常自动化需求
2025年被广泛认为是 Agent 元年,而浏览器自动化——不论是 Browser-Use 还是 Claude 的 Computer Use——都是 Agent 能力版图中的关键拼图。值得一提的是,Claude Computer Use是Anthropic在2024年底推出的计算机操控能力,它允许Claude模型直接控制整个桌面环境(不仅限于浏览器),通过截图识别屏幕内容并模拟鼠标和键盘操作。与Browser-Use基于DOM解析的精确操控不同,Computer Use更接近人类的操作方式——通过"看"屏幕来决定在哪里点击。两种方案各有优劣:DOM解析方式更精确、更快速,但依赖于网页结构的可解析性;视觉操控方式更通用,理论上能操作任何图形界面应用,但准确率和速度相对较低。目前行业中还有Microsoft的UFO、Google的Project Mariner等类似项目,浏览器与计算机自动化正在成为AI Agent领域竞争最激烈的赛道之一。
尽早掌握这类工具,能帮助我们构建更复杂的自动化工作流,真正把AI的生产力释放出来。
相关推荐
 教程攻略
教程攻略Cursor+Codex双IDE协同:开源项目二开实战方法论
基于实战经验总结的开源项目二次开发完整方法论,详解Cursor+Codex双IDE协同工作流,涵盖二开七环节、MVP验证、AI读源码技巧,帮助开发者三天跑通项目、两周完成业务集成。
 教程攻略
教程攻略Cursor多Agent实战:50分钟搭建Next.js全栈博客
使用Cursor IDE多Agent协作模式,50分钟内从零搭建全栈博客。涵盖Next.js、Clerk认证、Supabase数据库集成,详解4个AI Agent分阶段开发流程与关键避坑经验。
 教程攻略
教程攻略从零搭建AI软件工厂:Cursor工程师的多Agent协作实战经验
Cursor工程师Eric分享AI软件工厂构建实战:从自动化六层级、护栏设计、并行Agent管理到规模化扩展,详解如何用多Agent协作实现7×24小时高效软件开发。