Claude 4.5 Haiku实测翻车:编码能力全面溃败,性价比被竞品碾压

Claude 4.5 Haiku实测表现远逊于官方宣传,性价比被竞品全面碾压。
Anthropic发布的Claude 4.5 Haiku号称以三分之一成本提供接近Sonnet 4的编码性能,但独立测试显示其在SVG生成、3D渲染、编码代理等任务中全面溃败,综合排名跌至第34-37位。与GLM 4.6、GPT-5 Mini等竞品相比,Claude 4.5 Haiku价格更高但性能更差,暴露出Anthropic可能陷入基准测试优化陷阱、官方宣传与实际表现严重脱节的深层问题。
Anthropic刚刚发布了Claude 4.5 Haiku,官方宣称这是一款"更便宜、更快"的模型,能以三分之一的成本提供接近Sonnet 4的编码性能。然而,来自独立测试者的实测结果却令人大跌眼镜——这可能是近期主流AI实验室发布的最差模型之一。
官方宣传与现实的巨大落差
Anthropic在发布公告中表示:"五个月前,Claude Sonnet 4还是最先进的模型。如今,Claude Haiku 4.5能提供类似水平的编码性能,但成本仅为三分之一,速度快两倍以上。"他们将其定位为Sonnet 4的低成本替代品,可以在Claude Code和各类应用中作为直接替换方案。
值得一提的是,Anthropic的模型命名体系借用了文学术语:Opus(大型作品)、Sonnet(十四行诗)、Haiku(俳句),暗示模型规模的递减关系。Haiku作为最轻量的模型层级,对应的是参数量最小、推理速度最快、成本最低的产品。这种分层策略在行业中非常普遍——OpenAI有GPT-4o与GPT-4o mini,Google有Gemini Pro与Gemini Flash——核心逻辑是大量日常任务并不需要最强大的模型,使用轻量模型即可大幅降低API调用成本。
这听起来很美好,但实测结果却讲述了一个完全不同的故事。
基础能力测试:Claude 4.5 Haiku全面溃败
测试者对Claude 4.5 Haiku进行了一系列标准化的生成任务测试,结果几乎在每个维度上都令人失望。
平面图生成方面,模型生成的楼层平面图从任何角度看都不合理,墙壁位置混乱,对于一个号称达到Sonnet 4水平的模型来说,这样的表现完全不可接受。
SVG图形生成中,要求生成一只拿着汉堡的熊猫,虽然勉强能看出是熊猫的形状,但布局和细节处理非常糟糕。SVG(Scalable Vector Graphics,可缩放矢量图形)是一种基于XML的图像格式,用代码描述图形的形状、颜色和位置。这类测试之所以被广泛采用,是因为它同时考察了语言理解(理解"熊猫拿着汉堡"的语义)、空间认知(各部件的相对位置和比例)和代码生成(输出合法的SVG坐标与路径指令)三重能力,是衡量模型综合素质的有效试金石。
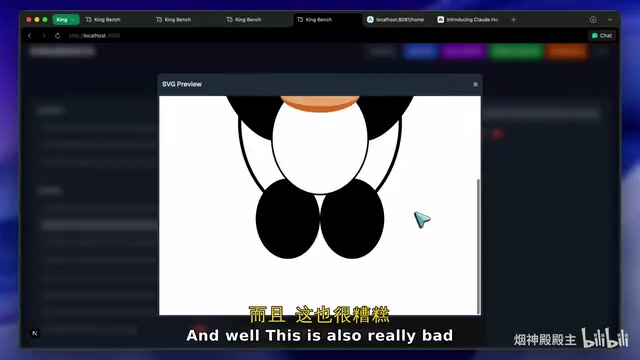
3D渲染任务(3JS精灵球)同样表现不佳。Three.js(简称3JS)是一个基于WebGL的JavaScript 3D图形库,广泛用于在浏览器中创建和展示3D内容。要求AI模型生成3JS代码来渲染精灵球等3D物体,测试的是模型对三维几何、材质系统、光照模型和场景构建的综合理解能力——模型不仅要生成语法正确的JavaScript代码,还需要正确设置相机位置、光源参数、几何体的顶点数据和材质属性,任何一个环节出错都会导致渲染失败或视觉效果异常。
棋盘生成、Web版Minecraft等测试同样令人失望。CLI工具和Blender脚本甚至无法运行。唯一勉强过关的是"花园中的蝴蝶"场景,但也只是"还行"的水平,毫无亮点。
在综合排名中,Claude 4.5 Haiku分别排在第34和第37位——这使它成为主流AI实验室新一代模型中得分最低的一个。测试者表示,这些测试反复运行了超过五次,结果始终如此。
代理编码测试:Claude Code实际表现同样拉胯
既然基础测试不行,那作为编码代理(Agentic Coding)表现如何?代理编码是当前AI编程领域最前沿的应用范式。与传统的代码补全不同,代理编码要求AI模型像一个自主的软件工程师一样工作:理解项目需求,自主规划实现步骤,编写代码,运行测试,发现错误后自主调试修复,甚至能操作终端命令和文件系统。这种模式对模型的要求极高——不仅需要强大的代码生成能力,还需要长上下文理解、多步推理、错误诊断和工具调用等综合能力。
测试者使用Anthropic官方的Claude Code(一款允许开发者在命令行中与Claude交互、让模型直接在本地代码库中进行修改的代理编码工具)进行了多项实际编码任务测试:
- Movie Tracker应用:直接报404错误,页面都无法显示
- Go Terminal Calculator:产生大量错误,布局混乱
- Godot游戏开发:到处是错误提示。Godot是一款开源的跨平台游戏引擎,使用自有的GDScript脚本语言(语法类似Python),近年来因其轻量、免费和社区活跃而迅速崛起。AI辅助Godot开发是一个极具挑战性的测试场景,因为GDScript在主流编程语言中属于小众,训练数据相对稀缺,能否正确生成Godot项目代码反映了模型对长尾编程语言的覆盖程度。
- OpenCode仓库:表现极差
- Svelte、Nuxt、Tauri框架:全部表现糟糕。这三个框架代表了现代Web和桌面应用开发的前沿技术栈——Svelte是编译时前端框架,在构建阶段将组件编译为高效的原生JavaScript,运行时开销极小;Nuxt是基于Vue.js的全栈框架,提供服务端渲染和静态站点生成等企业级功能;Tauri则是Electron的轻量替代品,使用Rust作为后端构建跨平台桌面应用,打包体积仅为Electron的十分之一。模型在这些主流框架上的表现直接关系到其在现代开发工作流中的实用价值。

对于一个被定位为"Sonnet 4直接替代品"的模型来说,这样的编码代理表现几乎是不可接受的。它不仅没有达到Sonnet 4的水平,甚至可能是目前表现最差的AI编码代理之一。
Anthropic的产品线困境:缺少轻量级模型
从产品线角度来看,Anthropic目前有三个模型层级:Opus、Sonnet和Haiku。对标OpenAI的话,Sonnet大致对应GPT-5,Haiku对应GPT-5 Mini。但Anthropic缺少一个类似GPT-5 Nano的超轻量级模型。
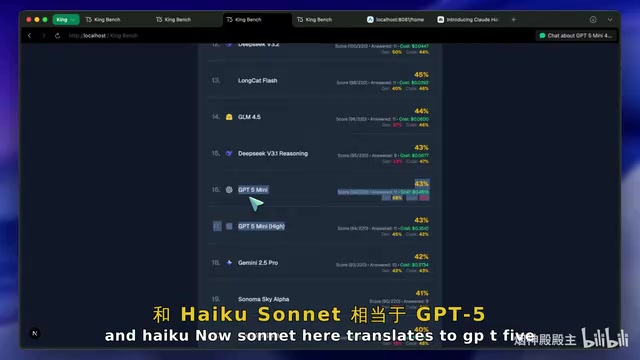
这个产品线缺口意味着,很多企业用于文本摘要、数据结构化等轻量任务时,要么用价格偏高的Haiku,要么转向其他厂商。Claude 4.5 Haiku似乎就是为了填补这个市场空白而推出的——它更多是面向企业API用户,而非消费者。
性价比对比:GPT-5 Mini和GLM 4.6全面碾压
从价格角度来看,Claude 4.5 Haiku的性价比问题更加突出。以GLM 4.6为例,其输入输出token价格约为每百万$0.5至$1.75,而Claude 4.5 Haiku的价格大约是其三倍。然而在实际性能上,GLM 4.6的表现却远远优于Claude 4.5 Haiku。
测试者推荐的替代方案包括:
- GLM 4.6:性价比极高,性能远超Claude 4.5 Haiku
- GPT-5 Mini:在同类测试中表现"碾压级"优于Claude 4.5 Haiku
- Grok CodeFast:价格更低,编码能力更强
对于预算有限的开发者来说,这三个替代方案在性能和成本上都是更合理的选择。
深层问题:Anthropic是否在走下坡路?
测试者提出了一个尖锐但值得思考的观点:Claude 3.5 Sonnet可能是Anthropic的一次"幸运一击"。那个模型凭借某种训练数据的组合,在编码领域表现异常出色。但此后的迭代——Sonnet 3.7(本质上是加了推理的同一模型)、Sonnet 4(改进有限)、Sonnet 4.5(多个领域退步)——都没有实现真正的突破。
更深层的担忧在于:随着Anthropic规模扩大、追求企业市场和估值增长,他们可能正在陷入"基准测试优化"的陷阱。这种现象在AI行业中被称为"刷榜"或"teaching to the test",其核心机制是:当模型开发者过度关注特定基准测试的得分时,可能会有意或无意地让模型在训练过程中接触到与测试题目高度相似的数据,或者针对测试的评分标准进行特定优化,导致模型在基准测试上得分虚高,但在真实世界的开放性任务中表现平庸。学术界将这种现象称为"Goodhart定律"——当一个指标变成目标时,它就不再是一个好的指标。近年来,多个研究团队已经发现主流模型在经典基准测试上的得分提升速度远超其在实际应用中的能力增长,这一差距正在侵蚀用户对AI评测体系的信任。
投资者关注的是基准测试数字,而非模型的实际使用体验。通过在基准测试上刷分,声称以低成本推动前沿,这是一种讨好投资者的策略,但最终伤害的是用户信任。
总结:Claude 4.5 Haiku值得用吗?
Claude 4.5 Haiku的发布暴露了几个关键问题:
- 官方宣传与实际表现严重脱节——号称接近Sonnet 4,实测却远远不及
- 定价策略不合理——性能不如GLM 4.6和GPT-5 Mini,价格却高出数倍
- 产品定位模糊——既不够便宜做轻量任务,又不够强做复杂编码
对于开发者和企业用户来说,目前阶段不建议将Claude 4.5 Haiku作为主力模型。如果需要高性价比的小模型,GLM 4.6和GPT-5 Mini都是更明智的选择。当然,Anthropic可能会在后续进行优化和修复,但就当前版本而言,这确实是一次令人失望的发布。
Anthropic曾经因为"不刷基准测试、注重实际表现"而赢得开发者社区的尊重。如果他们继续在这条路上滑坡,失去的将不仅仅是一个模型的口碑,而是整个品牌的信誉。
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。